V2EX 热门帖子
1. 我看有人说 win11 正常安装得系统, 其实都是运行在虚拟机上的
所以性能慢, 即便配置高都有卡顿
真的假的, 这么大问题没人提阿
关键是, 关不掉这种默认虚拟机方式
我反正以前装过两次 win11, 很快受不了都换成 win10 了, 近 3,4 年再没试过
作者: iorilu | 发布时间: 2025-12-28 11:52
2. 为什么 LLM 写的前端总是有一种廉价感?特别爱用蓝紫色渐变背景、无关 emoji
大厂纯 LLM 生成网站案例 一眼 AI 风格 aHR0cHM6Ly93d3cuYXR0LmNvbS5teC9kZXNibG9xdWVvLw==
作者: drymonfidelia | 发布时间: 2025-12-28 17:56
3. trae 的会员 600 次几天就用完了,现在咋办呢?
原本以为 600 次是快速回复次数,用完还可以排队使用,结果用完再也无法用了。 再用新号开一个?
作者: jiuzhougege | 发布时间: 2025-12-28 04:28
4. Nature vs Golang: 性能基准测试
nature 是一款较新的编程语言,其轻量简单,易于学习。在设计理念和运行时架构上参考了 golang ,同时有着更丰富的语法特性,更适用于业务开发,并在持续探索更广泛的应用领域。
性能是衡量编程语言核心竞争力的关键指标,接下来我们将从 IO 并发、CPU 计算、C 语言 FFI 、协程性能四个维度,并以 golang 作为基准对 nature 编程语言进行性能测试。
测试环境
配置项 详情 宿主机 Apple Mac mini M4 ,16GB 内存 测试环境 Linux 虚拟机( Ubuntu 6.17.8 ,aarch64 架构) 编译器 / 运行时版本 Nature:v0.7.0 ( release build 2025-12-15 ) Golang:go1.23.4 linux/arm64 Rust:cargo 1.85.0 Node.js:v20.16.0 所有测试均采用相同的代码逻辑实现,文中代码示例均以 nature 编程语言为例。
IO 并发
IO 并发是网络服务的核心能力,本测试通过 HTTP 服务端压力测试,综合考察语言的 IO 调度、CPU 利用率与 GC 稳定性。
nature 代码示例
import http fn main() { var app = http.server() app.get('/', fn( http.request_t req, ptr<http.response_t> res):void! { res.send('hello nature') }) app.listen(8888) }ab 工具测试命令
ab -n 100000 -c 1000 http://127.0.0.1:8888/
- -n 100000: 总请求数 10 万次
- -c 1000: 并发数 1000
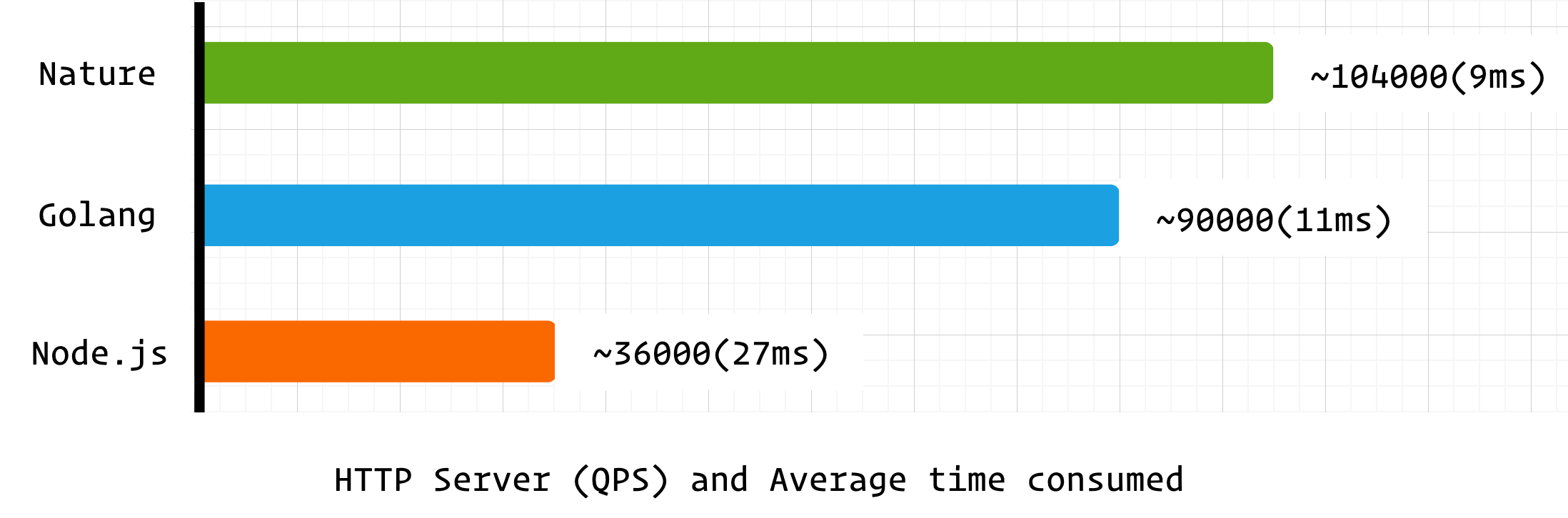
测试结果
可以看到 nature 在 HTTP 并发性能上超越了 golang ,这对于早期版本的编程语言来说可以说是不错的成绩。
由于 nature 和 node.js 均使用 libuv 作为 IO 后端,所以 node.js 也参与到基准测试中(libuv 线程不安全,node.js 和 nature 的事件循环均在单线程中运行),但 nature 作为编译型语言其并发处理能力远胜过 node.js 。
CPU 计算
使用经典的递归斐波那契数列计算
fib(45)来测试语言的 CPU 计算与高频函数调用开销。nature 代码示例
fn fib(int n):int { if (n <= 1) { return n } return fib(n - 1) + fib(n - 2) }测试方法
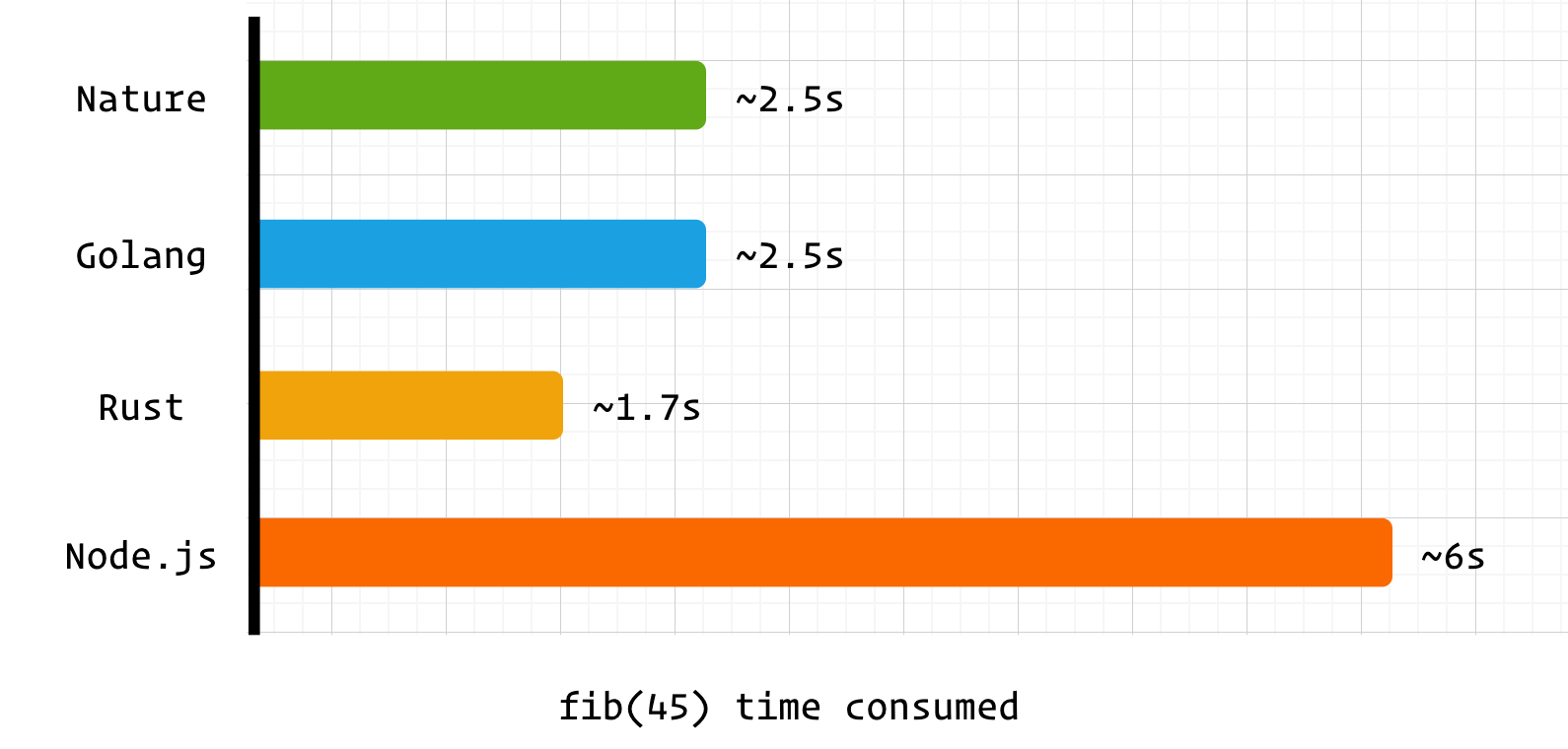
time ./main 1134903170./main 2.50s user 0.01s system 101% cpu 2.473 total测试结果:
nature 和 golang 均采用自研的编译器后端,性能上也相差无几。而耗时高于 rust 的主要原因之一是两者在函数运行前进行了额外处理。
golang 采用了抢占式调度,不需要关注 GC safepoint ,但仍需要关注协程栈是否需要扩容,也就是下面的汇编指令
# more stack f9400b90 ldr x16, [x28, #16] eb3063ff cmp sp, x16 540002a9 b.ls 7869c <main.Fib+0x5c> // b.plasnature 采用了协作式调度,所以需要处理 GC safepoint 。但 nature 采用共享栈协程,所以不需要关心栈扩容问题。
# safepoint adrp x16, 0xa9d000 add x16, x16, #0xeb0 ldr x16, [x16] cmp x16, #0x0 b.ne 0x614198 <main.fib.preempt>nature 的 safepoint 实现仍有优化空间,若后续采用 SIGSEGV 的触发模式,函数调用性能将会得到进一步提升。
nature 和 golang 采用了截然不同的调度策略和协程设计方案,这会带来哪些不同呢?不妨看看后续的测试 👇
C 语言 FFI
通过调用 1 亿次 C 标准库中的 sqrt 函数,测试与 C 语言的协作效率。
nature 代码示例
import libc fn main() { for int i = 0; i < 100000000; i+=1 { var r = libc.sqrt(4) } }测试结果
可以看到在 C FFI 方面,nature 相较于 golang 有着非常大的优势,这是因为 golang 的 CGO 模块有着非常高的性能成本,独立栈协程和抢占式调度设计与 C 语言难以兼容,需要经过复杂的处理。
而 nature 的共享栈和协作式调度设计与 C 语言更兼容,不仅仅是 C 语言,只要符合 ABI 规范的二进制库,nature 都能直接进行调用。
在高性能计算、底层硬件操作等场景中,nature 可无缝集成 C / 汇编编写的核心模块,弥补 GC 语言在极致性能场景下的不足,兼顾开发效率与底层性能。
协程
