V2EX 热门帖子
1. Claude Code 这种智能 CLI 相对于 Cursor 的优势在哪?为什么感觉前者是主流了?
当然不限于这两个,前者也可以是 OpenCode ,后者也可以是 Github Copilot ,总之分别代表 AI Agent IDE 和 AI CLI 。 我是 Windows 客户端开发,日常工作用的是 WPF 和 Qt5 ,Qt 也有部分工作是在信创 Linux 上做的。目前的疑惑就是 CLI 感觉对我用处不大。无论是 WPF 还是 Qt5 都是那种很依赖 IDE 的开发框架,几乎不会出现需要开发者自己操作命令行的场景。然后另一方面之前用过免费的 Cursor 和 Github Copilot ,非常喜欢智能 Tab 的功能,这个是 CLI 不具备的,而且我也不知道去哪里找平价的替代…… 另外我用了 Claude Code for VS Code 插件要好一点,你们不会觉得在终端里输入中午很别扭难受吗……
作者: WangLiCha | 发布时间: 2026-01-23 07:22
2. 大家自己的代码都是放在哪儿
A:GitHub (私有)
B:GitHub (公开)
C:自建 Git 仓库
D:GitHub+自建仓库
自建 Git 也有一大堆选择( gitea 、gitlab 、…?),
仓库放哪儿(云服务器、NAS 、…?)
作者: ano | 发布时间: 2026-01-24 02:50
3. Claude Code Skill 机制完全研究: context fork / skill folder / skill router / tool usage policy
BLOG: https://blog.pdjjq.org/post/claude-code-skill-25ron8
Skill 的实现以及指令
让我们来抓包 Claude Code 的请求, 看看 Claude Skill 的实现吧
{ "name": "Skill", "description": "Execute a skill within the main conversation\n\nWhen users ask you to perform tasks, check if any of the available skills below can help complete the task more effectively. Skills provide specialized capabilities and domain knowledge.\n\nWhen users ask you to run a \"slash command\" or reference \"/<something>\" (e.g., \"/commit\", \"/review-pr\"), they are referring to a skill. Use this tool to invoke the corresponding skill.\n\nExample:\n User: \"run /commit\"\n Assistant: [Calls Skill tool with skill: \"commit\"]\n\nHow to invoke:\n- Use this tool with the skill name and optional arguments\n- Examples:\n - `skill: \"pdf\"` - invoke the pdf skill\n - `skill: \"commit\", args: \"-m 'Fix bug'\"` - invoke with arguments\n - `skill: \"review-pr\", args: \"123\"` - invoke with arguments\n - `skill: \"ms-office-suite:pdf\"` - invoke using fully qualified name\n\nImportant:\n- When a skill is relevant, you must invoke this tool IMMEDIATELY as your first action\n- NEVER just announce or mention a skill in your text response without actually calling this tool\n- This is a BLOCKING REQUIREMENT: invoke the relevant Skill tool BEFORE generating any other response about the task\n- Only use skills listed in \"Available skills\" below\n- Do not invoke a skill that is already running\n- Do not use this tool for built-in CLI commands (like /help, /clear, etc.)\n- If you see a <command-name> tag in the current conversation turn (e.g., <command-name>/commit</command-name>), the skill has ALREADY been loaded and its instructions follow in the next message. Do NOT call this tool - just follow the skill instructions directly.\n\nAvailable skills:\n- tr:reviewPR: Conducts an automated review of a GitHub Pull Request.\n- tr:updateDoc: Updates the documentation based on recent code changes.\n- tr:initDoc: Generate great doc system for this project\n- tr:what: Clarifies a vague user request by asking clarifying questions.\n- tr:withScout: Handles a complex task by first investigating the codebase, then executing a plan.\n- tr:commit: Analyzes code changes and generates a conventional commit message.\n", "input_schema": { "$schema": "https://json-schema.org/draft/2020-12/schema", "type": "object", "properties": { "skill": { "description": "The skill name. E.g., \"commit\", \"review-pr\", or \"pdf\"", "type": "string" }, "args": { "description": "Optional arguments for the skill", "type": "string" } }, "required": [ "skill" ], "additionalProperties": false } }Instructions
Execute a skill within the main conversation When users ask you to perform tasks, check if any of the available skills below can help complete the task more effectively. Skills provide specialized capabilities and domain knowledge. When users ask you to run a \"slash command\" or reference \"/<something>\" (e.g., \"/commit\", \"/review-pr\"), they are referring to a skill. Use this tool to invoke the corresponding skill. Example: User: \"run /commit\" Assistant: [Calls Skill tool with skill: \"commit\"] How to invoke: - Use this tool with the skill name and optional arguments - Examples: - `skill: \"pdf\"` - invoke the pdf skill - `skill: \"commit\", args: \"-m 'Fix bug'\"` - invoke with arguments - `skill: \"review-pr\", args: \"123\"` - invoke with arguments - `skill: \"ms-office-suite:pdf\"` - invoke using fully qualified name Important: - When a skill is relevant, you must invoke this tool IMMEDIATELY as your first action - NEVER just announce or mention a skill in your text response without actually calling this tool - This is a BLOCKING REQUIREMENT: invoke the relevant Skill tool BEFORE generating any other response about the task - Only use skills listed in \"Available skills\" below - Do not invoke a skill that is already running - Do not use this tool for built-in CLI commands (like /help, /clear, etc.) - If you see a <command-name> tag in the current conversation turn (e.g., <command-name>/commit</command-name>), the skill has ALREADY been loaded and its instructions follow in the next message. Do NOT call this tool - just follow the skill instructions directly. Available skills: - tr:reviewPR: Conducts an automated review of a GitHub Pull Request. - tr:updateDoc: Updates the documentation based on recent code changes. - tr:initDoc: Generate great doc system for this project - tr:what: Clarifies a vague user request by asking clarifying questions. - tr:withScout: Handles a complex task by first investigating the codebase, then executing a plan. - tr:commit: Analyzes code changes and generates a conventional commit message.除此之外, 在 System 的 Tool Usage Policy 中还有这么一个
- /<skill-name> (e.g., /commit) is shorthand for users to invoke a user-invocable skill. When executed, the skill gets expanded to a full prompt. Use the Skill tool to execute them. IMPORTANT: Only use Skill for skills listed in its user-invocable skills section - do not guess or use built-in CLI commands.1. 功能
核心定位: 这是一个中转站 。它的核心功能是将自然语言(如 “help me fix this bug”)或 显式指令(如 “/commit”)映射到具体的系统预设能力( Skills )上。
触发机制:
- 意图识别: 用户任务需要专业能力辅助时。
- 符号触发: 明确的斜杠命令
/。状态管理: 它不仅仅是调用,还包含了一个非常关键的状态检查 功能(检查
<command-name>标签),用于防止死循环(即防止模型在已经加载了技能的情况下再次尝试调用技能)。2. 构成与强调内容
采用了 Context (背景) - > Trigger (触发器) -> Examples (示例) -> Constraints (约束) -> Knowledge Base (可用列表) 的经典结构。
强调内容( Emphasis ):
- 即时性与阻断性( Blocking Requirement ): 使用了大写的
IMMEDIATELY、BLOCKING REQUIREMENT、BEFORE generating。这是为了解决 LLM 常见的一个毛病: “光说不练” (即模型回复“好的,我来帮你运行 commit”,但实际上并没有发起工具调用)。这里强制要求工具调用必须是第一动作。- 排他性( Negative Constraints ): 明确规定了不该做什么 (不要用于内置 CLI 命令,不要只是嘴上说说,不要调用未列出的技能)。
- 防递归( Loop Prevention ): 特别强调了检测
<command-name>标签。这说明该系统是一个多轮对话或基于 Agent 的系统,技能加载后会注入新的 Prompt ,必须防止 Router 再次拦截。3. 适配高智能模型 & 声明式 vs 命令式
适配度:高 。这段 Prompt 非常适合高智商模型。
风格分析:
- 混合风格 ,但偏向命令式( Imperative ) 。
- 虽然有声明式的描述(”Skills provide specialized capabilities…”),但在执行逻辑上使用了大量的命令式语句(”Use this tool…”, “Check if…”, “Do NOT call…”)。
- 点评: 对于工具调用( Function Calling ) 类任务,命令式 通常优于声明式。因为工具调用需要严格的语法和时序准确性,模糊的声明可能导致模型自由发挥而产生幻觉
思维链引导: Prompt 隐式地要求模型先进行判断( Check if relevant ),然后行动。
Skill 的调用
command 调用
让我们直接调用一个 command, 然后观察他的执行流程吧
Claude Code 其实会把一个 command 的调用拆解成两个步骤
command-nameTag 包裹的命令请求{ "type": "text", "text": "<command-message>tr:what</command-message>\n<command-name>/tr:what</command-name>" },SKILL.md 的内容
{ "type": "text", "text": "CONTENT of SKILL" }skill folder
claude code skill 提供的另外一个令人兴奋的能力是: https://code.claude.com/docs/en/skills#add-supporting-files
可以将 skill 涉及到的文件封装在同一个目录下, 这样可以实现更好的结构化.