协程是现代并发编程的核心组件,本测试通过 “百万协程创建 + 切换 + 简单计算” 场景,评估 Nature 与 Golang 的协程调度效率、内存占用与响应速度。
nature 代码示例
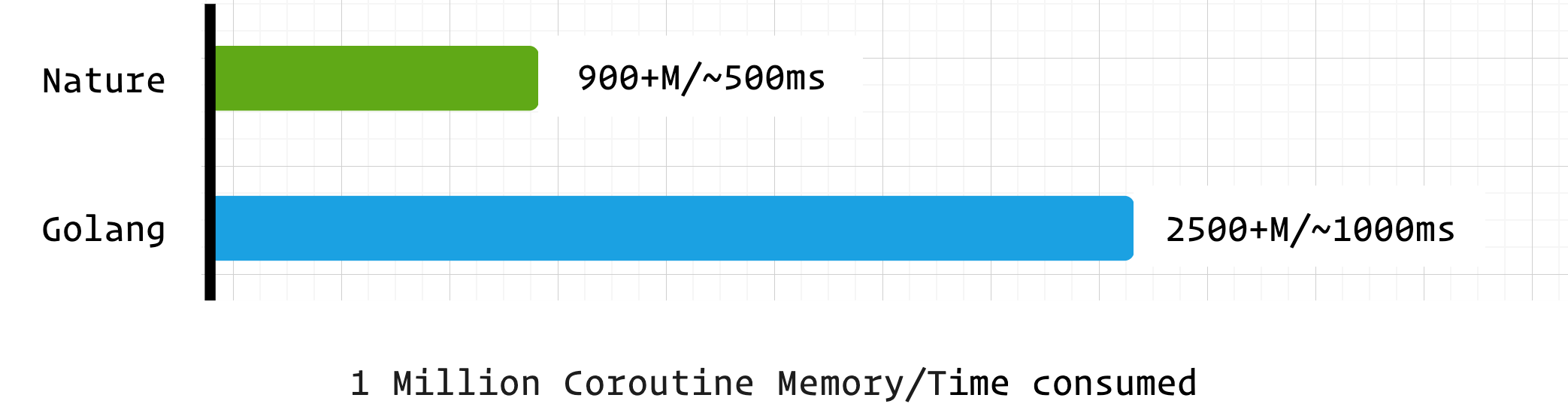
import time import co var count = 0 fn sum_co() { count += 1 co.sleep(10000) // ms, Remove this line if no sleep } fn main() { var start = time.now().ms_timestamp() for int i = 0; i < 1000000; i+=1 { go sum_co() } println(time.now().ms_timestamp() - start) // create time int prev_count = 0 for prev_count != count { println(time.now().ms_timestamp() - start, count) prev_count = count co.sleep(10) } println(time.now().ms_timestamp() - 10 - start) // calc time co.sleep(3000) // ms }测试结果
语言 创建耗时(ms) 计算耗时(ms) 无 sleep 计算耗时(ms) 占用内存 Nature 540 564 170 900+M Golang 1000 1015 140 2500+M nature 的协程在综合性能上非常优秀,内存占用更是远低于 golang 。而这是建立在 nature 的协程调度器未进行优化的前提下,预计在后续的版本中 nature 的协程调度器会进一步优化,届时将会有更加亮眼的表现。
总结
这是一次非专业的性能测试,但在粗略的测试中,nature 编程语言展现出了超越预期的能力与潜力。作为早期的编程语言,其运行时和编译器还有着非常大的优化空间,在正式版本发布时性能将进一步提升。
以现在的性能表现来看,nature 无疑是值得关注和尝试的编程语言,尤其是在云原生、网络服务、API 开发等服务端开发领域。
这是 nature 编程语言的官网 https://nature-lang.cn/ 如果你感兴趣的话也可以加入讨论组,v ➡️
nature-lang

作者: weiwenhao | 发布时间: 2025-12-22 02:01
5. 有什么支持直接连接远程主机 git 仓库的 GUI 工具吗
我们是在 wsl2 下开发的,但是宿主与 wsl2 的 io 性能实在太差了,如果仓库在 windows ,那 vscode 中写代码巨卡;如果仓库放在 wsl2 内,用 git 又巨卡(我不太会用命令),但是比起写代码卡,git 的卡我也暂时忍了,最近实在是受不了了,然后找了一圈的 gui 工具,发现 ugit 竟然有一个直接通过 ssh 连接远程主机仓库的,操作起来跟在仓库在 windows 的已经没有太多区别了,现在唯一的问题就是这玩意的 UI 逻辑真的太傻了,我在上面 stash 了一些修改我现在都没有在它的 UI 上面找到在哪里,我之前试过 sourcetree 和 sourcegit 都比它易用得多,而且 UI 高亮显示也有问题,我常常分不清我当前分支在哪里,我的选中了哪一条日志啥的。想问问还有没有类似这种可以直接连接远程主机仓库的免费工具?
作者: maninnet | 发布时间: 2025-12-28 12:06
6. 程序员对 AI 的偏见
今天 HN 最火的一贴无疑是 Rob Pike 吐槽 AI 。(吐槽可能有点委婉,应为基本是纯骂,甚至是没什么逻辑性的骂)
这让我大跌眼镜。Rob 在我心里一直是一个理性,儒雅的技术人,也是我最敬重的程序员之一。他写的 C 和 Go 都很精妙,还有 UTF-8 的设计。他的技术分享我当圣经一样诵读。
而 HN 大部分程序员也都是站 Rob 一边,国内 V2EX 也是严格禁止 AI 文。
这令我深思。为什么程序员对 AI 有这么大的偏见。是不是有点过了?
作者: cj323 | 发布时间: 2025-12-27 14:43
7. D-NET 支持阿里云 ESA,实现 IPv6 免费加速方案(IPv4/IPv6 访问)
家宽 IPv6 + 阿里云 ESA = 免费全球 IPv4/IPv6 加速!
痛点
家里搭了 All-in-One 服务器,拿到了运营商的公网 IPv6 ,但是:
- 外网访问 IPv6 太慢?仅支持 IPv6 客户端访问?
- 使用 Cloudflare CDN 访问速度较慢、延迟较高?
- 想用 CDN 加速但嫌贵?
- 域名未备案?
- IPv6 地址老变化,手动更新太麻烦?
解决方案
D-NET + 阿里云 ESA ,完美解决上述问题:
传统方案: 家庭服务器 → DDNS 更新 DNS → 域名解析 → CDN 回源 → 访问( 2 次解析)
D-NET 方案: 家庭服务器 → 监听 IPv6 地址变化直接更新 ESA → 访问( 1 次解析,更快!)
性能实测
国内节点测试(备案域名)
全球节点测试(未备案域名)
实测数据:
- 海外访问延迟降低
- 国内访问(备案域名)几乎无感知
- 免费流量,不用担心收费问题
详细教程: https://aio.it927.com/remote/esa
GitHub: https://github.com/cxbdasheng/dnet (欢迎 Star ⭐)
完整 All-In-One 教程: https://aio.it927.com
适合你吗?
如果你有以下需求,强烈推荐试试:
- ✅ 家里有公网 IPv6
- ✅ 想要全球访问加速
- ✅ 不想花钱买 CDN
- ✅ 希望自动化管理
项目还在持续迭代中,欢迎提 Issue 和 PR ! 也欢迎分享你的使用场景和需求,一起让它更好用 🚀
作者: cxbdasheng | 发布时间: 2025-12-28 05:26
8. 大家平时怎么用 ai 写代码的了,我用 cursor 写,总感觉不敬人意,差点意思。
作者: programMrxu | 发布时间: 2025-12-28 06:35
9. antigravity 网络异常, Check your internet connection.
antigravity 网络异常一直提示 Check your internet connection.