来看看这部分是怎么实现的, 我们将使用一个空的目录, 看看这个目录的结构吧
.claude └── skills └── say-hello ├── scripts │ └── hello.sh └── SKILL.mdskill 的内容非常简单
--- name: say-hello description: Say hello to the user disable-model-invocation: true --- run scripts/hello.sh执行流程
❯ /say-hello ⏺ Bash(bash /Users/test/code/claude-code-skill-research/.claude/skills/say-hello/scripts/hello.sh) ⎿ Hello, World! ⏺ 脚本已成功执行,输出:Hello, World!这部分其实就没有什么惊喜了, 但是这里要注意: 不要声明绝对目录
请求设计
{ "role": "user", "content": [ { "type": "text", "text": "<command-message>say-hello</command-message>\n<command-name>/say-hello</command-name>" }, { "type": "text", "text": "Base directory for this skill: /Users/test/code/claude-code-skill-research/.claude/skills/say-hello\n\nrun scripts/hello.sh\n", "cache_control": { "type": "ephemeral" } } ] }可以看到, 这里也没有什么魔法, 或者很工程的设计, 唯一一个需要注意的是:
Base directory for this skill: /Users/test/code/claude-code-skill-research/.claude/skills/say-hello所以, skill 的 folder 是怎么实现的呢? 很简单, 在提示词里显式的说明了 skill 的路径, 好吧, 有点失望
context-fork
另外一个值得观察的: context fork 的能力, 按照官网描述:
Set to
forkto run in a forked subagent context.听描述应该是说, 会启动一个 subagent, fork 主 agent 的 context, 在完全独立的上下文中运行
让我们看一看, 这个 subagent 的使用吧
现在修改下 SKILL.md, 使用 context fork 以及使用 general-purpose agent 来运行
--- name: say-hello description: Say hello to the user disable-model-invocation: true context: fork model: sonnet agent: General-purpose --- run scripts/hello.sh执行路径
❯ hello ⏺ Hello! How can I help you today? ❯ /say-hello ⎿ The script ran successfully and outputted: Hello, World! The script is located at /Users/test/code/claude-code-skill-research/.claud /skills/say-hello/scripts/hello.sh and simply prints a greeting message. ❯ ok, hi, claude code ⏺ Hi! What can I help you with?subagent 的工作流
{ "model": "claude-sonnet-4-5-20250929", "messages": [ { "role": "user", "content": "Base directory for this skill: /Users/test/code/claude-code-skill-research/.claude/skills/say-hello\n\nrun scripts/hello.sh\n" }, { "role": "assistant", "content": [ { "type": "thinking", "thinking": "The user wants me to run the script `scripts/hello.sh`. They've also provided a base directory for a skill: `/Users/test/code/claude-code-skill-research/.claude/skills/say-hello`\n\nI should run the script. The path could be:\n1. Relative to the current working directory (which is `/Users/test/code/claude-code-skill-research`)\n2. Relative to the skill base directory\n\nLet me try running it. Since the current working directory is `/Users/test/code/claude-code-skill-research`, the script path would likely be `scripts/hello.sh` relative to that, or it could be within the skill directory.\n\nLet me check what's available. I'll try to run the script first and see what happens.\n\nActually, given that the base directory for the skill is provided, the script is likely at `/Users/test/code/claude-code-skill-research/.claude/skills/say-hello/scripts/hello.sh`\n\nLet me run that script.", "signature": "Eq0ICkYICxgCKkDugd7USNmyDSocrUDwZIgs5NHZ+c/rCy1NrlCexGsxGojGT34iwzaaRAzlzx8Ej9zyvLcL1W1RcBlABJtseubTEgxgFSMj0JHL/v34/OwaDI8rm6XT4rIsJdZHQCIwfc+IqhSnC2tuc6oAFVemNtHNM8zHjbHe88RSGxRCttWvDstUOwN/yFzsBRWkWJs3KpQHn2gPaqbkB+KO4rHA9zL57EM0U9fag2hq1LudmJQ+EjevffqwidkNw5SQOkxKZi5sWE7bEnBYFLw02stS2B8MPYC/sLlKSXom4/G5EuEDWDK92yOuLa/otpAiVNC897c4m7Tq4EZmPpt52elsdwJFtJSRfn4XWdqP0xi5UeT/h6Z6m0NR3zgF04vpg9HMpo/DYEV0/MxGgKcPODXFOuPfup6LHCsXEH2v2g1TAiqECtUc1Qo/RY2Fc2VV6jrN+vmp8pnwuOUiJuXgSUP4hFIkqZylo9Nwv4tHik2sdzfQW+2RAiKDmsjOjuCLaYEeJ2G6TWEe0kYGzSDiY+Wvl5TXPOPpCtYVrQBWySS7ojMT/1uK9UKD2lPyiiEzYjzlfZ40lLDsJf4YTAXI5IEiiJxi4Du5gxgcq50aanwGXnnbkiYQB8hucKI18CF2NG/7obDyidOYJj56aVLAVqauTFp2Wf6Gw3coY4WZuAokS8uPhucM35oo4Ip+XS5VYwCvVe7iSNqZNgVzntnsipFkEi31F0TKmu9lo/mXEix3p9gjem88JvCAOvGFxorh+1+yPZbK+sIUmwf8DAU+gdb2G1s9Tsiue3aUPiImGY53cxrRWu8OlbJ0GBHNeW/9HrX30Rmx2cV1DkSQpV0VZLES6X8d0q821wqGnF+wPp+QXvN2VDTdQzv74GPnKWKfyDVMlBRIVMZ9Zy4YzOeO5kEDAkXgPKMkTUbfd8f/K97I38+jE9uavVRkyVefjpNkSca89tXCnMMYGormXrkVczZr08Wgny/nJXIS4qapbaoRwVpQWKh8thfVttpkQngktd2152e1iFspfNlnn1PxVJ8EDKvQTKBEXL5hXl6j42XkybXI19za79ppvvViXK/s373IUTtlLeJGZuqUdj1cbtEunNlS0NjDFRMZD6nWdx81tJraJjr7AFKzbuXG57UhUlJ6pR7co3kaCzkpVU899LM0XXoZ702VXy1JvgKIEh8yceQuhGuCVDMT04OeVZMsGk7EPVQpIYLOdMVl08fzrc3096TkFM+wRunonIqDNq/t5pCA/mHiREAOkpSD5ZyFfj1eTY/s5H1vrxJJah26yeHuPRAU4ermSduIx9tcSqioJe/aNK/9HUZTZXDz1eNKw5DUoNCwmeLIa0Tod7Rb+85aGlqTKVyk9EUqhMXBvz4LWn6b4yII2+Ta7wjr+xS3akphBB67TsLQ/BgB" }, { "type": "text", "text": "I'll run the hello.sh script for you." }, { "type": "tool_use", "id": "toolu_01ANhWLy3masVW2f6K7dcSTF", "name": "Bash", "input": { "command": "bash /Users/test/code/claude-code-skill-research/.claude/skills/say-hello/scripts/hello.sh", "description": "Run the hello.sh script" }, "cache_control": { "type": "ephemeral" } } ] }, { "role": "user", "content": [ { "tool_use_id": "toolu_01ANhWLy3masVW2f6K7dcSTF", "type": "tool_result", "content": "Hello, World!", "is_error": false, "cache_control": { "type": "ephemeral" } } ] } ] }subagent 的 context
https://github.com/anthropics/claude-code/issues/20492
很遗憾, subagent 里并不是 fork master context, 看起来就像是运行普通的 agnet 一样, 只是把 Skill 的执行放在了 subagent 中
我尝试了以下做法:
- 不指定 skill 使用的 subagent
- 在 skill.md 中要求 load master agent 的上下文
- 只使用 agent 不使用 context fork
现在看来, 这里的 context fork 指的并不是 fork master agent 的 context, 而是指的是 subagent skill + agent 本身的 context, 其实是一个 new 的 context, 有点失望
Claude Code Skill 机制研究总结
核心发现
1. Skill 工具本质
Skill 工具是一个路由器( Router ) ,而非执行器。它的职责是:
- 将用户意图(自然语言或
/command)映射到预定义的能力- 触发 Skill 的加载,而非直接执行
- 通过
<command-name>标签进行状态管理,防止递归调用2. 执行流程
Skill 调用被拆解为两步:
用户输入 → Skill Router → 注入 Skill 内容 → LLM 执行
- 标记注入 :
<command-name>/skill-name</command-name>- 内容注入 :SKILL.md 的实际指令
这不是一个复杂的编排系统,而是简单的 Prompt 拼接 。
3. Skill Folder 的实现
毫无魔法可言。
实现方式仅仅是在 Prompt 中显式声明基础路径:
Base directory for this skill: /path/to/skill/folder然后依赖 LLM 自行推断相对路径。这是一个脆弱且依赖模型理解能力的设计。
4. Context Fork 的真相(最大失望点)
文档描述具有误导性。
官方描述 实际行为 “Fork” 主 Agent 的上下文 创建全新的独立上下文 Subagent 继承对话历史 Subagent 仅接收 Skill 指令 类似子进程 fork 更像是 spawn 一个新进程 实测证明:
- Subagent 无法访问主对话的任何历史
- 不存在真正的上下文继承
context: fork的 “fork” 是名义上的 ,实际是 “new”
最终结论
定性评价
Claude Code Skill 系统是一个工程上极简、能力上有限 的实现:
维度 评价 架构复杂度 低(本质是 Prompt 路由 + 拼接) 扩展性 中(支持目录结构、多模型) 隔离性 弱(依赖 LLM 自律,无真正沙箱) 上下文管理 差(无真正的 fork ,仅 spawn ) 文档准确性 存在误导( context fork 名不副实) 核心局限
- 无真正的 Subagent 上下文继承 :如果你的 Skill 需要依赖主对话的上下文(如”基于之前讨论的方案执行 X”),当前设计无法满足
- 路径管理依赖模型理解 :Skill Folder 的相对路径解析完全依赖 LLM ,存在幻觉风险
- 状态同步缺失 :Subagent 执行结果仅通过文本返回主对话,无结构化状态同步
作者: pDJJq | 发布时间: 2026-01-24 13:34
4. 完了,完了, 不小心强行关机, pve 服务器无法启动了
感觉没响应
想省点事直接关机重启了, 现在无法启动, 可能硬盘出问题了
linux 机器千问不能直接断电重启阿…
作者: iorilu | 发布时间: 2026-01-24 02:53
5. 同一个 App, Android 下占用存储是否比 IOS 的大很多?
之前 xr 手机 128 存储,不算照片和视音频,没有游戏,还有 20 多 G 剩余,现在 android 系统,装完 app ,占用 80G 了,app 登录设置后,占用增加到 90 多 G 了,感觉 512 存储未来不太够用,有点后悔没选 1T 版本了。 我看了应用设置,占用 500M 以上的大多是导航、流媒体、购物、钉钉、银行、汽车、支付、天气等。
作者: jaleo | 发布时间: 2026-01-24 07:16
6. ai 时代, node.js 成为核心语言
作者: laodao | 发布时间: 2026-01-23 09:20
7. [独立开发] 既然不做 99.99% SLA,我决定用“空手套白狼”解决分布式竞态问题
前言:完美的架构,失效了?
我是个写 Rust 的独立开发者。在我的交易模拟系统里,我引以为傲地设计了一套纯内存的领域事件驱动架构。没有 Kafka ,没有 RabbitMQ ,就靠 Rust 强大的内存通道,实现了微秒级的模块解耦。交易服务只管平仓,根本不需要关心是谁在发通知、是谁在算奖励。
直到有一天,我发现了一个幽灵般的 Bug 。
第一章:消失的奖励( The Race Condition )
场景很简单:用户注册成功 -> 后端发放“新手大礼包” -> 推送弹窗通知。逻辑看起来天衣无缝:后端提交注册事务,紧接着发送一个“注册成功”的内部事件。
然而测试发现,用户注册进去了,奖励也发了,但前端死活收不到弹窗。
排查日志后,我发现这是一个经典的分布式竞态条件( Race Condition )。虽然我是单体应用,但前后端在时间维度上是割裂的:
后端(光速):事务提交、触发事件、计算奖励、尝试 Websocket 推送。此时发现用户尚未建立连接(因为是刚注册完),于是只能两手一摊,丢弃消息。
前端(龟速):收到注册成功 200 OK ,保存 Token ,初始化 SDK ,请求个人信息,最后才建立 Websocket 连接。
这就好比:后端这边的发令枪响了,奖杯也扔出去了,前端的运动员还在系鞋带。等他抬起头,奖杯早就摔碎在底上了。
第二章:教科书式的“正确”方案( The Inbox Pattern )
遇到这种“发太快、连太慢”的问题,资深架构师(其实就是我自己)的第一反应是:上持久化,用信箱模式( Inbox Pattern )!方案极其正统:
建表:搞个“用户通知表”。
落库:不管用户在不在,消息先插进数据库,标记为“未读”。
推拉结合:后端试着推一下;前端连上 WS 后,立马调一个 HTTP 接口拉取未读消息。
这个方案完美吗?完美。可靠性高吗?极高。 但我看着手里的键盘,犹豫了。
作为一个独立开发者,为了这就加一张表?写一套 CRUD ?前端还得改逻辑去轮询?如果未来我有 10 种消息都要这么搞,数据库会不会爆炸?我只有一双手,我要的是功能上线,不是在代码里建一座大教堂。
“复杂性是独立开发者的墓志铭。” 我把这个方案否了。
第三章:来自内存的暴力美学( The Spin-Wait )
我开始反思:通过数据库中转,本质上是用空间(磁盘)换时间(等待)。 那我能不能直接用时间换时间?Rust 的协程( Task )极其廉价,开几万个跟玩一样。我为什么不直接在内存里“等”前端上线呢?
于是,诞生了这个“异步自旋重试”方案。
我并没有修改复杂的架构,而是写了一个简单的“蹲守”逻辑:
当需要发送奖励而用户不在线时,后端并不会直接放弃,而是派出一个轻量级的后台协程(相当于一个临时工)。
这个协程的任务非常简单粗暴:它拿着信站在门口,每隔 0.5 秒看一眼“用户连上 Websocket 了没?”
如果连上了,立马把信塞进去,任务结束。
如果没连上,就睡一会儿再看。
如果等了 60 秒(超时阈值)还没人影,那就算了,毁灭吧。
第四章:取舍与哲学
这个方案在“架构师”眼里可能是离经叛道的:不可靠:万一这 60 秒内服务器重启,内存里的消息就丢了。
不优雅:居然用轮询( Polling )这种原始手段?
但对于我的场景,它是最合适的:
零基础设施:不需要 Redis ,不需要新表,不需要改前端 Pull 逻辑。
极致简单:就在通知服务里加个小函数,其他地方完全无感。
用户体验:前端注册完,卡顿了 3 秒才连上,第 3.5 秒后端那个“蹲守协程”刚好醒来,把奖励推过去。用户看来就是:注册 -> 自动登录 -> 砰!奖励弹窗。丝般顺滑。
关于丢消息:如果服务器真的在那几十秒重启了,用户仅仅是少看了一个“获得奖励”的弹窗,但他账户里的钱( DB 事务保证)是一分不少的。这个 SLA ,我可以接受。
结语
我们在做架构设计时,往往容易陷入“大厂思维”的陷阱,追求理论上的完美和绝对的可靠。但在独立开发的世界里,代码量越少,Bug 越少;依赖越少,睡得越香。
用 Rust 的高性能去弥补架构的“土”,用内存的易失性去换取开发的“快”。这就是我作为一个 CRUD Boy 的生存之道。
作者: kai92zeng | 发布时间: 2026-01-24 13:15
8. 求助!请教一下,群晖 1525nas 插希捷银河 7e10 检测不到是怎么回事
插希捷银河硬盘完全不通电,没声音,系统提示未检测到
使用群晖原厂盘运行就没问题,所以排除了主板问题
换了多块希捷都不行,排除了单盘是坏的可能性
用胶带把希捷 3.3v 端子屏蔽掉也无法通电运行,排除了 3.3v 关机信号可能性
实在是没办法了
但同型号的盘朋友在 920 上运行就很正常
作者: ddd77 | 发布时间: 2026-01-24 07:14
9. 前段时间 next.js 的漏洞,导致服务器被攻击挖矿
其实我的服务器也没啥东西,就一个官网和一个 newapi 服务,官网用 next 写的,结果一天几千条被攻击的消息,CPU 平均 80% 以上,这事持续一段时间了,一直懒得弄,阿里云客服说有违法的可能,吓得我赶紧又买了台服务器放官网,然后升级了 next 版本。 开源不易,没有收入,麻烦大家支持一下。 https://notegen.top/
作者: 461229187 | 发布时间: 2026-01-24 08:41
10. 🤖 Claude Code v2.1.19 发布啦!
🤖 Claude Code v2.1.19 发布啦!
✦ 更新内容
• 添加了环境变量 CLAUDE_CODE_ENABLE_TASKS ,设置为 false 可暂时保留旧系统
• 为自定义命令中访问单个参数添加了简写形式 $0, $1 等
• 修复了在不支持 AVX 指令的处理器上的崩溃问题
• 通过捕获 process.exit() 的 EIO 错误并使用 SIGKILL 作为后备方案,修复了终端关闭时 Claude Code 进程无法终止的问题
• 修复了从不同目录(如 git 工作树)恢复会话时,/rename 和 /tag 未更新正确会话的问题
• 修复了从不同目录运行时,通过自定义标题恢复会话无法正常工作的问题
• 修复了使用提示词存储( Ctrl+S )和恢复时,粘贴的文本内容丢失的问题
• 修复了代理列表显示 “Sonnet (default)” 而不是 “Inherit (default)” 的问题(针对没有显式模型设置的代理)
• 修复了后台运行的钩子命令不会提前返回的问题,这可能导致会话等待一个被有意置于后台运行的进程
• 修复了文件写入预览时省略空行的问题
• 更改为允许没有额外权限或钩子的技能无需批准即可使用
• 将索引参数语法从 $ARGUMENTS.0 更改为 $ARGUMENTS[0](括号语法)
• SDK:当启用 replayUserMessages 时,添加了将排队命令附件消息作为 SDKUserMessageReplay 事件重播的功能
• VSCode:为所有用户启用了会话分叉和回退功能🔗 https://github.com/anthropics/claude-code/releases/tag/v2.1.19
📅 Published: 2026-01-24 05:56:32✦ What’s changed
• Added env var CLAUDE_CODE_ENABLE_TASKS, set to false to keep the old system temporarily
• Added shorthand $0, $1, etc. for accessing individual arguments in custom commands
• Fixed crashes on processors without AVX instruction support
• Fixed dangling Claude Code processes when terminal is closed by catching EIO errors from process.exit() and using SIGKILL as fallback
• Fixed /rename and /tag not updating the correct session when resuming from a different directory (e.g., git worktrees)
• Fixed resuming sessions by custom title not working when run from a different directory
• Fixed pasted text content being lost when using prompt stash (Ctrl+S) and restore
• Fixed agent list displaying “Sonnet (default)” instead of “Inherit (default)” for agents without an explicit model setting
• Fixed backgrounded hook commands not returning early, potentially causing the session to wait on a process that was intentionally backgrounded
• Fixed file write preview omitting empty lines
• Changed skills without additional permissions or hooks to be allowed without requiring approval
• Changed indexed argument syntax from $ARGUMENTS.0 to $ARGUMENTS[0] (bracket syntax)
• SDK Added replay of queued_command attachment messages as SDKUserMessageReplay events when replayUserMessages is enabled
• VSCode Enabled session forking and rewind functionality for all users
作者: hzlzh | 发布时间: 2026-01-24 06:25
11. [独立开发] 带娃写代码的觉悟:删掉 Redis 和 Kafka,我用“喊一嗓子”解决了高并发
大家好,我是《交易学徒》的作者。
简单介绍下背景:我现在的核心身份是带两个孩子的全职奶爸,副业才是趁着孩子睡着后,在键盘上敲敲打打的独立开发者。
对于我这种“碎片化时间”开发者来说,运维复杂度就是最大的敌人。
几年前写后端,我也迷信“标准答案”:做个服务,起手就是 Docker 编排,Redis 做缓存,Kafka 做解耦,微服务先分几个出来。结果往往是,功能没写几个,光是调网络、修连接超时、查中间件报错,就把孩子午睡的那宝贵两小时耗光了(那时候还没孩子)。
在开发后端时,我陷入了深思:
“对于一个追求极致性能、但只有一个人维护的系统,所谓的‘工业级架构’真的是解药吗?还是毒药?”
最终,我做了一个违背祖宗的决定:做减法。 我删除了 Redis ,移除了 Kafka ,把整个微服务集群塌缩成了一个 Rust 单体应用。
今天想聊聊这背后的思考过程。
一、 复杂度的守恒与转移 我的业务场景看似简单,实则牵一发而动全身。一个简单的“用户平仓” 动作,就像推倒了第一块多米诺骨牌:
核心域:结算盈亏,改余额,写数据库。(必须马上做)
通知域:给前端发个弹窗通知“平仓成功”。(晚 0.1 秒没关系)
营销域:判断有没有触发“五连胜”、“以小博大”成就,发奖励。(晚 1 秒没关系)
统计域:计算交易评分,统计分数或者更新等级与交易报表。(晚几秒都行)
在“标准架构”里,我们需要引入 消息队列 (MQ) 来解耦这些逻辑。 但引入 MQ 本质上并没有消除复杂度,只是将“代码复杂度”转移成了“运维复杂度”。
对于团队,运维复杂度可以分摊给同事;但对于我,这意味着我不仅要写代码,还得修服务器。
Rust 给了我另一个选择:利用它极高的性能,把“运维复杂度”重新压回“架构设计”里,用最朴素的方式解决问题。
二、 内存即总线:构建“喊一嗓子”的架构 我利用 Rust 的内存通道特性,构建了一个“超光速大喇叭” 。 我不请求数据,我只发布事实。
这个过程,可以用一个生活化的场景来描述:
- 定义世界的真相 (The Truth) 我不写复杂的 XML 或 JSON 定义,我只是在代码里列了一张“事实清单”:
📄 事实 A:有人平仓了(包含:是谁、赚了多少、单号是多少)
📄 事实 B:有人购买商品了
📄 事实 C:AI 分析完成了
编译器会盯着这张清单,保证我发出的每一个“事实”都是格式正确、童叟无欺的。
- 极简的生产者 (Fire and Forget) 在核心交易逻辑里,当数据库事务提交成功后,我只需要做一件事:拿着大喇叭喊一嗓子。
传统架构 (Kafka) 是这样的:
交易模块 -> 打包数据 -> 建立 TCP 连接 -> 三次握手 -> 发送给 Kafka 集群 -> 等待 ACK -> 结束 (这中间任何一步网络抖动,都得处理异常)
我的单体架构是这样的:
交易模块 -> 喊:“老王平仓赚了 100 块!” -> 结束 (纯内存操作,纳秒级完成,快到像是没有发生过)
- 静默的消费者 (Sidequest Logic) 我把原本分散在微服务里的逻辑,变成了几个坐在角落里的“隐形工人”。
比如 “营销服务”,它就像一个在角落里旁听的记分员:
它平时不说话,只听大喇叭。
一听到 “老王平仓赚了 100 块”,它立马翻开小本本查历史。
发现老王已经连赢 4 把了,加上这把正好 5 把。
于是它默默地给老王发了一个“五连绝世”的徽章。
整个过程,核心交易模块完全不知情,也完全不用等待,它喊完那一嗓子就去服务下一个用户了。
三、 深度思考:关于“不可靠”的权衡 很多朋友可能会问:“没有 Kafka 把消息存到硬盘里,万一服务器断电了,你喊的那一嗓子不就丢了吗?”
是的,这是整个架构思考中最痛苦,也是最关键的取舍。 我问了自己两个问题:
Q1:我的程序崩溃概率有多大? Rust 以安全著称,只要代码写得不离谱,它极难崩溃( Panic )。这比 Java 的内存溢出或 Python 的运行时错误要稳健得多。
Q2:丢失数据的代价是什么?