已开代理,官网都可以正常访问,就是 ide 不行。
作者: zehua | 发布时间: 2025-12-28 11:55
10. fnOS 上除了 v2raya 还有什么代理工具可用
J5005,之前是只刷了个 openwrt ,用着 passwall 或 openclash ,刚刚刷了 fnOS ,找了半天发现只有在 docker 部署 v2raya ,使用起来发现太慢了,明显跟 openwrt 里差太多。4G 内存不想再虚拟个 openwrt ,还有什么选择可以达到原来的速度。
作者: sjqboss | 发布时间: 2025-12-28 02:32
11. Linux 漫谈(三)
之前的章节:
0x30 IPC 是妥协的艺术
之前讲过了,几乎无论什么时候性能都是个永恒的追求,内核也不例外。所以在九十年代初期,开发者有机会从零设计一款操作系统内核的时候,很多方面都要为了性能作出让步。
其中受影响最大的便是 IPC 的设计,它不仅仅是受性能影响这么简单,更重要的是 IPC 的设计代表了设计者对于软件交互逻辑的理解,也决定了未来这个操作系统上,所有的应用程序要如何编写,可谓是决定性的要素。
用今天的眼光重新审视 linux/NT/XNU 当年的设计,我个人所能总结的经验教训就是:不可能有一种完美的、能够适应所有时代需求的方案,所以取舍就变得很重要,不能既要又要。
在回答如何设计 IPC 这个问题之前,更重要的问题是为什么要有 IPC ,这里特指内核控制中,不同于传统 Unix 提供的 socket/pipe 实现。而要回答这个问题,就要考虑九十年代初这个时间节点,图形化的应用程序是怎么写的。
今天看起来非常普遍的图形应用开发范式:比如 UI 和逻辑线程分离,再比如异步 RPC 调用,在图形操作系统刚出现的时候还不存在。甚至几乎没有多少真正意义上的“多线程”应用程序,因为不仅当时的 CPU 没有多核心设计,而且同时期的 Unix 还只有 fork ,而更轻量化的线程( thread )直到 1995 年才定稿。
对于大多数应用开发者来说,只需要考虑系统或者底层提供了什么样的 API 可以使用即可。而对于基础库或者操作系统的开发者来说,这个思考过程是反过来的:
先想象未来的图形 App 是什么样子,要如何编写;
之后发现现在的 C 语言和硬件支持不了这种编程范式;
确定需要在内核里增加一套支撑机制;
将内核机制封装为用户态可用的图形库供开发者使用。
于是尽管目前的章节要讨论的是 IPC 设计,实际的切入点却是图形界面应用程序。(理论上在操作系统进入多任务时代的时候,非图形界面应用程序之间也有 IPC 需求,但图形界面应用程序更具代表性,需求也更加一般化)
0x31 现代图形界面的基础
在正式讨论开始之前,先补充一些背景知识。
现代意义上的图形界面最早是 1973 年由 Xerox Alto 计算机实现的,Alan Kay 等人设计了 GUI 软件界面以及相应的操作工具:鼠标。此时工程师们意识到,传统的线性应用程序遇到一个难题,即程序并不知道用户下一秒是要操作鼠标还是键盘,或者是其他操作。
于是 Dan Ingalls (也就是 Smalltalk 的设计者)提出了一种新的应用程序结构,主程序启动不再退出而是进入一个循环,循环中程序会轮询或等待中断调用。这个模式也称为 RunLoop 一直沿用到今天。
得益于那个时代面向对象理论的快速发展,开发者很快意识到,鼠标键盘输入和 IPC 消息等等都可以抽象成事件,操作系统只需要将事件发送给不同的应用(即多消息队列)就可以支持多任务,包括 MVC 这样的概念也就是那个时期就已经成熟了。后来 Smalltalk-80 将其抽象化成了今天熟知的 EventLoop 模式。
不过真正意义的“多任务”操作系统是很久之后的事情了。还记得之前提到的 2003 年 Linux 2.6 版本实现的所谓“抢占式”机制吗?所谓抢占式( Preemptive )就是与协作式( Cooperative )相对应的,协作式简单说就是应用程序自己才能决定退出,而抢占式指的是内核调度器可以主动打断并切换当前运行的进程。
这里我们能看出,内核的抢占式支持是基础,而操作系统的多消息队列同样重要。1995 年发布的 Windows 95 版本首先支持了图形界面抢占(仅限 32 位应用),每个 UI 线程都有一个独立的消息队列。而 Classic Mac OS 就一直只有协作式图形界面,直到 2001 年的 Mac OS X 10.0 使用了 XNU 内核之后才实现抢占式图形界面支持。
严格来说“抢占式内核”指的是当执行内核 syscall 的时候能否被打断,比如说执行某个慢 io 操作时,如果希望同时播放音频,在非抢占式内核上就要等之前的 syscall 调用完成,在抢占式内核上当之前的 syscall 时间片到期后,播放音频的指令就可以被执行。也就是说,即便是非抢占式内核,也可以实现抢占式的图形界面逻辑,只是一般来说图形界面要求低延迟,在抢占式内核上这样做才有意义。
对于 Linux 来说,由于它从第一天起就没有专属的图形界面,很长一段时间中 X 就是事实上的图形界面标准。所以是否能支持抢占式图形界面,完全取决于 X 自己的实现。由于 X Server 只是一个运行在用户空间的应用程序,而内部的消息队列又是基于 socket 实现的,所以天然就获得了图形界面的抢占式特性。
技术层面它是两个原因的共同结果,一方面是底层 IPC 走的是 socket ,在内核侧是有缓冲的,另一方面 X 设计为 C/S 架构,单个 Client 阻塞绝大多数时间不会造成 Server 的阻塞。这里就不展开讲了。
之所以 Windows 95 没有实现 16 位应用的抢占式图形系统支持,是因为早期基于协作式多任务的应用程序代码,在抢占式环境中不是线程安全的。Classic Mac OS 也有类似的问题,所以后来 Mac OS X 10.0 之后就放弃支持完全重做了。
0x32 图形应用到底应该怎么写?
在协作式时代,没有操作系统层面的调度器,那应用程序可以随便写,反正在应用程序主动交出控制权之前,内存和图形库也是全局独占的,不需要考虑线程安全的事情。
到了抢占式时代,操作系统的设计者要考虑的问题就变成了:如何解决线程安全的问题?
回到之前提到的设计者思考路径:
很明显 Run/Event Loop 的模式是不会变的;
最好还能保持协作式时代的写法,而且让应用侧去控制显存锁不合理也不现实;
内核侧应该主动去控制显存锁,这样某个时刻就只有一个应用在访问显存,但这样就会导致大量用户态和内核态之间的上下文切换;
内核为了隔离和安全,并不想将内部 IPC 机制完全暴露,所以要通过某种协议提供用户态的高级封装,供应用程序来调用。这个 IPC 机制可以不局限于图形界面绘制,也可以一般化为应用程序之间的交互方式,但是性能要好。
绕了这么一大圈,终于回到了 IPC 的话题上。不过这个逻辑是我本人的推理,并没有哪个知名人士以访谈或者回忆录等形式记述这段历史发展历程。
关于图形系统的部分再稍微补充一点,其他留到之后的章节再讨论。
现代图形系统的核心逻辑是合成器模式,每个应用程序在自己私有内存空间中进行绘图,由操作系统提供的合成器按需合成后交给显卡现实。在 2000 年之前是不具备这个条件的,因为当时的电脑内存太小了,整个系统只能保留一个公共的显存,无法让每个应用都有自己的绘制空间。所以当时的图形系统核心是失效重绘的模式,即内核维护显示输出的失效状态,然后调用对应的应用程序对失效部分进行重绘。
0x33 IPC 的世界观
以今天的眼光来看,IPC 机制本质上就是一套协议,这套协议在内核语境下,应该具备以下特性:
载荷无关( Payload Agnostic ),即 IPC 的信息传递对于内核来说是透明的,解析是由 IPC 通信的参与者完成。
异步交互( Async Interaction ),描述的是 IPC 调用的时空边界。可以通过底层异步来模拟同步调用,但需要明确它的执行代价(和 RPC 做区分)。
能力导向( Capability Oriented ),主要说的是 IPC 调用的安全边界,声明式的权限控制是目前实现容器化安全的底层机制。
这里描述的是通用的设计通用通信协议的一般原则。这是全世界的开发者们用了几十年时间,在各个领域进行了不同的尝试,如今总结出来了经验教训。注意这里描述的是一般设计原则,并非实现技术。从技术层面上说,同一种目标可以有很多不同的实现手段。
实践中可以在实现层面,为了达到特定目的而做一些不完全符合设计原则的调整,但一定要清楚它的代价。还是之前那句话,取舍是一种智慧,不能既要又要。这样说可能不是很好理解,我这里就专门列举一下,那些曾经的设计失误,以及由此产生的后果。
“不要误会,我不是要针对谁,我是说在座的各位……”
0x34 混乱的 D-Bus
D-Bus 诞生于 2002 年,这里 D 的意思是 Desktop 桌面。这个协议基本上是 GNOME 桌面的人开发的,是的,还是 Red Hat 的人。这个协议设计之初的目的是替代 KDE 的 DCOP 协议,以方便移除 Qt/X11 等依赖。(实际上目前 Freedesktop.org(Fd.o) 旗下的 systemd/Wayland/NetworkManager/PulseAudio/PipeWire 也都是红帽的人在主力维护)
如果你没有基于 D-Bus 写过代码,可能不太好理解 D-Bus 的工作原理。简单说它是一个消息总线,任何程序可以注册任意对象,也可以在任意时间用任意方式去访问总线上的任意对象。你看我用了这么多“任意”,应该能猜到这是一个鼓励“动态化”的协议。(技术上是通过发送消息的方式实现的,而不是调用函数,这里为了方便描述简化了)
所以它就选择了 XML 作为交换格式( 2002 年的时候还没有 JSON 什么事)。按照协议设想,应用程序或者说服务方要主动声明自己具有哪些能力,方便其他应用使用,这个机制叫做 Introspection 自省。如果调用特定的自省接口,就可以通过 XML 获得所有接口以及对应的能力。(准确说 XML 只用于接口自省,实际上传输的数据 WireFormat 是二进制的)
听起来很美好是吗?实际上无论是 D-Bus/DCOP 都是 NeXTSTEP/Smalltalk 思想的延伸。D-Bus 设想中的自己,应该是和 macOS 上“服务”一样的效果,应用程序可以枚举出当前系统所有能够提供功能的服务端,然后调用对应的功能。然而现实是 Linux 生态极其碎片化,同时工具链支持也非常弱,就导致了完全不一样的效果。
桌面开发大部分时间都是用 C/C++ 的,实现一个 XML 解析是非常痛苦的事情。2002 前后可没有 GitHub 这样的服务,C 生态中造轮子是常态。GNOME 为了解决这个问题,创造了 GObject/GVariant 类型系统,并提供了配套的代码生成工具。桌面应用开发者的工作可以不再解析 XML 而是用工具来生成。
但 XML 编写本来就麻烦,修改一次接口就要重新生成代码再编译,开发者们就开始找捷径,于是
a{sv} (Array of String-Variant)登场了。这玩意就是个字典,键是字符串,值是任意类型。传递一个a{sv}之后,整个世界清净了,再也不用每次改接口都重走一遍构建了。这样一来 XML 存在的意义也彻底没了,自此之后,什么 D-Bus 规范、Fd.o 白皮书都滚蛋吧,没人在意,也没人去写了,一切以约定为准。
我就想问问,“一切以约定为准”是不是听起来很耳熟,数组传数据结构是不是很爽,大家有没有在工作中干过类似的事情?只能说,大家都是草台班子,谁也别笑话谁。
当然 D-Bus 协议还有其他问题,主要是安全性方面的。最早的 D-Bus daemon 实现也全是坑,这个等以后专门再讲。相对来说,安全性是受限于时代性的,而且解决起来也不是那么困难。还有一点要注意,D-Bus 虽然是目前 Linux 桌面的实际 IPC 标准,但它却不在 Linux 内核中。
高情商的说法是,今天 Linux 桌面还能用,而且看起来跑得不错,D-Bus 的再实现起了关键性作用。换个说法,今天的碎片化程度,D-Bus 要先把锅背好。
我这里一定要提一个草台班子的事情。为什么我一直强调说,类似 LKML 这样的讨论比代码更有学习价值,就是因为对话和文字记录中可以看出来开发者是怎么想的,他为什么要做某种设计,这样的经验无比珍贵。因为经验这个事属于知道就是知道,而不知道就是不知道,不知道的情况下一定会重复踩别人踩过的坑。
目前的 MCP 协议,精神上和 D-Bus 没有任何不同,协议规范层面,就是用 JSON 代替了 XML 。而且得益于现代工具链,开发者偷懒的机会变少了。但是机制上,如果开发者都在 payload 中塞一个类似
a{sv}的字典,一样会完蛋。所以说不是用上现代技术就能避免设计上的误区了,编程这件事在哲学层面大致是相通的,人类世界的复杂程度并没有因为新技术而变得更高,反倒是设计理念这种理论会一直保持下去。
这一章节内容比较长所以分开了,后面还会接着锤其他的设计。
作者: kuanat | 发布时间: 2025-12-28 06:41
12. 请教一下 cursor 登不同账户那个 chat 历史记录还在吗
pro 账号每个月使用被限制 limit 了,打算再买一个新的 pro 续杯,有啥好的办法吗,买个新账号了这个历史记录还在吗😂
作者: NakanoAzure | 发布时间: 2025-12-28 03:29
13. 记录一下使用 AntiGravity 压榨 AI 开发一个 Android APP 的事情,并推广这个 APP
说在前面:关于节点的选择
我知道站内推广的东西应该放到推广节点,但是这不单单是一篇推广的文章,更像是一份给予 AI 高权限之后的心得体会记录(姑且可以成为“用后感”吧,哈哈)
为什么有这个想法?