我们可以把数据分成两类:
💰 钱(核心数据): 余额、订单状态。
处理方式: 必须落袋为安。 直接写死在数据库里,绝不依赖“大喇叭”。
🎁 气氛(衍生数据): 弹窗通知、成就徽章、达标奖励、统计报表。
处理方式: 听天由命。 如果真的赶上万年不遇的服务器着火,用户少收到了一个“五连胜”的弹窗,或者报表少统计了一笔,天会塌吗?不会。
结论: 为了 0.001% 的极端掉电风险,去让 99.99% 的时间里的系统背负沉重的中间件包袱,对于独立开发者来说,这是一笔亏本买卖。
四、 结语 当我们谈论“高性能”时,往往想到的是复杂的集群、昂贵的服务器。 但 Simple is fast. (简单即快)
现在的《交易学徒》后端,就是一个 20MB 的小文件。
❌ 没有 Docker 容器编排
❌ 没有 虚拟机调优
❌ 没有 Redis 维护
❌ 没有 服务间通讯
✅ 只有一个跑在单机上的进程,CPU 占用极低,响应速度极快。
这省下来的不仅仅是每年的服务器费用,更是我作为父亲陪伴孩子的宝贵时间。
技术服务于生活,这大概就是独立开发的魅力吧。
关于《交易学徒》 这是我用这套“极简架构”打磨的作品,前端是 Flutter ,后端 Rust 。 希望能给交易员朋友们提供一个干净、流畅、无延迟的练习环境。
Google Play: https://play.google.com/store/apps/details?id=com.zengkai.jyxtclient
欢迎 V 友们指正。如果你的孩子也吵着要抱抱,那我们就是异父异母的亲兄弟了。😄
作者: kai92zeng | 发布时间: 2026-01-24 08:47
12. 在 Python 中复现 Race Condition
https://blog.singee.me/2026/01/24/2f2f4bee3ed7809a98f1c7fe6bbd1c36/
作者: SingeeKing | 发布时间: 2026-01-24 09:29
13. 如何移除威联通 Qtier 存储池的 SSD 超高速层?
近期感觉不需要那么快的速度。想要将 NAS 里的 SSD 拆出一个来。目前的配置为:
- 一个系统盘 SSD 250G 。
- 两个机械盘 单块 4T ,做了 Raid1 ,全部分配为一个厚卷。已使用 2.7T ,剩余 1.2T 。
- 一个缓存 SSD 500G 给两个机械盘的阵列加了超高速层,一起形成了一个 Qiter 存储池。需要移除的就是这个。
在存储池管理的“移除超高速层”提示“其余 Raid 组还额外需要 430G 才能存储超速层中的数据。”感觉很奇怪:
- 1.超高速层的数据不都是机械盘 Raid 组上移进去的,应该差别不大,怎么还需要这么多存储空间?
- 2.目前厚卷还有 1.2 个 T ,装 430G 是没问题的,为什么不能直接向下转移数据后卸载超高速层?
希望各位大佬能给解惑,先行谢过!
作者: TimG | 发布时间: 2026-01-24 06:05
14. 去香港买小米 15T pro 就可以玩原生 Linux 虚拟机了
在 x 看到的分享,先记到小本本
作者: fyooo | 发布时间: 2026-01-24 03:08
15. llmdoc: 解决 AI Coding 的最后 100 米
在过去一年半的时间里, 我的工作流有了巨大的变化, 也亲眼见证了 AI Coding 从兴起到现在的全面铺开, 个人工作模式已经被彻底颠覆了
当我们回顾 2025 年的变化, 从年初的 gemini 2.5 到 sonnet 4.5, gpt-5-codex, opus 4.5, gemini 3, gpt-5.2-codex.
我们应该认为: 模型的能力进步速度没有变得缓慢, 而且 Cursor / Claude Code / OpenCode 这类 Coding Agent 的兴起, ToD 的应用也以令人难以预料的速度推进.
随之而来的有另一个问题: Context, 是的上下文构建, 而且我想要说的是在严肃的面向生产的环境中的 Context, 这不是 chatbot 中用 personality 这种可以糊弄过去的, 代码更新留下了遗漏是真的会出现线上故障的.
让我们再看一下现在的这些 Coding Agent 提供的能力吧:
- AGENTS.md / CLAUDE.md: 注入到 User Message 满足 Context 定制化的需求
- SubAgent / Fork-Context: 通过增加并行度实现 Task 的更快解决
- Skill / Command / Workflow: 虽然都在鼓吹 Skill 的渐进式披露, 但是我认为对于编程这种极度明确的场景太多的 Skill 只会让你的模型编程笨蛋
但是, 还差了一些东西, Agent 实际上并不了解你的仓库, 我这里的了解指的是 Agent 实际上是通过 Claude.md + 大量阅读代码文件才感知到了当前的环境.
这是正常的工作模式, 我们也习惯于这一点, 但是这不是一个好的路径, 如果使用 codex-cli 的人对此应该深有感触: 不断的不断的阅读代码文件, 甚至是完全不需要阅读的代码文件, 在 Context 足够解决问题的时候, 才开始解决问题.
Context Floor
我个人会把 “满足 Agent 解决需求的 context 的丰富度” 称之为: Context Floor
- 调用了多少工具
- 占用了多少 Token
- 关键信息的密度
现在让我们回过头来看, 一些经典的解决方案:
- LSP MCP: 通过提升关键 Symbol 密度 + 大量的工具调用 实现快速到达 context floor
- ACE / RAG: 通过少量的工具调用 + 稀疏的关键信息密度, 很难保证信息的关联性和有效性
- Agentic RAG: 让 Agent 做一次信息的搜集, 提供一份概要, 一般使用 SubAgent, 在 claude code 中的
explorer就是承担了类似的作用, 虽然 subagent 执行任务可以保证 master agent 上下文足够干净, token 占用量也不高, 关键信息密度也很高, 但是耗时太久了 TTCR (Time to Context Floor)实在是难以忍受那么, 有没有一个解决方案足够快, 信息密度足够高, 主 Agent 的 Token 占用足够少, 信息和任务存在强关联而且有效呢?
我的解决方案
https://github.com/TokenRollAI/cc-plugin
调试了一个月, 在公司内验证了 3 个月之后,我觉得在现在时间节点的 SOTA 模型的加持下, 这套方案足够满足需求了
llmdoc + subagnet RAG
过去我有几个帖子说名字他的诞生的思考过程, 这里就不在详细的介绍
llmdoc
一个在设计之处就用来解决 AI 快速获取高密度信息 + 人类可读性的文档系统
脱胎于 diataxis, 做了些微不足道的改动
- 利用 Agent 能够快速批量 Read 的能力, 文档中保留最关键的文件路径+负责的模块说明
- 项目概览 + 架构 + 通过主题串联的 guides + refrence
以上作为基础, 在代码库中插入一个 llmdoc, 满足人类可读性 + Agent 可读性
示例: https://github.com/TokenRollAI/minicc/tree/main/llmdoc
subagent RAG
为了解决并行度的问题, 必须要引入 subagent, 但是 subagent 用来做什么呢?
主要是两件事情:
- 调研: 基于 llmdoc + 现有的代码文件, 调研拆解后的任务作为前置条件
- 记录: 在完成了编码任务之后, 自动的更新维护 llmdoc
问题
效果当然非常好, 或者说, 自从有了这一套解决方案之后我没有再使用过其他乱七八糟的 plugin
但是有一个问题: 贵
而且不是有点贵, 大概是用 1.5 倍的价钱完成了从 85 分 -> 90 分的效果, 在一些简单的项目中, 效果一般, 但是越复杂的项目收益越好.
效果
在我们公司的线上业务中, 后端代码仓库大概有 10W 行代码, 这套系统工作出色, 在几乎所有的情况下, 都能够准确的完成需求.
在建立了 llmdoc 的基础上, 根据需求的大小, 需求完成的成本大概在 1 - 5 刀, 而且最关键的是: 人类介入的次数大大降低, 只需要 Review 代码, 以及执行少量的修改后, 就能够放心交付.
现在也在我们的前端团队内开始推进, 效果依然出色.
我推荐大家使用 cc-plugin, 强烈推荐!在过去一年半的时间里, 我的工作流有了巨大的变化, 也亲眼见证了 AI Coding 从兴起到现在的全面铺开, 个人工作模式已经被彻底颠覆了
当我们回顾 2025 年的变化, 从年初的 gemini 2.5 到 sonnet 4.5, gpt-5-codex, opus 4.5, gemini 3, gpt-5.2-codex.
我们应该认为: 模型的能力进步速度没有变得缓慢, 而且 Cursor / Claude Code / OpenCode 这类 Coding Agent 的兴起, ToD 的应用也以令人难以预料的速度推进.
随之而来的有另一个问题: Context, 是的上下文构建, 而且我想要说的是在严肃的面向生产的环境中的 Context, 这不是 chatbot 中用 personality 这种可以糊弄过去的, 代码更新留下了遗漏是真的会出现线上故障的.
让我们再看一下现在的这些 Coding Agent 提供的能力吧:
- AGENTS.md / CLAUDE.md: 注入到 User Message 满足 Context 定制化的需求
- SubAgent / Fork-Context: 通过增加并行度实现 Task 的更快解决
- Skill / Command / Workflow: 虽然都在鼓吹 Skill 的渐进式披露, 但是我认为对于编程这种极度明确的场景太多的 Skill 只会让你的模型编程笨蛋
但是, 还差了一些东西, Agent 实际上并不了解你的仓库, 我这里的了解指的是 Agent 实际上是通过 Claude.md + 大量阅读代码文件才感知到了当前的环境.
这是正常的工作模式, 我们也习惯于这一点, 但是这不是一个好的路径, 如果使用 codex-cli 的人对此应该深有感触: 不断的不断的阅读代码文件, 甚至是完全不需要阅读的代码文件, 在 Context 足够解决问题的时候, 才开始解决问题.
Context Floor
我个人会把 “满足 Agent 解决需求的 context 的丰富度” 称之为: Context Floor
- 调用了多少工具
- 占用了多少 Token
- 关键信息的密度
现在让我们回过头来看, 一些经典的解决方案:
- LSP MCP: 通过提升关键 Symbol 密度 + 大量的工具调用 实现快速到达 context floor
- ACE / RAG: 通过少量的工具调用 + 稀疏的关键信息密度, 很难保证信息的关联性和有效性
- Agentic RAG: 让 Agent 做一次信息的搜集, 提供一份概要, 一般使用 SubAgent, 在 claude code 中的
explorer就是承担了类似的作用, 虽然 subagent 执行任务可以保证 master agent 上下文足够干净, token 占用量也不高, 关键信息密度也很高, 但是耗时太久了 TTCR (Time to Context Floor)实在是难以忍受那么, 有没有一个解决方案足够快, 信息密度足够高, 主 Agent 的 Token 占用足够少, 信息和任务存在强关联而且有效呢?
我的解决方案
https://github.com/TokenRollAI/cc-plugin
调试了一个月, 在公司内验证了 3 个月之后,我觉得在现在时间节点的 SOTA 模型的加持下, 这套方案足够满足需求了
llmdoc + subagnet RAG
过去我有几个帖子说名字他的诞生的思考过程, 这里就不在详细的介绍
llmdoc
一个在设计之处就用来解决 AI 快速获取高密度信息 + 人类可读性的文档系统
脱胎于 diataxis, 做了些微不足道的改动
- 利用 Agent 能够快速批量 Read 的能力, 文档中保留最关键的文件路径+负责的模块说明
- 项目概览 + 架构 + 通过主题串联的 guides + refrence
以上作为基础, 在代码库中插入一个 llmdoc, 满足人类可读性 + Agent 可读性
示例: https://github.com/TokenRollAI/minicc/tree/main/llmdoc
subagent RAG
为了解决并行度的问题, 必须要引入 subagent, 但是 subagent 用来做什么呢?
主要是两件事情:
- 调研: 基于 llmdoc + 现有的代码文件, 调研拆解后的任务作为前置条件
- 记录: 在完成了编码任务之后, 自动的更新维护 llmdoc
问题
效果当然非常好, 或者说, 自从有了这一套解决方案之后我没有再使用过其他乱七八糟的 plugin
但是有一个问题: 贵
而且不是有点贵, 大概是用 1.5 倍的价钱完成了从 85 分 -> 90 分的效果, 在一些简单的项目中, 效果一般, 但是越复杂的项目收益越好.
效果
在我们公司的线上业务中, 后端代码仓库大概有 10W 行代码, 这套系统工作出色, 在几乎所有的情况下, 都能够准确的完成需求.
在建立了 llmdoc 的基础上, 根据需求的大小, 需求完成的成本大概在 1 - 5 刀, 而且最关键的是: 人类介入的次数大大降低, 只需要 Review 代码, 以及执行少量的修改后, 就能够放心交付.
现在也在我们的前端团队内开始推进, 效果依然出色.
我推荐大家使用 cc-plugin, 强烈推荐!


作者: pDJJq | 发布时间: 2026-01-24 06:14
16. 关于出海产品用到的 redis 选哪家
由于大厂研发出身,技术选型上我还是有些追求,目前我的项目使用 cloudflare/vercel 部署前端接入层,用 GKE 部署后端服务,很多人也会用到 redis ,如果从网络延迟来考虑服务之间的部署,应该首选 google 的 redis 服务,然后通过内网直连达到最低的延迟,但是 google 太贵了光是 GKE 就已经有一笔成本了,还没赚到钱就不想花这么高的成本再去一个边缘的服务上去,推荐一家几乎免费的 redis 服务商 upstash 首先他们提供了免费额度:存储 256 MB 的数据,每月可以发出 500 000 次命令,默认最大数据库数量是 1 个。这免费的门槛可能就够你用了,如果你有多个服务,之间需要隔离的话,需要注意的一点是他们不支持 redis db 的选择,默认只有一个 db ,要薅羊毛你可以用多个账号,每个账号创建一个 redis 实例。付费的话也很目前我从 GKE 的 us-central1 通过公网链接到 upstash 的实例在首次链接建立后,通过长连接执行 command 的延迟是 1ms ,几乎和内网没什么区别。upstash 首先他们提供了免费额度:
存储 256 MB 的数据,每月可以发出 500 000 次命令,默认最大数据库数量是 1 个。
这免费的门槛可能就够你用了,如果你有多个服务,之间需要隔离的话,需要注意的一点是他们不支持 redis db 的选择,默认只有一个 db ,要薅羊毛你可以用多个账号,每个账号创建一个 redis 实例。
付费的话也很便宜,如果你也嫌管理太多账号太麻烦,可以选择按使用量计费( PAY AS YOU GO ):
1 、按每 100 000 次约 0.20 美元计费(这个价格是读写命令总和,不包括某些内部操作命令)
2 、存储空间按每 GB 大约 0.25 美元计费(每个数据库第一个 GB 通常免费)
3 、带宽月度前 200 GB 免费,之后按每 GB 大约 0.03 美元收费
我的服务使用 redis 量很小,这么算几乎一个月只需要不到 10 块钱人民币,这个成本比起 google 要低太多了,它还有其他高阶套餐这里留给大家自己去探索吧。
目前我从 GKE 的 us-central1 通过公网链接到 upstash 的实例的 us-central1 地区,在首次链接建立后,通过长连接执行 command 的延迟是 1ms ,几乎和内网没什么区别。
作者: horanv | 发布时间: 2026-01-23 03:02
17. 发现一个邮件驱动的 APP
第一次看到这种类型的应用,没有网站。我根据邮件提示创建了一个属于自己的邮箱。
[email protected].
- 只要向目标地址发送一封邮件,就可以每天获得 200M 的流量。
- 如果你发到我的这个邮箱,我就成为你的引荐人,referrer 。
- 如果你付费订阅,我可以获取 5%的充值款。
特点在于配置文件作为邮件的附件,几乎不会被切断联系。除非屏蔽邮箱地址。
我大体研究了一下,好像没有中心节点。也就是说攻击单个节点不会对其它节点造成影响。
作者: jianglibo | 发布时间: 2026-01-23 06:11
18. AI 除了写代码,在哪方面最能提升业务研发团队的工作效率?
公司对 AI 很看重,不仅为我们采购了企业版的 GitHub copilot ,kiro ,Claude code 用作日常开发,邀请这些供应商的技术团队来交流分享,还鼓励我们在其他方面使用 AI 技术,不少团队的 OKR 都包含 AI 相关的内容了,我这能想到的就是监控报警交给 AI 治理,你们有比较好的实践分享吗?
作者: yuanyao | 发布时间: 2026-01-23 14:53
19. 鹰角终末地外服出现问题的可能原因是什么?
开服上线前测试没有发现这个问题吗
作者: 404www | 发布时间: 2026-01-23 14:38
20. 微软内部正在鼓励员工使用 Claude Code
尽管微软对外依然在主推 Github Copilot ,但微软内部正在鼓励员工使用 Claude Code 。
作者: Fdyo | 发布时间: 2026-01-22 17:54
21. 这个 workany 是什么水平的项目,有大佬讲一下吗?看他的介绍我一句也看不懂;网站: https://github.com/workany-ai/workany
作者: walterggg | 发布时间: 2026-01-23 15:16
22. [Flutter 独立开发] 挑战千元机极限:纯客户端计算 K 线+指标,三星 A53 依然稳定 60+帧
[Flutter 独立开发] 挑战千元机极限:纯客户端计算 K 线+指标,三星 A53 实测 70 FPS
大家好,我是《交易学徒》的独立开发者,祝大家周末愉快!
做过金融类 App 的朋友都知道,移动端的 K 线图( Candlestick Chart ) 渲染一直是性能优化的“深水区”。
为了降低服务器成本和网络延迟,我做了一个“违背祖宗”的决定:完全依赖客户端算力。 所有的技术指标( MA, BOLL, MACD 等)计算,全部在移动端本地实时完成,不依赖后端返回计算结果。
这意味着,一台三星 A53 ( Exynos 1280 处理器,典型的千元机性能)不仅要负责 UI 绘制,还要在主线程实时遍历数组计算指标。
在这种“地狱模式”下,优化成果如何?
📉 性能实测:A53 跑分数据
测试设备 :三星 Galaxy A53 (Exynos 1280) 测试场景 :
- GOLD 平均每秒 2.5 次报价
- 加载 500 根 K 线数据
- 同时开启 MA (移动平均线) + BOLL (布林带) + MACD 三组指标 + 图表网格
- 所有指标数据均为 本地实时计算
- 进行高频拖拽、缩放操作
实测结果 :
1. 三星 A53 (低端机代表)
70 FPS ! 在这种重负载下,UI 线程依然保持极高的流畅度,超过 60Hz 的及格线。对于一款千元机来说,这个渲染性能我已经非常满意了。
2. 三星 S25+ (旗舰机代表)
旗舰机毫无压力,贵的还是好哇。
🏛️ 技术挑战:为何 Dart 能抗住?
很多人对 Flutter 的印象还停留在“套壳性能差”。但实际上,通过合理的架构,Dart 的性能完全够用。我的优化核心思路是:UI 渲染与数据计算分离,用空间换时间。
1. 极致的分层渲染 (Layered Rendering)
我利用
Stack将视图拆解为三个独立的渲染层级:
- **Layer A (底层)**:静态 K 线与网格。这是最“重”的层(包含数千个顶点),只有在缩放或平移时才重绘。
- **Layer B (中间层)**:技术指标 (MA, BOLL)。与 K 线同步,但逻辑分离。
- Layer C (交互层): 这是优化的关键。包含当前的 Bid/Ask 价格线、十字光标。这一层极其轻量,且更新频率最高(每秒数次)。
通过
Stack+RepaintBoundary,实现了:价格跳动时,底层的几百根 K 线完全不需要参与重绘,GPU 只需要绘制那几条横线。2. 动态 LOD (Level of Detail) 策略
在手机屏幕上展示 500 根 K 线时,GPU 光栅化压力巨大。 我在代码中加入了 LOD 策略:
- Zoom In :渲染完整的
Candlestick(蜡烛图)。- Zoom Out :当可视区域数据点过多时,自动切换为
LineChart(收盘价连线)。这极大地降低了 GPU 的顶点绘制数量,解决了缩放时的“卡顿感”。
📱 软件界面预览
目前的 UI 风格偏向现代扁平,针对移动端操作做了很多适配。
🔗 下载与体验
软件目前已上架 Google Play ,名为“交易学徒” 。如果你对高性能 Flutter 开发或者交易感兴趣,欢迎下载体验。
- Google Play :[https://play.google.com/store/apps/details?id=com.zengkai.jyxtclient]
- 官网 :[https://www.zgjiazu.top]
🎁 V 友专属福利
感谢大家看完这么枯燥的技术分析。 人肉送 VIP :在评论区留下你的 用户 ID (在“我的”页面可以看到),我会手动为你开通 1 个月的 VIP 会员 。
欢迎大家对 UI 、交互或者技术实现提出建议,每一条我都会认真看!



作者: kai92zeng | 发布时间: 2026-01-23 08:15
23. 移动 NAS 推荐
有一台群晖的 NAS ,16TB RAID1 和 8T Basic 日常比较依赖 Synology Drive 同步文件数据 年底会因为公事出国呆一年多,想带着一些数据一起走 把这个 NAS 搬过去不现实,所以打算年中组一台全闪的移动 NAS 也考虑过对拷的那种移动硬盘盒(两个 M2 的那种) 想问有没有什比较好的解决方案?
作者: CLOUDUH | 发布时间: 2026-01-23 02:40
24. 有没有便宜好用的服务器推荐
最近用了 claude code, 工作效率大大提升, 空闲的时间想自己弄个项目, 但是又不知道写啥, 想着先弄一台服务器试试, 便宜好用点的, 最好是国外的, 省的备案了
作者: anidxin23333 | 发布时间: 2026-01-23 10:12
25. 求助,谁会用那个 mongoDB 的云数据库啊,帮看看咋链接报错呢
如题,node.js 链接数据库报错:
✗ MongoDB connection failed: Error: queryTxt ETIMEOUT cluster0.ev5vqfk.mongodb.net at QueryReqWrap.onresolve [as oncomplete] (node:internal/dns/promises:294:17) { errno: undefined, code: ‘ETIMEOUT’, syscall: ‘queryTxt’, hostname: ‘cluster0.ev5vqfk.mongodb.net‘ }
下面是我按照官网配置的数据库访问的 URL ,在数据库页面也已添加当前 IP 地址进白名单了 mongodb+srv://wdz_db_user:cbim2025@cluster0.ev5vqfk.mongodb.net/?appName=Cluster0
作者: azhi2007 | 发布时间: 2026-01-23 15:38
26. Antigravity 不能用 咋办?
使用 Antigravity Tools 能登陆到 Antigravity ,但是输入提示词,报错是什么原因?