关于 AI 的使用大家都有各自的原因,我这里就不过多赘述了,从刚开始的不信任,到现在的授予高权限,AI 的发展整体是向上并且超出我预期的,在公司也要求我们更多的将一些工作内容尝试交给 AI 完成,因此最近几个月来我用 AI 用的越来越多,这为 Pixel Meter 项目埋下了一开始的种子。
其实自从李跳跳不再维护开始,我是有想过自己写一个跳过广告的 APP ,为此我创建了仓库,参考一些别人博客的文章在开发自己的 APP ,但是从最开始的兴趣满满,到最后不想打开 IDE 写代码,一时兴起而产生的想法动力越发的不足,最后我放弃了,相信不少人都有过这样子的经历与体会(我不止是弃坑了这一个 app ,还有很多的东西都经历过这个流程)。
那时候我总觉得产生一个想法很简单,但是实现这个想法,哪怕是最开始的原型验证试水,对于个人来说成本还是太高了一些(毕竟需要花自己的空闲时间)。
同样的,这个周一开始( 2025 年 12 月 22 日起),我突然就想要在我的 Pixel 10 Pro 上面能够实时查看网速的显示。几年前玩过 Android (类)原生的玩家都知道,因为(类)原生系统都是毛坯房,所谓的设备维护者其实更多是因为他们自己在使用这部设备,因此维护者偶尔会添加他们认为应该有的东西,例如一些系统动画、CJK 字重、网速显示等。而这些东西,国产 Rom 基本都是自带,而我们 Pixel 用户要么不用,要么只能自己想办法了。
于是我开始寻找网速显示的一些 APP ,并就此询问了 Gemini 的一些推荐
(它居然在推荐列表里面把 Windows 的 TrafficMonitor 混进去,还告诉我说有 Android 版)。最终呢下载了几年前就在用的一些 APP ,当然都有缺点:
- NetSpeed Indicator:网速显示统计 VPN ,经典问题,流量数据翻倍(流量从 tun0 到网卡,计算的时候把所有网卡加起来,导致实际流量被重复计算)
- Internet Speed Meter Lite:统计数据粗略查看应该是没有重复,但是界面太老了,让我回想起了刚使用 Material Design 的感觉,免费版本带有广告,看着膈应,还塞进去了一个对我毫无卵用的流量统计功能
- Netspeed Indicator Magisk Module:要 ROOT 或者刷模块,直接 pass
- 其他的一些 app 以前没听过名字,现在也没兴趣一个个去试
突然,我有一个想法:为什么我不自己写一个?
因此我开始询问 AI ,被 Gemini 吹了一通彩虹屁
,我觉得自己突然行了
付诸实施
既然有了想法,加上没有太多空闲时间,因此这一次我打算给 Gemini 高权限,如果可以的话,让它从 0 开始生成代码,直到所有功能完成
于是,我开始和它进行架构设计的探讨(架构探讨并不是第一次,公司的一些项目我也在和 AI 进行架构设计),技术栈的选型
最终敲定了使用双模式的方案进行开发:普通模式尽量精准,不准也无所谓;高权限模式(借助 Shizuku )从数据源层面排除掉 VPN 网卡的流量数据,做到绝对的准确。
当然,这里我犯了一个错误,一开始我就应该在 AntiGravity 中发起会话的,这样 Gemini 能拿到完整的上下文直接开始生成代码,网页版 Gemini 则需要将这些“记忆”压缩成 md 文件再喂给 AntiGravity 。
压榨 AI
拿到这些压缩记忆的 md 文件之后,我通过 Android Studio 创建新项目,然后删除默认创建的一些测试依赖和测试类,使用 AntiGravity 打开项目,切到 Agent Manager 模式。
让 AI 根据这些压缩的记忆开始完善信息丢失的部分(信息在传递的过程中是会有丢失的),哪怕都是 Gemini ,毕竟是在两个地方打开,就像现实中的两个开发人员一样,同 A 沟通的内容,让 B 去做需要让 B 能够完全理解。这个步骤就是让 AI 根据文档对我发起反问,然后根据我的回答完善它的记忆以及文档。
具体的压榨过程就不一一描述了,扔个图就行,反正让它从昨晚工作到了现在(当然我睡觉的时候它也在“睡觉”),详细的一些方向性变更通过仓库提交记录也反映了出来。
整个使用过程我还觉得挺不错的,在这个过程中,我主要复杂代码审查和方向把控,代码审查是为了看它有没有按照我的想法进行编写,方向把控是为了纠正它可能出现的牛角尖状态,我觉得会话长了或者需要开启一个和当前任务关联性很小的需求,就单独开了一个会话。
到最后,整个项目 90%的代码(我手动写过一些代码,主要是审查以及纠正)、所有的文档内容( README 、ChangeLog 、隐私政策)、上架 Google Play 的一些说明内容(简短说明、详细说明,甚至置顶大图) 都是让 Gemini 生成的。
用后感
和两年前我开发 SkipperL (跳广告的项目,已归档) 相比,AI 发展的太快了。两年前我还在为快速消退的热情而觉得可惜,两年后我们完全可以让 AI 帮助我们短时间内完成原型的验证,甚至完成开发!
项目推广
最后推广一下让 Gemini 做的这个项目吧: Pixel Meter
(是的,它甚至是开源的)Pixel Meter 是一款专为 Google Pixel 和原生 Android 设备设计的网速监控应用。它可以解决在使用 VPN 时,传统网速显示应用因同时统计物理接口和虚拟接口流量而导致显示速度翻倍的问题。
它和那些老前辈相比,除了更加现代化的 UI 界面之外,更重要的是使用标准的 API 解决了 VPN 网卡的流量计算问题(没有使用 Shizuku )。
核心原理就是
TrafficStats.getRxBytes(ifaceName)这个从Android S新增的 API ,它允许 app 获取指定网卡的流量数据,因此我们只需要遍历所有网卡,然后排除 VPN 网卡就行了,整体用起来达到的效果是:有TrafficStats的效率,有NetworkStatsManager的精准。旧版本 API 的局限性:
- 老版本中只有
TrafficStats.getTotalRxBytes()和TrafficStats.getTotalTxBytes()函数,获取到的数据已经包含了重复计算的部分,但是这个 API 响应快,计算差值也方便- 而
NetworkStatsManager并不适合用差值来计算网速,因为这个 API 主要用来统计流量,它是隔一段时间将数据写入,所以用起来的时候会出现一些奇怪的情况:上一秒流量显示正常,下一秒流量为 0 ,具体原因如下:
解决了数据源的问题之后,另一个难受的点是:网速显示太小了,虽然我们使用了绘制 Bitmap 的方案实时生成一个“通知图标”,但是这个图标的区域太小了,勉强只能看清楚数字,而单位很不清楚(一众老前辈都是用的这个方案)。另一个展示的方案是悬浮窗,这倒是能解决大小问题,但是会带来一个讨厌的顽固通知“XXX 正在其他应用的上层显示内容”
而 Pixel Meter 带来了一个创新的展示方案:Live Update Notification
这还是我在查阅关于发送通知的相关 API 的时候,偶尔看到的,实时活动+比通知图标宽 的两大优势,让我瞬间觉得,这就是应用层最适合网速显示场景的东西,因此,我开始让 AI 基于此进行代码开发。
另一个大的改变是:我懒得适配旧版本的系统
(旧版本系统就用老旧 APP 足够了,反正都用不了实时活动),并且这东西优先向我进行适配,因此我将项目的 MinSDK 设置为了 36 。(旧版本如果有需要可以自行 fork 进行修改,符合开源协议即可)
)
而推广的目的,除了让大家知道这个方案之外,也是为了上架 Google Play 需要大家一起进行 14 天的封闭测试,期间收到邀请的账号才能够下载 APP ,感兴趣的小伙伴可以留下你们的 Google 账号,也可以通过邮箱发送给我。
邮箱地址:
bXlzdGVyeTBkeWw1MjBAZ21haWwuY29t本文同步发布: https://blog.mystery0.vip/archives/ai_power_for_pixel_meter





作者: Mystery0 | 发布时间: 2025-12-27 16:34
14. 谁知道怎样把与 Grok 的对话内容导出来?
chatgpt 有个导出功能,我在 grok 里找了半天没找到,谁知道怎么搞啊?
作者: red13 | 发布时间: 2025-12-28 12:37
15. 基于 casdoor 的 ELK 开源登录认证解决方案: elk-auth-casdoor
前言
ELK 的一大缺点就是这东西最初是没有登录机制的,只要拿到了 url 地址,kibana 看板谁都可以访问一下。后来 ELK 自带了一套 xpack 进行登录认证,可是除了账户名密码登录这种最原始的方法,剩下的高级功能,比如 oauth, oidc, ldap ,统统都是收费的…..总不能给每个人都专门搞一个 kibana 账户名密码吧……
所以呢,这里有一个基于 casdoor 的 elk 鉴权解决方案,不要钱,开源的,还有人维护呢~。Casdoor 是一个基于 OAuth 2.0 / OIDC 的 UI 优先集中认证 / 单点登录 (SSO) 平台,而 casdoor/elk-auth-casdoor 这套解决方案,则是一个 反向代理,他可以拦截所有未经登录的前往 elk 的 http 访问流量,并且引导未登录用户进行登录,而且这个反向代理对已登录用户是完全透明 的。
仓库地址 https://github.com/casdoor/elk-auth-casdoor
QQ 群:645200447
如果您有更多相关的特殊需求可以加群,我们会有专人对接~ (可以联系 ComradeProgrammer )
casdoor 是什么
Casdoor 是一个基于 OAuth 2.0 / OIDC 的 UI 优先集中认证 / 单点登录 (SSO) 平台,简单点说,就是 Casdoor 可以帮你解决 用户管理 的难题,你无需开发用户登录注册等与用户鉴权相关的一系列功能,只需几个步骤,简单配置,与你的主应用配合,便可完全托管你的用户模块,简单省心,功能强大。
仓库地址: https://github.com/casbin/casdoor
演示地址: https://door.casbin.com/
官网文档: https://casdoor.org/
QQ 群:645200447
Casdoor 还支持 ldap ,saml 等诸多功能…..
Casdoor 目前作为 Casbin 社区项目统一使用的鉴权平台,项目已开源,希望得到大家的一些建议和 Star~,我们会及时跟进反馈并改正问题哒
Casdoor 又有哪些特性?