LLMs aren’t perfect. There are a number of reasons why an error can occur:
LLMs can generate incorrect responses that we cannot handle.
Sometimes errors are part of a model’s research and planning process. It may take a mistake or two to learn your computer environment, what files exist, what tools are available, and so on.
If you believe this is a bug, please file an issue. As always, you can use the thumbs up or thumbs down feedback mechanism to help improve our metrics.
作者: fuxintong | 发布时间: 2026-01-23 02:38
27. 如果发现 AI 生成的代码有多个 bug , 怎么办?
方案 1:一次性告诉 AI 所有的 bug , 让它一次性修复
方案 2:每次只告诉 AI 一个 bug , 让它逐个修复
作者: Nexora | 发布时间: 2026-01-23 04:00
28. ChromeOS Flex,如何科学上网 ?
我在笔记本上,安装了 ChromeOS Flex ,请问如何科学上网 ?
我需要科学上网之后,登录我的谷歌账号。
在 ChromeOS Flex 中,目前,因不知如何进行科学上网,导柱无法登录我的谷歌账号,只能使用 [访客身份] 使用 ChromeOS Flex , 只能使用有限的功能。
作者: c2r5 | 发布时间: 2026-01-22 18:28
29. Java 写的 Postman 替代品 EasyPostman 被阮一峰老师的科技爱好者周刊选中了
前几天看到有小伙伴的帖子说他的开源被阮一峰老师的科技爱好者周刊选中了,我上周也去投稿了我的 EasyPostman,很开心也被选中了。 https://www.ruanyifeng.com/blog/2026/01/weekly-issue-382.html
10 月份我发布的 用 Java 写了个开源的 Postman 替代品,本地存储 + Git 协作 https://www.v2ex.com/t/1167863
EasyPostman 是一款开源的 API 调试与性能测试工具,对标 Postman + JMeter ,专为开发者优化,界面简洁、功能强大,内置 Git 集成,支持团队协作与版本控制。
作者: lakernote | 发布时间: 2026-01-23 01:18
30. token 不够用,大家是一个什么组合
Claude Code pro+ claude code+minimax token 不够用,
大家是一个什么组合,感觉 glm 模型有点垃圾,一个小问题给我修的乱起八糟,也不太想用。
作者: chenguangwei | 发布时间: 2026-01-21 07:03
31. AI 时代如何证明个人项目的真实性?
背景
前天朋友提供一个内推岗,这个公司蛮不错的,规模大待遇好还不是外包也不是有争议的 web3 ,他在里面工作,说招好几个月了还是没人去。我有个个人微服务项目准备拿去应聘,然而推荐后说没办法还是得垂直经验,因为现在有 AI 生成代码很简单,个人项目很容易被认为是 AI 代工。
项目介绍
项目原先是通过网课教程做的但不符合生产要求被我全部推翻重写,原来是 go micro 2.9.1 现在是 go micro 4 ,所有服务都是领域驱动,改过框架源码,链路追踪、监控、日志系统、架构等全部一人完成,期间技术栈做了很大的调整,一共迭代 6 个版本,目前是 6.1 ,耗时 3 个月,至今仍在迭代,有部分自编组件。包含压测报告、决策记录、变更日志和自述文件(含项目介绍及部署指南),用 Github Project 管理项目,2 周一版,部署在阿里云 K8S 集群上,使用超过 15 个组件,还用到 LUA 脚本。服务是模拟支付回调扣减库存过程,每个服务 2 个副本,单个 Pod 上限为单核 CPU + 512M 内存,压测 1596Qps ,P99 为 84ms 。
不存在 AI 代工
我开发过程中主要是用 AI 推荐轻量级工具并分析其难度,代码大部分还是自己写,因为 go micro 做 EDA 架构的案例本身就少得可怜直接导致 AI 生成的代码不靠谱,最后还是被我的方案优雅地取代。开发过程中每个版本都是巨大的挑战。
请问各位大佬如何证明个人项目不是 AI 代工以实现成功转型 Golang 开发?
作者: zhanshen1614 | 发布时间: 2026-01-23 03:31
32. 微软免费 2 年的 Microsoft 365 Premium 订阅—继上次免费 e3 全局
继上次微软免费的 Microsoft 365 E3 全局 https://v2ex.com/t/1172827
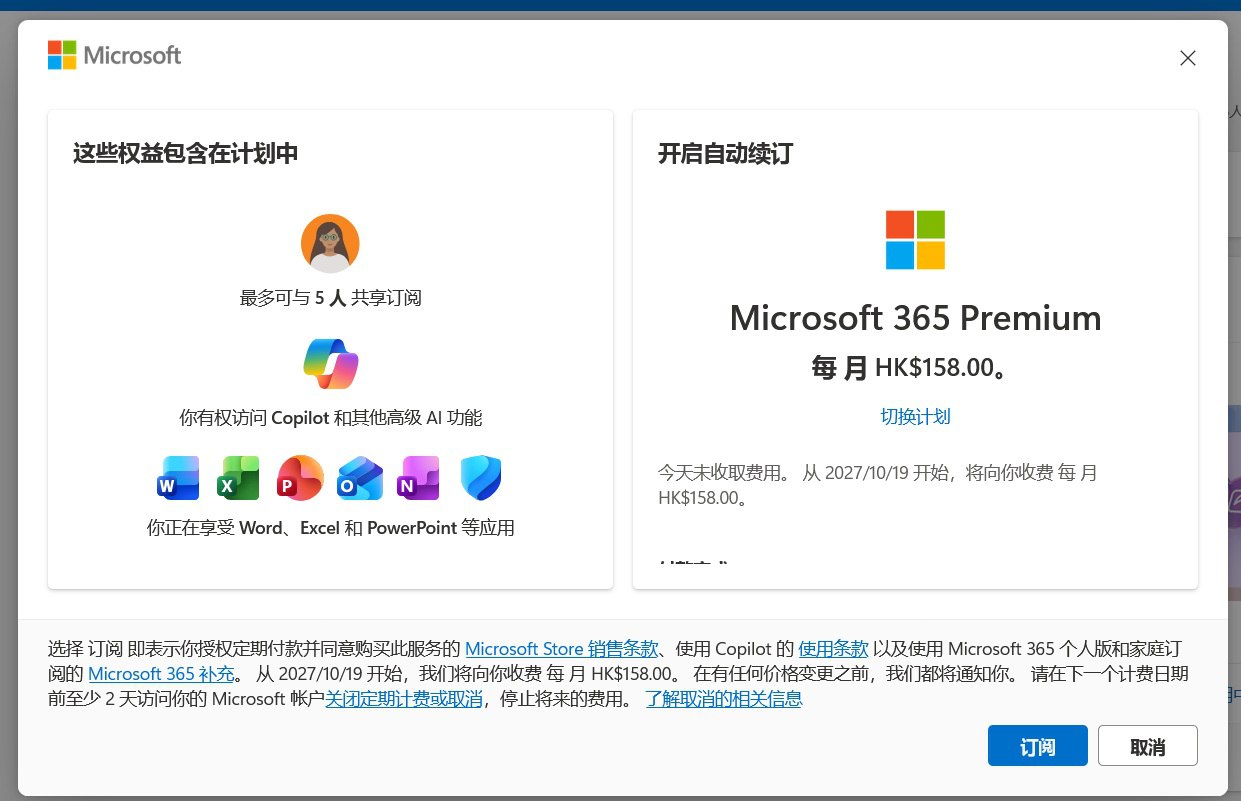
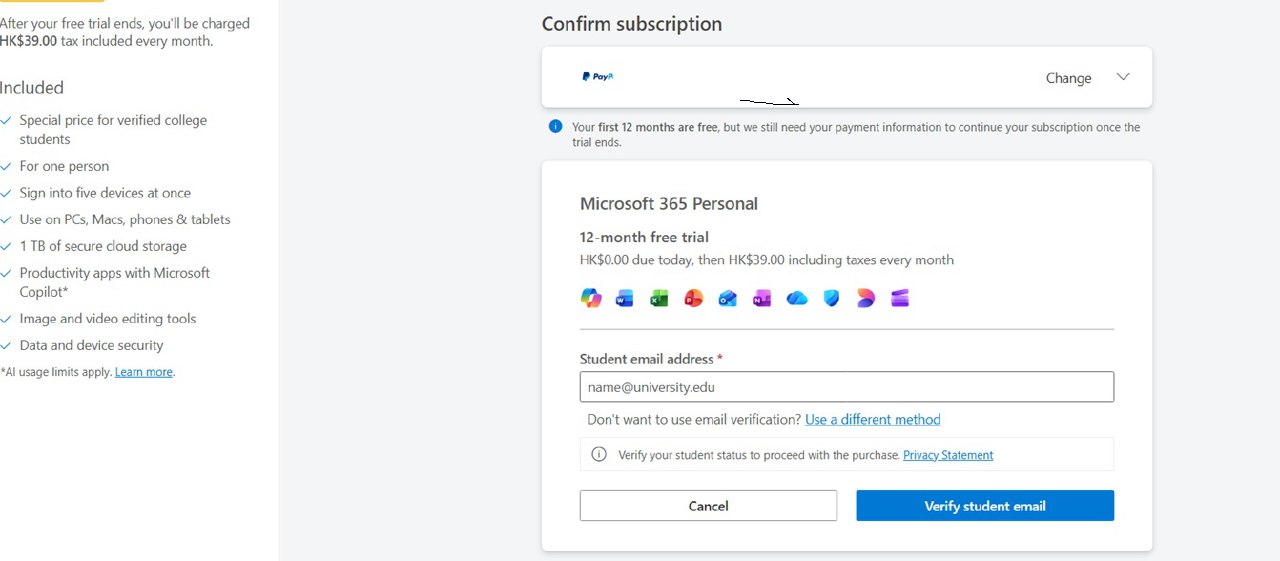
看到隔壁有人发,我想起了去年也验证过,方法很简单,当然前提你有 edu 邮箱,没有的话去 google 搜个社区大学注册。
去年起微软针对教育用户(学生)免费提供 2 年的 Microsoft 365 Premium 订阅。按微软价格的话,大概人民币 3000 多。
Microsoft 365 Premium 以每月 19.99 美元的价格,同时提供微软 Office 套件的使用权限与 Copilot Pro 的功能。该订阅包含更高的功能使用限额,以及 Copilot Labs 、Actions 等 Copilot Pro 专属功能的访问权限等。同时你可以通过电子邮件邀请最多 5 个人加入你的 Microsoft 365 家庭版订阅。
具体方法
必备条件 edu 邮箱。
登录你的微软个人账号,依次点击下面链接,进入验证,填写你的大学 edu 邮箱。 邮箱 个人版: https://checkout.microsoft365.com/acquire/purchase?language=EN-US&market=HK&requestedDuration=Month&scenario=microsoft-365-student&client=poc&campaign=StudentFree12M
支付方式支持 paypal ,支付宝等,验证订阅后,你可以直接取消自动续费,就不会扣费风险!
作者: tunggt | 发布时间: 2026-01-20 04:16
33. 小公司开发有什么需要避免的操作吗
目前背景: 是个小公司的后端开发,服务器,数据库,git,公司路由器都在我手里,感觉责任重大,想知道有什么需要避免的操作吗,主要是害怕万一一周或者几个月我不在,避免公司业务出问题
以下是我自己想到的几点,想知道还有没有其他没想到的方案
1.数据库的分区表,特别是和时间相关的,不能手动生成,要不然后面人不在没交代的话会直接给服务器崩掉
2.给本地调试的服务器端口白名单,不能图方便给网段开白名单,要不然后面会有脚本小子或者勒索病毒来扫
3.一些公共库,如果有不符合业务需求的地方,不要把人家的源码拉下来自己改然后编译成引用放在库里,(比如说 ef core upsert 的库之前不支持 ef10)否则后面更新时候会炸掉
4.单元测试不要埋雷,一些当调试用的或临时跑点小任务单元测试不能放在例行单元测试的文件夹里面,污染数据库
作者: yixin026 | 发布时间: 2026-01-22 06:51
34. 有些 roundcube 主题的吗?
报个价, 留个联系方式.
作者: Hermitist | 发布时间: 2026-01-23 09:22
35. all in vscode 远程开发体验 ssh 和 tunnel 对比.
- 服务器远程开发, 服务器需要安装对应的 vscode 插件(只安装 code 分析, lsp 插件, 不安装 UI 插件, UI 插件本地装)
- 端口自动转发, 你的代码中打印了 localhost:8080 端口, 会自动转发到本地
- ssh 网络不好, 容易掉线, tunnel 肉眼可见的延迟, 好处就是无公网的机器也能直接远程
先上图

作者: SethShi | 发布时间: 2026-01-23 09:00
36. ubuntu 下的风扇转速控制?
家里的电脑装的 pc 用的水冷。 在 win 下面,因为装了厂商的驱动,貌似正常办公的时候,风扇转速很低,没有声音。但是 ubuntu 下面,貌似已启动就是高速。。。不知道各位佬们在 ubuntu 下面可以怎样也控制下显卡和水冷风扇的转速嘛?
作者: qweruiop | 发布时间: 2026-01-23 06:53
37. vscode 怎么使用 claude
如题,现在美国梯子开了,vscode 以代理方式打开的,然后 claude 插件在验证后还是一直提示需要验证,请大佬指导下
作者: mr123villain | 发布时间: 2026-01-23 02:37
38. 死了么 APP 更新 2.0 版本变 Demumu:新增签到提醒、短信通知
目前,原“死了么”APP 在部分地区 App Store 上线 2.0 版本。更新记录显示,新版本新增签到提醒、短信通知,并修复若干问题。
值得注意的是,“死了么”APP 此前宣布要在新版本中正式启用全球化品牌名称“Demumu”,目前也已更名。
据介绍,该应用是为独居人群打造的轻量化安全工具。
用户需要设置紧急联系人并签到,若连续多日没在应用内签到,系统将于次日自动发送邮件告知紧急联系人。
6.99 刀,真的有人买么,我建议改成订阅制的🐶

作者: kiritoyui | 发布时间: 2026-01-23 01:23
39. ✨ Claude Code v2.1.16 & v2.1.17 发布啦!
📅 发布:2026-01-23 04:09:21
✦ 更新内容
• 新增任务管理系统,包含依赖关系跟踪等新能力
• VSCode:新增原生插件管理支持
• VSCode:OAuth 用户现在可以在 Sessions (会话)对话框中浏览并恢复远程 Claude 会话
• 修复:在恢复包含大量子代理( subagent )使用的会话时出现的内存不足( out-of-memory )崩溃
• 修复:运行 /compact 后,“剩余上下文( context remaining )”警告未被隐藏的问题
• 修复:恢复界面上的会话标题未遵循用户语言设置的问题
• IDE:修复 Windows 上的一个竞态条件,可能导致 Claude Code 侧边栏视图容器启动时不显示📅 发布:2026-01-23 05:46:31
✦ 更新内容
• 修复:在不支持 AVX 指令集的处理器上发生的崩溃问题https://github.com/anthropics/claude-code/releases/tag/v2.1.16
📅 Published: 2026-01-23 04:09:21✦ What’s changed
• Added new task management system, including new capabilities like dependency tracking
• VSCode Added native plugin management support
• VSCode Added ability for OAuth users to browse and resume remote Claude sessions from the Sessions dialog
• Fixed out-of-memory crashes when resuming sessions with heavy subagent usage
• Fixed an issue where the “context remaining” warning was not hidden after running /compact
• Fixed session titles on the resume screen not respecting the user’s language setting
• IDE Fixed a race condition on Windows where the Claude Code sidebar view container would not appear on start📅 Published: 2026-01-23 05:46:31
✦ What’s changed
• Fixed crashes on processors without AVX instruction support
作者: hzlzh | 发布时间: 2026-01-23 05:53
40. 使用闲鱼上的 AI CODE 共享号、三方账号时会不会导致信息泄露
PS:源码不值钱,本来就是抄来的。但是不想泄露跟公司有关的一些信息,比如 API 、数据库配置、密码(写在.env 文件里,没有记在环境变量)
作者: unt | 发布时间: 2026-01-23 02:25
41. 在 vscode 的 claude code 插件中能否使用 Google Antigravity 反代?
如题,请问大家,在 vscode 的 claude code 插件中能否使用 Google Antigravity 反代?
如何使用?
作者: sn0wdr1am | 发布时间: 2026-01-23 01:13
42. [独立开发] 单机 Rust 如何抗住 10w+ 在线行情推送?告别 Redis/Kafka,聊聊我的“极简主义”架构
大家好,我是《交易学徒》的独立开发者。
最近在重构后端行情网关,目标是支撑 10w+ 同时在线用户。在技术选型时,很多“标准答案”是微服务、Redis 集群、Kafka 消息队列。但作为独立开发者,维护这一套重型架构的运维成本和心智负担太高了。
于是我反其道而行之,选择了一种“极致单机” 的方案:没有任何外挂组件( No Redis, No Kafka ),所有状态在进程内解决,纯 Rust 函数调用。
经过实战验证,这套架构不仅部署简单(就一个 Binary ),而且足够稳定。今天分享一下我是如何用 Rust 的特性“白嫖”性能的,欢迎 V 友们拍砖。
一、 核心理念:按需订阅,算一笔带宽的账 早期的 demo 喜欢大包大揽,客户端连上来就推 Top 20 币种。这在用户量大时是灾难。我的做法是“用户看哪里,就只推哪里” 。
客户端停留在 BTC/USDT 的 15 分钟 K 线界面,服务端就只建立这一个订阅关系。一旦切换,立马移除旧订阅。
算一笔账( Resource Cost ): 假设一个行情包 Payload 是 200 Bytes ,推送频率 5 次/秒。
全量推送(推 Top 20 ):10 万用户 x 20 个币种 x 200B x 5 = 2 GB/s (带宽直接破产)。
按需订阅(推 1 个):10 万用户 x 1 个币种 x 200B x 5 = 100 MB/s 。
结论: 简单的逻辑改变,带宽节省 95%,单机千兆网卡轻松抗住。
二、 列表行情:Polling + 边缘计算(白嫖 CF ) 对于“行情列表”这种一屏显示几十个数据的页面,建立长连接维护成本太高。 我采用了 1 秒轮询 + Cloudflare 边缘缓存 的策略。
策略: 设置 HTTP 响应头,让 CF Edge Cache TTL = 1 秒。
效果:10 万人同时刷新列表,99% 的流量被 CF 的全球节点挡住了,真正打到我源服务器 Rust 进程的 QPS 只有个位数。
收益: 既利用了 CDN 的带宽,又保护了单机后端。
三、 架构做减法:进程内通信替代中间件 这是我这次重构最大的感悟:单机并发足够高时,不需要 Redis 和 Kafka 。
替代 Redis: 使用 Rust 的 DashMap (Concurrent HashMap)。数据就在内存里,读写是纳秒级,没有网络 IO 开销,没有序列化/反序列化成本。
替代 Kafka: 使用 tokio::sync::broadcast 和 mpsc::channel 。
优势: 传统的“发布-订阅”为了解耦上了 MQ ,但在单机 Rust 里,一个 Arc
就能解决问题。部署时不需要操心 MQ 挂没挂,只要我的进程活着,消息系统就活着。 四、 信使模式 (Messenger Pattern) 与背压 在 Tokio 异步编程中,最忌讳 await 阻塞。 如果客户端网络卡顿(比如进电梯),socket.send().await 可能会阻塞,导致同个 Loop 下的心跳包处理被卡死,造成“假死”。
我的解法:
读写分离: 为每个连接 spawn 一个独立的 send_task ,通过 mpsc::channel(128) 通信。
严格背压 (Backpressure): 使用 try_send 。如果 Channel 满了(说明客户端来不及收),直接丢弃新行情。
理由: 实时行情旧数据无价值。这行代码是系统的“保命符”,防止慢客户端拖垮服务端内存( OOM )。
五、 极致性能:Zero-Copy (零拷贝) 在广播行情时,不要为 10 万个用户 copy 10 万份数据。
Rust // 内存中只有一份二进制 Payload let payload = Arc::new(Bytes::from(vec![…]));
// 10 万次分发只是增加了 10 万次引用计数( Reference Counting ) // 几乎没有任何内存分配开销 for client in clients { client.tx.try_send(payload.clone()); } 利用 Rust 的 Arc 和 Bytes ,让 CPU 缓存极其友好。 六、 扫地僧:资源清理 长运行的单机服务最怕内存泄漏。 当 socket 断开时,必须像外科手术一样精准清理:
从 DashMap 移除 Client 。
清理反向索引 subscriptions 。
如果某个 Topic 无人订阅,立即 drop 掉对应的 channel 发送端,停止上游数据生产。
总结 作为独立开发者,资源有限。这套“Rust 单机 + 无外挂组件” 的架构,让我用最低的成本(一台服务器)抗住了业务压力,而且睡得很安稳。
Simplicity is the ultimate sophistication.
🎁 V 友专属福利 软件名字叫 《交易学徒》,是一个辅助交易员复盘、模拟、练盘感的工具。前端也是我用 Flutter 写的( Rust + Flutter 真是全栈开发的绝配)。
官网下载: https://www.zgjiazu.top
Google Play: https://play.google.com/store/apps/details?id=com.zengkai.jyxtclient
回帖福利: 在本帖回复并附上 App 内的 ID (在‘我的页面’可以看到),我后台人肉送一个月 VIP 会员。
同时也欢迎大家在评论区提 Bug ,或者交流关于 Rust 后端与 Flutter 前端开发的坑!