- 支持普通的账户密码注册登录,也支持各种常见的第三方认证,例如 GitHub 、Facebook 、Google 、Wechat 、QQ 、LinkedIn 等等,截止目前共 9 个平台,并在不断听取用户建议对更多的平台提供支持。
- 管理方便。Casdoor 内部将模块分为了 5 大类,Organization 、User 、Application 、Token 和 Provider 。可以同时接入多个组织,组织下有不同应用,用户可以通过应用或组织分类,单独管理任何组织、应用或用户的 Token 令牌,轻松管理复杂系统,目前已部署在 Casbin 社区各种系统当作鉴权平台。
- 自定义程度高。Casdoor 可以随意修改登录方式,例如是否允许密码或第三方登录,自定义应用的注册项数量,是否启用两步验证,以及是否允许各个 Provider 登录、注册等等,高度可插拔。
- 具备 Swagger API 文档。清晰的 API 介绍,无需阅读源代码即可直接方便调用各个 API 接口,提供定制化功能。
- 前后端分离架构,部署简单。作为统一认证平台,除了性能,稳定性,新特性之外,易用性也是考量的重要标准,Casdoor 后端使用 Golang 语言开发,前端使用 React.js 框架,使用者只需启动后端服务,并将前端工程文件打包,即可直接使用,操作简单,上手难度低。 …
作者: Casbin | 发布时间: 2024-03-08 02:33
16. 为什么使用 Tomcat 算违反国产化要求,但是使用 Netty 却不算。
RT. 都是海外的开源软件,licence 也都是一样的。
背景
项目上遇到了相关的需求,要求包里不能有 Tomcat 。
公司上面给的方案却是让换成 Netty 而不是打成 war 包来接入客户提供的国产化 web 服务器。
由于之前是 spring-web ,阻塞式的,改成 netty 工作量巨大。是不是因为 Tomcat 有 TongWeb 这种国产替代。但是国内没人做 Netty 的替代。
所以 Tomcat 才会上黑名单,但是 Netty 就活着。
作者: MelodYi | 发布时间: 2025-12-27 02:55
17. 什么姿势可以做到 [实时访谈副驾驶] 实时提醒我对面的回答跑偏了/我下一个该问什么了
你是我的 [实时访谈副驾驶] 。 我正在和一位从业者的人进行付费咨询。 你的任务是:
- 从她的回答中识别 [关键决策点 / 判断规则 / 隐含假设]
- 实时告诉我:
- 我下一步最值得追问的问题是什么
- 是追「为什么 / 如何判断 / 当时怎么选 / 如果重来」
- 如果她的信息密度下降,提醒我换角度 请只给我 [下一问建议] ,不要总结。
我只能想到用讯飞听见手动 5 分钟把生成的字幕复制到一个聊天里…有没有什么自动化的姿势?
作者: HuPu | 发布时间: 2025-12-28 06:26
18. 荣耀笔记本与 Linux - 性能管理
这两天在 2024 独显版的MagicBook 16 Pro ( U5 125H + 4060 mobile )上装了Fedora 43 Workstation ,安装过程很顺利,驱动基本都自动装上了。
现在唯一有个问题:不知道怎么调整高性能模式
所有游戏一启动独显功耗在 40W 左右波动,一分钟左右掉到 20W ,整个系统都卡起来了。tuned ,nvidia-smi 设置频率,gamescope 都试过了,基本没啥影响。我能确定不是兼容层或 Wayland 的问题,因为 Minecraft ( OpenGL )也会卡,也试过 mint 但没效果。
Fn + P 是笔记本调整性能模式的快捷键,也是我唯一能复现的提高 GPU 功率的方法,不过提高后不到一分钟又会掉下去。按这个快捷键的时候能通过
acpi_listen看到wmi PNP0C14:03 000000a0 00000000,不过我没有找到任何有用的 acpi 接口。其他基本的因素也考虑过:RAM 基本没超过 2/3 ,CPU 没降频也没满载,iGPU 基本是空闲。
我还去问了荣耀客服,让我留电话和邮箱说之后有工程师回复我,最后就等来了 “关于您反馈的在 linux 系统下的性能调度怎么调整问题我们已收到, 目前是未核实到相关信息和相关功能。”
要是有高人看到这里能指点一下,我将感激万分。
闲谈
不玩游戏的话,系统用起来没啥毛病。装了达芬奇还没试性能如何,估计跟游戏差不多拉跨。之后再装 linux 的话,笔记本电脑还是慎重考虑吧,尤其是喜欢搞自研的这几家。
我唯一舍不得的应用是 OneNote ,我想要能书写的笔记软件,要是各位有用过的话能推荐几个吗?或者如何在 linux 上用 OneNote ?
作者: PeterTerpe | 发布时间: 2025-12-27 06:57
19. BMad v6 实战过程全公开: 32 场对话揭秘人机协作怎么搞?
“如果你也想了解 AI 真正如何参与软件开发,这个网站或许能给你一些启发。”
最近,我完成了一个叫 AutoQA-Agent 的项目开发。和以往不同的是,这次我全程使用 BMad v6 这套 AI 驱动开发方法 ,让 AI Agent 像真正的团队成员一样参与协作——从架构设计到功能实现,从代码重构到问题排查,每一个关键环节都留下了对话记录。
整理下来,一共有 32 个完整的对话 。
我觉得这些对话太有价值了,它们真实记录了 AI 如何像一个”技术合伙人”一样参与开发。于是,我用 Lovable 把它们做成了一个网站:
网站里有什么?
这 32 个对话记录覆盖了软件开发的方方面面:
🏗️ 架构设计
- 如何与 AI 架构师 Winston 协作创建架构文档
- 动态 Base URL 支持的方案讨论
- Epic 7 的重新设计
⚡ 功能开发
- 敏感测试数据注入
- Markdown Include 功能实现
- 应用探索引擎开发
- 智能测试用例生成器
🔧 代码重构
- 测试生成环境变量重构
- Story 7.1 的实现重构
🐛 问题排查
- 浏览器闪烁问题
- 探索记录修复
- 定位器导出失败调试
📋 需求管理
- Story 2.10 、7.1 、8.1 、8.2 、8.3 的创建
为什么要分享?
随着 AI coding 越来越火,很多人问我: “AI 真的能写代码吗?”
但我发现,更值得关注的问题是: “人和 AI 应该如何协作开发?”
这个网站就是我的实践答案。它不是”AI 帮我写完了代码”的炫耀,而是真实展示了:
- AI 如何帮我梳理技术选型
- 当遇到问题时,我们如何共同排查
- 代码重构时,AI 提供了哪些视角
- 哪些地方 AI 表现出色,哪些地方仍需人工把关
BMad v6 是什么?
BMad v6 是一套 AI 驱动的开发方法论( Business Model AI Development )。它的核心思想是:
把开发过程拆解成不同的”专家角色”,每个角色各司其职,你就像项目负责人一样协调这些 AI 专家协作。
比如这次 AutoQA-Agent 项目中,我就和这些 AI 角色协作过:
- Winston (架构师) :负责架构设计和技术决策
- Dev (开发者) :负责功能实现和代码编写
- PM (产品经理) :负责需求分析和 Story 拆解
- QA (测试工程师) :负责测试用例设计
就像组了一支 AI 团队,你带着他们一起把项目做出来。
网站背后的技术
这个网站本身也很有意思——我用 Lovable 快速搭建了整个界面:
- 简洁的对话列表,每个对话都有清晰的分类标签
- 一键跳转到对应的对话详情
- 响应式设计,手机上也能流畅浏览
- 部署在 lovable.app ,访问速度飞快
谁会从中受益?
如果你是:
- 开发者 :看看 AI 实际如何参与项目开发
- 产品经理 :了解 AI 辅助需求管理的可能性
- 技术管理者 :思考团队如何引入 AI 协作流程
- AI 爱好者 :真实案例总是比抽象讨论更有启发性
希望这个网站能给你一些参考。
最后的话
AI 不会取代开发者,但会使用 AI 的开发者 可能会超越不会使用的。
这 32 个对话,是我探索”人机协作开发”的第一步,也是 BMad v6 方法论的一次完整实践。如果你也在路上,欢迎交流。
项目地址: github.com/terryso/AutoQA-Agent
对话网站: autoqa-chats.lovable.app
你在开发中有和 AI 协作的经验吗?欢迎在评论区分享你的故事。
作者: terryso | 发布时间: 2025-12-28 01:23
20. antigravity 打开了自动化执行命令, 为啥还要老是停下了
想做甩手掌柜啊
我打开了命令行
always proceed我只在 deny 列表添加了
rm我希望除了删除文件需要我批准, 其他都自动得了
现在好像还是不行, 经常会停下来
我想 ai 牛马干活, 不要我管, 干完告诉我就行, 我看剧看 B 站
作者: iorilu | 发布时间: 2025-12-28 02:41
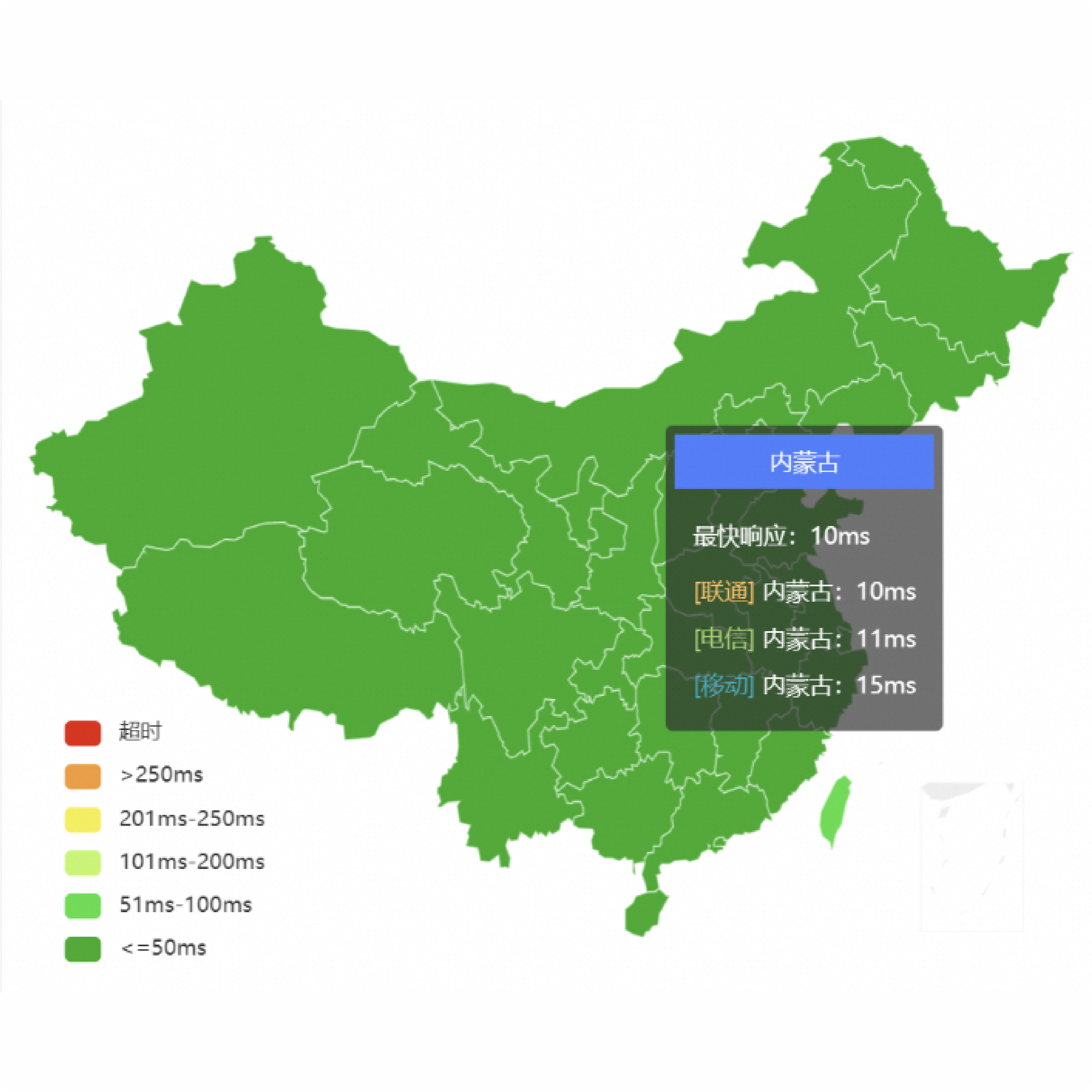
21. 阿里云也有免费 CDN 了,支持国内区域加速还是无限流量
ESA Entrance 版套餐免费,不限量不限速、直接注册账号就能免费用,我一直续费到了 2050 年 我注册的是国际版,国内版的支持大陆地区的优化加速 之前一直用的 Cloudflare ,但是 Cloudflared 的速度在国内真是一言难尽,时不时还会有阻断的问题,阿里云的套餐我自己实测下来速度还是不错的,个人用完全足够了,Cloudflare 的常用功能阿里云 ESA 都有支持
同时还支持部署 Pages 的功能,ESA 免费领取链接: http://s.tb.cn/e6.0Fu67m
作者: Aliesz | 发布时间: 2025-12-27 14:10
22. 用了十几年的 MySQL 了,突然发现 PostgreSQL 可能更加适合我,大家怎么看?