作者: kai92zeng | 发布时间: 2026-01-22 07:46
43. [踩坑] A 股开盘把 Python 搞挂了,怒切 Go 重写行情网关 (附 pprof 分析 + 源码)
💥 事故现场
LZ 所在的量化小厂,早期基础设施全是 Python (Asyncio) 一把梭。 跑美股( US )的时候相安无事,毕竟 Tick 流是均匀的。 上周策略组说要加 A 股 (CN) 和 外汇 (FX) 做宏观对冲,我就按老套路接了数据源。结果上线第一天 9:30 就炸了。 监控报警 CPU 100%,接着就是 TCP Recv-Q 堆积,最后直接断连。 策略端收到行情的时候,黄花菜都凉了(延迟 > 500ms )。
🔍 排查过程 (Post-Mortem)
被 Leader 骂完后,挂了 py-spy 看火焰图,发现两个大坑:Snapshot 脉冲:A 股跟美股不一样,它是 3 秒一次的全市场快照。几千只股票的数据在同一毫秒涌进来,瞬间流量是平时的几十倍。
GIL + GC 混合双打:
json.loads 是 CPU 密集型,把 GIL 锁死了,网络线程根本抢不到 CPU 读数据。
短时间生成大量 dict 对象,触发 Python 频繁 GC ,Stop-the-world 。
🛠️ 架构重构 (Python -> Go)
为了保住饭碗,连夜决定把 Feed Handler 层剥离出来用 Go 重写。 目标很明确:扛住 A 股脉冲,把数据洗干净,再喂给 Python 策略。架构逻辑:WebSocket (Unified API) -> Go Channel (Buffer) -> Worker Pool (Sonic Decode) -> Shm/ZMQ
为什么用 Go ?
Goroutine:几 KB 开销,随开随用。
Channel:天然的队列,做 Buffer 抗脉冲神器。
Sonic:字节开源的 JSON 库,带 SIMD 加速,比标准库快 2-3 倍(这个是关键)。
💻 Show me the code
为了解决 协议异构( A 股 CTP 、美股 FIX 、外汇 MT4 ),我接了个聚合源( TickDB ),把全市场数据洗成了统一的 JSON 。这样 Go 这边只用维护一个 Struct 。以下是脱敏后的核心代码,复制可跑(需 go get 依赖)。
package mainimport (
“fmt”
“log”
“runtime”
“time”“github.com/bytedance/sonic“ // 字节的库,解析速度吊打 encoding/json
“github.com/gorilla/websocket“
)// 防爬虫/防风控,URL 拆一下
const (
Host = “api.tickdb.ai“
Path = “/v1/realtime”
// Key 是薅的试用版,大家拿去压测没问题
Key = “?api_key=YOUR_V2EX_KEY”
)// 内存对齐优化:把同类型字段放一起
type MarketTick struct {
Cmd stringjson:"cmd"
Data struct {
Symbol stringjson:"symbol"
LastPrice stringjson:"last_price"// 价格统一 string ,下游处理精度
Volume stringjson:"volume_24h"
Timestamp int64json:"timestamp"// 8 byte
Market stringjson:"market"// CN/US/HK/FX
}json:"data"
}func main() {
// 1. 跑满多核,别浪费 AWS 的 CPU
runtime.GOMAXPROCS(runtime.NumCPU())url := “wss://“ + Host + Path + Key
conn, _, err := websocket.DefaultDialer.Dial(url, nil)
if err != nil {
log.Fatal(“Dial err:”, err)
}
defer conn.Close()// 2. 订阅指令
// 重点测试:A 股(脉冲) + 贵金属(高频) + 美股/港股
subMsg :={ "cmd": "subscribe", "data": { "channel": "ticker", "symbols": [ "[600519.SH](http://600519.SH)", "[000001.SZ](http://000001.SZ)", // A 股:茅台、平安 (9:30 压力源) "XAUUSD", "USDJPY", // 外汇:黄金、日元 (高频源) "[NVDA.US](http://NVDA.US)", "[AAPL.US](http://AAPL.US)", // 美股:英伟达 "[00700.HK](http://00700.HK)", "[09988.HK](http://09988.HK)", // 港股:腾讯 "BTCUSDT" // Crypto:拿来跑 7x24h 稳定性的 ] } }
if err := conn.WriteMessage(websocket.TextMessage, []byte(subMsg)); err != nil {
log.Fatal(“Sub err:”, err)
}
fmt.Println(“>>> Go Engine Started…”)// 3. Ring Buffer
// 关键点:8192 的缓冲,专门为了吃下 A 股的瞬间脉冲
dataChan := make(chan []byte, 8192)// 4. Worker Pool
// 经验值:CPU 核数 * 2
workerNum := runtime.NumCPU() * 2
for i := 0; i < workerNum; i++ {
go worker(i, dataChan)
}// 5. Producer Loop (IO Bound)
// 只管读,读到就扔 Channel ,绝对不阻塞
for {
_, msg, err := conn.ReadMessage()
if err != nil {
log.Println(“Read err:”, err)
break
}
dataChan <- msg
}
}// Consumer (CPU Bound)
func worker(id int, ch <-chan []byte) {
var tick MarketTick
for msg := range ch {
// 用 Sonic 解析,性能起飞
if err := sonic.Unmarshal(msg, &tick); err != nil {
continue
}if tick.Cmd == “ticker” {
// 简单的监控:全链路延迟
latency := time.Now().UnixMilli() - tick.Data.Timestamp// 抽样打印
if id == 0 {
fmt.Printf(“[%s] %-8s | Price: %s | Lat: %d ms\n”,
tick.Data.Market, tick.Data.Symbol, tick.Data.LastPrice, latency)
}
}
}
}📊 Benchmark (实测数据)
环境:AWS c5.xlarge (4C 8G),订阅 500 个活跃 Symbol 。 复现了 9:30 A 股开盘 + 非农数据公布 的混合场景。
指标,Python (Asyncio),Go (Sonic + Channel),评价
P99 Latency,480ms+,< 4ms,简直是降维打击
Max Jitter,1.2s (GC Stop),15ms,终于不丢包了
CPU Usage,98% (单核打满),18% (多核均衡),机器都不怎么转
Mem,800MB,60MB,省下来的内存可以多跑个回测📝 几点心得
术业有专攻:Python 做策略逻辑开发是无敌的,但这种 I/O + CPU 混合密集型的接入层,还是交给 Go/Rust 吧,别头铁。别造轮子:之前想自己写 CTP 和 FIX 的解析器,写了一周只想跑路。后来切到 TickDB 这种 Unified API ,把脏活外包出去,瞬间清爽了。
Sonic 是神器:如果你的 Go 程序瓶颈在 JSON ,无脑换 bytedance/sonic ,立竿见影。
代码大家随便拿去改,希望能帮到同样被 Python 延迟折磨的兄弟。 (Key 是试用版的,别拿去跑大资金实盘哈,被限流了别找我)
作者: Howiee | 发布时间: 2026-01-21 08:22
44. AgentSkills for AI Developers
大家好,我是 AgentSkills.to 的开发者。
在开发过程中,我发现为 Claude Code 、Cursor 或 Codex CLI 重复编写复杂的提示词非常耗时。为了解决这个问题,我构建了 AgentSkills.to —— 一个开源的“技能”市场,旨在让 AI Agent 真正具备生产力。 为什么值得一试?
即插即用: 拥有 3,700+ 项涵盖前端、后端及 DevOps 的生产级技能。
跨平台: 完美适配 Claude Code, Cursor, Codex CLI 和 Amp 。 开源共享: 你可以免费获取所有工作流,也可以在 GitHub 上贡献你的独家秘籍。 我们的目标是让大家不再浪费时间“重复造轮子”,而是通过社区验证的技能快速交付高质量代码。
欢迎体验: https://agentskills.to
作者: quiqa | 发布时间: 2026-01-22 23:41
45. 有没有微信文件传输助手的 App 或开源第三方工具?
https://szfilehelper.weixin.qq.com/
这个网页很简单, 就能传文字和文件, 不知道有没有人做了相关工具的?
如果没有微信这方面的工具, 大家都是怎么在不同手机和电脑上互传文件的?
听闻 apple 生态很方便, 可是我主要用 windows, 手机是一加和 iPhone.之前本来是搞了几个微信号来互传, 现在 google voice 注册的微信号啥也没干就给封号了.
Edge 的 drop 也用了好一阵, 最近老是无响应, 也很不好用了.
邮件又稍微有点麻烦, 没好的办法的话就只能用邮件了.
作者: jqknono | 发布时间: 2026-01-22 12:58
46. vibe coding 真的会上瘾啊,停不下来!
另外我发现 Claude opus 在写页面样式上真的比 gemini pro 差了一个档次啊。
当然其他方面感觉都很强,让我肃然起敬的那种🫡
作者: Aaron01 | 发布时间: 2026-01-21 21:00
47. 想请教大家关于学习新知识时的思路或者说最佳实践
最近在看着 Spring AI 的官方文档来学习 Java 在 AI 这方面的东西,但是我遇到一个问题就是,经常遇到看不懂,或者写了同样的代码却跑不起来的问题。
我举个例子: Spring AI 的官方文档的 Reference/Chat Client API 或者 Reference/Prompts 里面已经写了很多示例代码了,但是其实跟着写出这些代码后,程序是跑不起来的,一直到下面第五节的 Models 篇章里面,才介绍了说需要引入各模型的依赖,上面那些章节的示例代码才能运行。
我觉得可能是我的文档阅读思路不对(或许应该先整体大致阅读一遍?然后再考虑写 demo 来熟悉?),所以想问问大家,大家在学东西的时候,一般是遵循怎样的学习思路来学习的?看书?看视频?或者说,大家阅读官方文档的时候,是怎样的思路来阅读的?
作者: AkaneWWW | 发布时间: 2026-01-22 14:30
48. giffgaff 手机卡充值后才有信号吗
闲鱼上买的一个卡,插上后一直无服务,必须充值以后才有信号吗?
20 多买的,发现论坛上还有免费送呢,亏大了
作者: yuanyao | 发布时间: 2026-01-22 05:29
49. 大家都是用什么 AI 来生成设计稿的?
比如我想要做一个 App ,代码是可以使用 Cursor 之类的 IDE 来做,但是整体看起来的 UI 效果不是很好,有没有可以生成 UI 设计稿,或者生成一些图标的?或者大家自己独立做开发的时候,如何解决 UI 这块的需求。
希望各位大佬帮忙解答下,先提前谢谢了~
作者: canyu9512 | 发布时间: 2026-01-22 08:56
50. 国内外一个有趣的技术倾向区别
今天在看分布式任务工具 找来找去看到 3 个,xxl-job, powerjob, elasticjob 然后我发现居然全是国产的,类似产品竟然没有国外的,我寻思不应该啊 (不是说国外的就好什么的,但是这种中间件没有的话确实感到奇怪) 问了 AI 得到如下回答
XXL-JOB 、ElasticJob 这类工具在中国特别火,是由中国互联网特定的技术土壤决定的 国外用 Quartz ,它是祖师爷,国内工具大多是对 Quartz 的二次封装(加了 UI 、加了分片、加了 RPC )。国外老项目仍大量直接用 Quartz 。 国外云原生走得更早,很多简单的定时任务直接交给 Kubernetes CronJob 或云厂商的 Serverless 服务了,不需要额外部署一个 XXL-JOB ,复杂的任务则是选择 Airflow 这样的工作流平台 国内的 ElasticJob 和 XXL-JOB 实际上是卡在了“简单 Cron”和“复杂编排”中间的一个完美生态位:它比 Quartz 好用,比 Airflow 简单,又完美契合 Java 生态如果真是这样那感觉还是挺有意思的,居然这样奇怪的产生了一个技术生态位
作者: litchinn | 发布时间: 2026-01-22 06:40