从 13 年毕业开始就开始使用 MySQL ,当时不理解 DBA 把用户表分成了 100 张,后来在别人的一通解释下也渐渐理解了。
17 年自己开始作为主程负责一个新项目,当时因为把用户表分成 100 张还跟老板吵过架(因为当时另外一个项目的负责人本身就是个混混,还给老板一通乱说,弄的我特别郁闷,无奈自己当时的心理素质不是特别强大)。后来我也觉得 100 张表可能太多了,可能没有那么多用户,索性就只分了十张。
20 年新的项目,开始尝试使用 MongoDB ,经别人推荐,说 MongoDB 怎么适合游戏。当时觉得这东西好啊,但是在实际使用时,并不是那么美好。
24 年另外一个项目,负责人全部使用了 MongoDB ,但是用法相当暴力,也就是每次全量存储用户的数量到 MongoDB 中,感觉跟使用 MySQL 也没有什么实质性的区别。
今年负责另外一个项目时,最开始设计者将用户的 JSON 数据先进行 base64 encode ,然后异或加密存储到了 MySQL 中。因为最开始的客户端的设计是纯单机,后面加了服务器存储用户的存档而已。
新的需求是要将这个单机版本做成一个联网版本,因为我之前有将单机变成联网的成功经验(某合成游戏变成联网版本,国内流水过五亿)。
现在的存储结构没有规划过,JSON 结构下面有超过 200 个字段,活动配置占用超过了 90% 的存储以上,平均用户的存储占用在 100KB 以上。 存档中存储活动配置的原因:活动开启之后,则配置不再发生变化。
我重新设计了存储结构,使用 Protobuf 重新设计了数据存储,将活动配置数据跟游戏存档分离。活动配置单独存档在一张配置表,用户的存储中只记录对应的唯一 ID 。同时提供了接口,可能将旧的数据转换为新的 Protobuf 存储结构。
用户的数据存储中,使用 JSON 存储,存储的内容为 Protobuf 对应的 JSON 数据。用户更新数据时,提供了 FieldMask 仅修改部分数据(只前每次都是全量更新)。
当这个版本成功上线之后,我发现某些接口调用比较慢,例如在用户转换存档时,我将客户端提供的原始数据、转换之后的结果存储到了
conversion_logs配置表(数据类型均为 JSON ),内网的虚拟机上平均耗时为 200ms 。因为最近在研究 PostgreSQL ,索性就试了一下性能对比,结果 PG 只需要 20ms 左右。最关键的是,表空间存储的占用上,PG 远低于 MySQL ,因为 PG 存储使用的类型为 JSONB 。我尝试对比纯 TEXT 字段的记录时,PG 占用的空间也只有 MySQL 的 1/3 ,现在的数据表现就是在存储和插入速度 MySQL 远低于 PG 。更新的速度还没有完全验证。
SELECT table_name, ROUND((data_length + index_length) / 1024 / 1024, 2) AS total_mb, ROUND(data_length / 1024 / 1024, 2) AS data_mb, ROUND(index_length / 1024 / 1024, 2) AS index_mb FROM information_schema.tables WHERE table_schema = 'merge_island' AND table_name IN ('conversion_logs','game_saves','activity_saves','activity_config'); +-----------------+----------+---------+----------+ | TABLE_NAME | total_mb | data_mb | index_mb | +-----------------+----------+---------+----------+ | activity_config | 216.83 | 209.55 | 7.28 | | activity_saves | 0.16 | 0.16 | 0.00 | | conversion_logs | 70.55 | 70.52 | 0.03 | | game_saves | 7.48 | 7.39 | 0.09 | +-----------------+----------+---------+----------+ SELECT relname AS table_name, pg_size_pretty(pg_total_relation_size(relid)) AS total_size FROM pg_catalog.pg_statio_user_tables WHERE relname IN ('conversion_logs','game_saves','activity_saves','activity_config'); table_name | total_size -----------------+------------ activity_config | 32 MB activity_saves | 376 kB conversion_logs | 13 MB game_saves | 1976 kB另外把用户分为 100 张的操作在 PG 这里完全是反模式的,因为 PG 号称单表轻松过亿。另外十多年前的老设计本应该也要被淘汰了,毕竟现在都是云服务,空间存储可以轻松扩充,不用再担心这个问题。
有没有使用 PG 淘汰 MySQL 的大佬来分享一下自己的经历,一起学习哈。
作者: Rooger | 发布时间: 2025-12-27 02:54
23. vibe coding 生成的 UI 界面很丑怎么办?
我虽然不会设计但是我就觉得很丑,就是那种很明显的 ai 味道,有什么好的提示词或者好的工具或者网站,能帮助我生成漂亮一点的 UI 吗?
作者: punny | 发布时间: 2025-12-27 16:25
24. Flclash 这个规则执行好像不严格
我对 adobe 全家桶的域名都是采取的 REJECT 规则,原因大家明白。平时都用的 clash verge ,换了 Flclash 试试感觉,刚开始感觉挺清爽,结果一打开 ps 就被发现了。同样规则用 verge 就没事。不知道列位有没有遇到这个问题,也不知道其他规则是不是也没遵守,流量会不会是在瞎跑的。
作者: glouhao | 发布时间: 2025-12-28 01:35
25. [分享] 我整理了 200+ 个高质量 RSS 订阅源(涵盖科技/独立博客/新媒体)
体验地址:hot.uihash.com 整理的数据源大部份都是有检验更新日期,大部份博客还是值得收藏,丰富了平台数据;(上次有小伙伴反馈要看外网新闻的,现在也是可以的,至少都是科技,开发类的 rss ),本来测试了国外很多网站,包括 youtube 都可以添加,懂的都懂,但是为了规避风险,还是禁用了,不过大家可以自行部署 RSS: https://github.com/sundt/uihash-hotnews/blob/main/rss_feeds.csv gitee: https://gitee.com/david-sunny/hotnews github: https://github.com/sundt/uihash-hotnews
下一步目标: 将微信公众号纳入进来,然后 RSS 不断更新,这样你就可以选择自己想看的了,不被算法裹挟;
作者: David666 | 发布时间: 2025-12-27 12:41
26. 为什么创业不要选择做面向程序员的产品
有很多程序员在用某一款产品的时候,发现了一些不爽的地方。然后心想:
“老子自己也会开发,为啥不自己弄一个,
说不定有很多人也有一样的需求,我做一个 XXX Plus ,肯定比现在这个 XXX 更牛逼,用的人更多。”于是,很多程序员创业时,第一想法都是做一个给程序员用的产品,包括但不限于:
- 一个开发框架
- 一个开发小工具
- 一个只有程序员才需要的 APP
如果不考虑盈利, 那你爱做啥就做啥,别人管不到。
但如果你指望着靠这些产品盈利,请三思而后行。因为:程序员是最难被赚钱的群体。
- 多数程序员都是打工心态。即使你的产品很好用,他也不可能高尚到“为了做老板的项目,而花自己的钱去买一个提效工具”。老板也不可能高尚到“为了牛马干活轻松,而多花一分钱”,因为他认为他已经付过工钱了
- 程序员是非常理性的群体,每一笔消费都是挑三拣四、反复对比过的。你确定你的产品能在对比中取胜?
- 程序员只会购买他这辈子都开发不出来、并且无法免费破解的产品(比如 AI 编程)。多数程序员的选择思路是:先找破解版;再找免费版平替;最后宁愿自己撸,也不可能让同行赚到钱(因为让其他程序员赚到钱了,等于承认其他程序员比自己牛逼,这是在侮辱自己)。
- 你以为程序员的需求是提升开发效率?不是的,程序员真正的需求是:”不用干活,又能赚很多钱“。
因此,当你现在创业想做面向程序员的产品时,务必三思。非行业巨头,不建议走这个路线。
作者: xuld | 发布时间: 2025-12-27 04:18
27. 就没有一个好用的 chrome/edge 下载扩展么?
去下载国外网盘的东西,浏览器自带的下载老是断开连接就傻傻的停在那里了。
本来想着去搞个插件,chrono download manager 结果也是停了就停了
接下来高血压的来了。网络风吹草动,就 kuang 提示一下下载出错。然后就没法接续了。
眼看着都下载了 50%了,点击重新开始,tnnd 给我重置为 0% 了。。
这年头下载工具连「断点续传」这种基操都不会了?
有没有无限自动重试+断点续传的扩展推荐?
太高血压了。
作者: est | 发布时间: 2025-12-27 15:08
28. Google 账号被停用是不是申诉也没用?
我怀疑是我手机号有毒,昨天更改了下密码,然后今天前面正常登入,后面跳出要手机号发个验证码验证,然后输入验证码后就给我停用了!!!
这 Google 账号敢用啊,直接给你封了。之前也封过一个,我这手机号就收了这俩账号的验证码,用了不到两年
作者: mingtdlb | 发布时间: 2025-12-27 06:55
29. 公有云对象存储计费疑云:一次普通的上传/下载 HTTP 请求产生多次读/写操作,请求次数按哪个算?
国内公有云的对象存储服务的 API 请求费用官网大多标价 1 元/百万次,但是这个计费的细则,今天核对了两家的流水账单才发现之前理解的一直都错的。
不考虑分片上传、多线程下载这些复杂的场景。就拿最普通的简单下载/上传来说,一次下载/上传 HTTP 请求在后台存储系统内部实际会产生多次读/写操作。
实际的请求费用计次是按 HTTP 请求次数算,还是存储系统内部内部的读/写次数来算?
之前我一直以为是前者,但从账单、后台数据统计与实际业务执行情况数据来分析,显然都与我之前理解的规则不符。
想探讨下目前公有云上各家的计费规则哪种更常用?一次下载请求,多少次读操作属于合理区间?不同的底层实现,计费差异是不是也挺大的?
作者: Adven | 发布时间: 2025-12-27 15:10
30. 求教一加 13 刷机后的 play integrity
最近把一加 13 解锁刷到 LineageOS 23, 在只安装 apatch 且不装任何 zygisk 或模块情况下,play integrity 的结果是”no integrity”
可是我的另外一个红米 note 12 turbo ,一模一样的设置,结果是 basic integrity.
想问下这个是我的设置有问题,还是传说中一加炸 tee 导致的呢?你们一加刷机后能保持 basic integrity 吗?
PS: basic integrity 对我来说够用了
作者: s82kd92l | 发布时间: 2025-12-27 11:21
31. 让 AI 带着镣铐跳舞
最近临时在帮朋友做一些外包,基本上代码都是 AI 写的,我想如果不是有 AI, 我大概不会帮这个忙,因为即使这些活不难,我还是要写很多代码。但现在,我可以一个人同时做 2-3 个项目。
在这个过程中,更加让我确定了对于程序员来说,软件开发的范式已经彻底彻底改变了。生成代码再也不是程序员「应该」做的事情,而是应该被放手给 AI 做的事。
这也让我对判断一个程序员的能力从代码能力转变成了使用 AI 的能力,我想,如果我现在要为团队招程序员,我会在面试时着重了解这个人如何使用 AI 完成一个需求。
对于程序员来说,「使用 AI 的能力」包含很多维度,这些维度综合起来,才决定 AI 是否真正能成为程序员的杠杆:
对业务的理解
软件是为解决用户的需求而生的,对业务充分理解,才能给 AI 足够的业务场景上下文,才能让 AI 写出覆盖边界条件的代码。
对业务的理解同时决定了程序员是否可以做好数据库建模。在接我朋友的外包项目时,我发现我人工干预最多的就是数据库建模。只要我思考好建模,AI 就能基于这个数据库模型编写任何接口。
对技术栈的理解
如果能让 AI 限定在特定的技术栈中,你会发现 AI 更能稳定发挥,更可控。让 AI 「带着镣铐跳舞」。无论用什么技术栈,重点都是给 AI 一条稳定的轨道。比如我在所有项目的 AGENT.md 中都会列出非常细节的选型,例如 CC Mate 的 https://github.com/djyde/ccmate/blob/main/CLAUDE.md
当 AI 知道技术栈后,通过 context7 这样的 MCP, 它能在生成代码时,找到对应的文档作为上下文,生成出更不容易出错的代码。换句话说,确定好技术栈,让 AI 成为这个技术栈的专家为你编写代码。
因此,在这个层面,程序员的「使用 AI 的能力」意味着,这个程序员知道什么样的场景适合什么样的技术栈,也侧面反映了这个程序员对技术社区是否保持敏锐的嗅觉。这是我认为 AI 时代程序员的一种硬实力。
对架构的理解
在《代码之外》听友线下见面会中,有听友提问,在 vibe coding 的时候,AI 只能做些一次性的软件,多次迭代后就会变成灾难。我的回答是,这是因为没有给 AI 提供一个你设计好的工程架构,让他在这个架构中行动。在这个新的时代,程序员应该以架构师的角度来工作。
我在 AI coding 一个项目前,我的脑海里会大概有一个工程架构的设计,比如,通用工具应该被统一放到一个什么文件,前端页面应该如何组织,接口应该遵循什么样的规范,错误处理应该怎么做等等。只要架构设计好,写在 AGENT.md 中,AI 自然会按照你的设计去做,而不是让 AI 天马行空地发挥。
不仅是在启动这个项目前要做好架构的思考,在维护的过程中,你指挥 AI 完成一个新的需求时,就应该思考完成这个需求的时候,将会有什么代码被写在哪一个地方。这个场景也适合使用各个 AI coding agent 的 Plan Mode 来完成,当 AI 告诉你它将要如何行动时,适当二次确认它要如何组织新的代码。
做到以上三个理解,我相信程序员可以游刃有余地使用 AI. 但我曾经在很多场合接触一些在一线写代码的程序员,发现他们对 AI 的接受程度是如此地低。很大程度上,我认为是一个缺乏以上三个理解的程序员,很难对 AI 建立信任关系,合作关系。
和我合作的一位程序员,在共同完成一个需求的时候,我在他旁边观察了一下他如何使用 AI, 结果只是非常浅地使用 auto complete. 我问他,为什么不尝试让 AI 完整地完成这个需求,他表示他认为 AI 不能胜任这个任务。
我说:
- 我的后端接口已经写好了,而且有了 openapi 的 YAML 文件( AI 生成的)
- 你知道这个需求涉及前端的哪个页面,在前端项目中,也有对数据请求层进行封装( AI 一定能知道怎么写数据请求)
满足了这两个条件,你只需要把接口文档给 AI, 然后告诉 AI 这次的需求,再告诉 AI 一点提示,大概是在哪个文件中修改。以现在旗舰模型的能力,AI 大概率能一次性完成。
他将信将疑,我直接在他电脑上给他演示这个操作,果然,AI 直接完美地完成了这个需求,不到 2 分钟。
而同时我也在思考,到底 AI 时代是否还需要程序员,或说需要怎样的程序员,好像渐渐有了答案。
作者: djyde | 发布时间: 2025-12-27 05:46
32. Gemini cli 怎么样?
最近趁优惠,充了 Google one 的年包( https://one.google.com/ai-nye)
以前用的 Claude code ,很好用。
后来切换到 codex ,有点慢,但是也还凑合。
现在准备切换到 Google AI 了,不知道 Gemini CLI 怎么样,有没有 v 友分享一下。或者有没有什么办法用 Claude code 调用 Gemini 模型?
作者: ninjaJ | 发布时间: 2025-12-27 13:18
33. 不喜欢 codex diff 的体验, 写了个 vscode diff 插件: diff tracker
Codex 的 diff 体验一直不顺手: 必须在独立面板里看 diff, 有时候 revert 甚至失败. 忍无可忍下, 写了一个新 vscode 插件解决这件事.
只要点一下 recording, 所有改动都会实时以 inline 形式呈现, 也支持双栏对比, 还能类似于 curosr 那样对局部改动进行 accept/revert.
这下 Codex 用起来舒服太多了
效果图:
Editor Inline View
Editor Inline View (hover effect)
Inline Review2 (read only)
Side-by-side diff
github 地址: https://github.com/wizyoung/DiffTracker
vscode marketplace: https://marketplace.visualstudio.com/items?itemName=Wizyoung.diff-tracker
openvsx marketplace: https://open-vsx.org/extension/Wizyoung/diff-tracker
一些局限: 因为 vscode 的 api 原因, 无法像第三方 cursor 那样, 在代码块右下角显示浮动的 accept/reject, 以及删除的 diff 下无法把删除前的内容以虚拟行的方式显示. 如有更好的方式望告知~




作者: frinstioAKL | 发布时间: 2025-12-27 13:28
34. 有必要把内网服务开放到公网吗?
我现有方案是开放到公网,在纠结要不要切换会内网,通过 Tailscale 访问。
作者: mssi | 发布时间: 2025-12-26 01:18
35. 从快手直播故障,看全景式业务监控势在必行!
近日,快手平台遭遇有组织的黑产攻击,大量直播间在短时间内被劫持用于传播违规内容。这一事件不仅造成了巨大的负面影响,更暴露了当前互联网平台在应对新型网络攻击时的脆弱性。在较长时间无法解决问题后,最终的解决方案竟然是完全关闭直播入口。我们在强烈谴责黑产违法犯罪行为的同时,行业必须清醒认识到:企业当前的防护模式,在面对高度规模化、组织化、自动化的“闪电战”时已力不从心,必须要对当前的防护体系进行全面升级。
本篇文章从技术层面阐述这一事件以及我对平台防护体系改进方案的个人观点,包括以下三方面内容:
- 1 、黑产的攻击链路;
- 2 、当前互联网平台防护体系现状;
- 3 、全景式业务监控势在必行;
黑产攻击的账号类型
由于平台尚没有详细披露本次被攻击的方式,我们只能从当前简单的陈述之中猜测黑产可能的攻击手法。
- 老账号被黑产部分盗取,并以老账号进行攻击;
攻击链路:钓鱼链接 → 获取老账号凭证 → 窃取有效会话 Token → 绕过二次验证 → 获取设备控制权 → 以”合法老用户”身份发起攻击。
- 黑产批量注册新账号,并绕过实名认证体系,以新账号进行攻击;
攻击链路:接码平台/卡商获取手机号 → 自动化脚本批量注册 → 伪造或绕过实名认证 → 养号(模拟正常行为)→ 等待时机发起攻击。
账号是攻击行为实施的载体,不同的账号类型攻击手法是不同的,产生的危害力也有差异:
一般来说,老账号拥有正常的注册时间、历史行为、社交关系、消费记录等,设备指纹和登录模式可能已通过平台信任白名单。风控系统会将其判定为“低风险用户”,极难触发警报,单个老账号攻击更具有迷惑性和危害性。不过黑产获取老账号凭证方式主要通过钓鱼链接、木马病毒或者撞库等手段实现,获取难度较高,账号数量规模应该不会太大。
而新账号没有历史行为、交易、社交关系等记录,历史评级很低,容易被系统风控方案判定为高风险账号,单个账号的攻击力相对较低。不过新账号攻击可能意味着黑产已经掌握了平台账号体系漏洞,而可以进行大批量注册形成规模化攻击,如果没有及时修补危害极大。
账号凭证是什么
账号凭证是一个广义的身份集合,包括登录账号(手机号/用户名)、密码(或其变种)、已登录态下的会话 Token/Cookie 、受信任设备指纹等信息。
什么叫伪造和绕过实名认证体系
现在企业广泛采用的实名认证体系是:用户首先提交身份证图片,然后打开手机,摄像头采集人脸视频信息,app 发出眨眼、张嘴等指令,在用户按指令进行上述操作后完成实名认证。
- 绕过实名认证体系
绕过实名认证体系也就是说黑产已经破解了当前平台认证接口的加密和签名验证等机制,可以直接发送”认证成功”这种篡改伪造的数据包到认证接口,从而绕过这一体系。
- 伪造实名认证体系
伪造实名认证体系是指黑产可以利用手机漏洞(比如:android 漏洞)在实名认证时直接注入预先准备好的人脸识别视频数据流。而这也意味着黑产已通过多种渠道获取到了大量的真实身份证图片,并根据上面的”照片”通过类似 deepfake 等技术手段预先生成眨眼、张嘴的认证视频片段。比如 App 发出”眨眼”的指令,就传入一个”眨眼”的视频片段,从而起到欺骗平台认证体系的作用。
伪造和绕过实名认证体系两者差异很大,修复漏洞的方式也截然不同。相对而言绕过实名认证体系对平台来说更容易修补,但如果黑产已经具备技术手段可以伪造实名认证体系,则潜在危害非常巨大,这就不在是一个互联网企业的问题而是所有互联网企业均要面对的问题。
黑产的攻击方式
流量劫持与内容注入
首先,介绍一下直播技术基本流程:
- 摄像头采集主播视频信息,将 1 桢的数据拆分成若干个数据包,每个数据包叫做一个 Chunk ,都包含 Key 、直播间 ID 、时间戳、设备指纹、IP 、视频流数据、加密验签信息、视频分辨率、码率等,将数据包压缩、编码后并上传到服务器;
- 只要开播,每个直播间的数据包( Chunk )会源源不断的上报;
- 服务端接收到 Chunk 进行转码并将连续数据包合并成视频片段;
- 所有直播间的视频片段汇总排队分发给审核机制;
- 视频片段首先经过 AI 机审进行违规信息检测评分,低于阈值直接放行,高于阈值则转入人审;
- 如果审核违规,则由审核人员进行封禁直播间的指令(当然也有自动化机制);
- 审核通过的视频片段则会放行,并再次转码为数据包并被用户拉取后看到;
上面是一个基本流程,真实环境中可能存在一些不同:
- 为了用户体验的流畅度,审核和分发流程也可能会并行处理;
- 由于人审的速度非常缓慢,在大量数据包积压时为了快速的完成当前的审核,审核人员也可能会”手动丢弃”积压的数据包;
- 平台账号体系会预先划分高风险、低风险账号,两类账号的审核逻辑略有差异;
在了解上面流程之后就知道黑产可针对多个环节通过不同的技术手段分别进行攻击。
什么叫做”预制违规视频”
这里的预制违规视频都是黑产特殊处理后的视频,而不是随便找的。也就说这些视频大多都是对”AI 机审大模型”有抗体的视频。黑产通过一些工具可以对视频的特征进行轻微调整,将原违规视频转化为”对抗性样本”,起到躲避被大模型识别的效果。
具体的攻击方式
黑产的攻击方式可分为多种,比如:
- 1 、攻击人员直接模拟平台推流协议将预制视频拆分成数据包上传,伪装成正常的数据包,这些数据包被 AI 大模型定义为低风险直接被放行;
- 2 、攻击人员可以前期探测出一个平台 AI 机审的大概阈值范围和人审的承载力,然后制作专门的视频造成人审的洪峰,从而直接压垮平台人审体系;
- 3 、攻击人员可以从技术层面绕开审核体系(不知道现行直播平台是否会有部分情况下无需审核的机制,而被黑产盗用,或者黑产使用老账号具有较高权重,无需严格审查);
- 4 、攻击人员可以间歇性发送”正常视频”和”违规视频”,大规模直播账号的正常视频可以压垮人审体系,另外也可以造成审核体系的错觉,获取基础信任,而通过对平台审核体系的承压探测,可以灵活调整违规视频的时长,比如 5 分钟的视频里面可能只有 10 秒钟是违规的,从而最大化攻击效果;
- 5 、攻击人员可以人为制造”举报”等核心接口的阻塞,从而让平台反馈体系失灵;
“肉鸡”的种类
由黑产直接控制的发动攻击的设备称为”肉鸡”,在移动互联网时代的肉鸡和 PC 时代的肉鸡已经有些不同。移动互联网时代的肉鸡可以分为多种:
- 1 、黑产直接控制了大量老账号原主人的手机设备(设备指纹和账号是完全绑定的,IP 地址非常分散,隐蔽性极高,难以被风控体系发现,但是控制原主人的手机非常困难,需要长期的”钓鱼”,控制成本极高,很难实现规模化攻击);
- 2 、黑产控制一批真实的设备农场,比如是从二手市场批量购买的廉价手机,这些设备是真实存在的,设备指纹等信息都完全真实(优势在于:设备完全真实,成本可控,可规模化部署,但 IP 地址一般相对集中、而且群体特征比较明显,相对容易被风控体系识别);
- 3 、黑产在服务器上批量部署 Android 模拟器,创建出来的虚拟设备(优势在于:成本很低,可规模化,但很多模拟器的设备指纹已经可以被识别出来);
- 4 、黑产控制一些不相干的用户手机,在手机内植入木马程序可以最小化、用户无感知的情况下运行 app 进行直播(优势在于:IP 地址非常分散,隐蔽性高,但同第一种一样控制成本比较高);
“肉鸡”的攻击形式
黑产通过中心化的系统来控制所有肉鸡,包括升级攻击脚本和下发指令。肉鸡的攻击形式可分为三种:
- 模拟真人操作进行攻击
也就是由脚本控制 app 的打开、关闭、处理弹窗、自动点击直播按钮进入直播页面,随后脚本将从摄像头采集视频改为推流协议直接上传。
- Hook 注入
Hook 注入是首先逆向破解 app 客户端内的代码执行逻辑,通过 Hook 技术手段直接侵入 app 进程之内,完全绕开 app 自身的 UI 逻辑,然后直接调用内部函数,通过篡改里面的参数传入实现违规视频的上传。
- 协议层请求
攻击者首先破解平台推流接口的加密验签逻辑,然后直接模拟 http 请求发送违规视频数据包。
一次完整网络攻击,会同时使用多种手段,而攻击者也可能在攻击前进行了数月的准备工作,也就是”养号”,在这期间会让账号进行正常的登录、浏览等操作,来让它的行为轨迹看起来很合理,从而提高账号的权重。
企业应该排查的优化点
应对网络攻击和网络攻击的溯源是多个部门互相协同的工作,而不仅是网安一个部门的职责,跨部门的协作、沟通、数据共享非常重要。
这一起网络攻击事件所需要排查的技术点和优化点很多,也都比较明显,比如几个相对重要的排查点:
- 推流接口协议的加密、验签逻辑的升级改造;
- 反馈等核心接口是否存在被人为阻塞和过载攻击的可能;
- 数据库中仍然可能存在潜在攻击者账号,如何进行辨别;
- 客户端是否存在被模拟真人操作的可能,需要增加必要的防护措施;
- 客户端代码是否存在被 Hook 注入的可能,需要提升代码混淆的等级以及增加必要的启动完整性校验等逻辑;
- 实名认证体系是否存在被绕过和伪造的可能;
- AI 机审的准确率提升;
- 账号等级的评估体系和风控体系所依赖特征是否足够广泛,特征的实时性是否满足需要; …
从”网络攻击事件”看企业数据化运营能力的不足和预警机制的缺失
这类网络攻击事件不仅暴露出企业自身防护体系的薄弱,更深层次地折射出企业在数据化运营能力和实时预警响应机制上的严重不足。其根本原因可归结为以下两点:
- 风控体系缺乏高质量的实时特征
风控系统所依赖的、能够准确反映“当前业务状态”的实时特征极为匮乏。这种“实时特征贫血”导致风控模型在面对新型或突发攻击时反应滞后、识别能力弱。此外,现有特征往往片面、零散,容易被黑产通过模式变异或一些技术手段欺骗。
- 缺乏跨部门、跨业务的实时协同指标,监控指标碎片化
网安团队在日常监控与应急响应中,缺少跨业务线、跨功能模块的“实时交叉指标”。没有这些全局性、关联性的数据指标作为决策依据,团队很难在攻击发生时快速定位问题根源,难以实现跨环节的联动防御。
全景式业务监控势在必行
什么是全景式业务监控
本文提出的全景式业务监控,是基于通用型流式大数据统计技术构建的新一代业务监控与预警体系。它突破了传统监控方案在实时性、覆盖面和关联分析上的局限,具备以下核心价值:
- 为管理层及决策者提供极高密度、多维度的实时业务指标体系;
- 为风控、账号等级评估等 AI 模型持续输送大批量、高质量、可关联的实时特征,提升模型训练的及时性与预测准确性;
- 实现从用户端到服务端、从业务触发到数据落盘的全链路可观测性。
相对而言,全景式业务监控更侧重于:全链路覆盖、多维度实时指标、跨系统数据关联和面向风控与决策的实时特征供给。
从一个简单业务场景看传统业务监控方案的不足
举一个例子:App 某页面有一个表单模块,表单提交后数据写入 DB ,我们要实时统计表单提交量,应该如何统计呢?
按照当前企业的做法毫无疑问是统计数据库的写入量。从业务逻辑层面来说这是完全没有问题的,但如果从业务监控的角度来说,假如这个业务较为重要,这种方案就存在着明显不足。
比如:
- 如何判断出数据是否存在接口被盗刷写入的可能呢?
- 如何判断出来后端接口是否响应正常,是否存在大量客户端请求异常的可能呢?
- 数据流转经过多个环节,如果线上出现数据异常等问题,如何快速的定位问题原因呢?
而更为规范的做法是:
- 客户端提交表单并上报日志,日志服务接收后消费日志进行数据统计;
- 后端接收请求后调用统计模块进行请求量统计;
- 后端服务在写入 DB 成功或失败后调用统计模块;
全景式业务监控提倡在一个业务的所有重要环节进行全链路监控,每个监控指标做到数据吻合。
从直播攻击场景,谈全景式业务监控的优势
网络攻击应急机制包括两个核心操作:1 、快速判断出黑产的攻击方式,2 、根据攻击方式的特征筛选出直播账号列表然后进行封禁。
全景式业务监控在这一过程中具有天然优势,比如:
- 协议破解与接口盗刷
这种攻击方式只要在 App 内推流数据包上传逻辑前添加监控埋点,并将埋点数据和推流接口的请求量数据进行比对,就可以明显判断出是否存在黑产盗刷接口的可能。而通过两方面的实时日志关联( App 埋点日志和接口服务日志)就可以快速初步筛选出黑产攻击账号列表。
- 肉鸡同时发动攻击
肉鸡为了击垮平台的”人审”体系,会在短时间内同时发起开播和推流,而这种操作也会形成前一刻和后一刻明显的流量异常,而通过关联两个时段的实时日志也可以初步筛选出攻击账号列表。
- 反馈接口过载攻击
反馈接口是否存在过载攻击,大多数情况下可以通过反馈接口服务监控埋点和 App 上报的反馈日志埋点进行对比分析,快速判断出过载攻击的可能,而且关联实时日志库可以提取攻击设备信息然后进行阻断。
从 App 启动、用户交互、开播按钮点击、推流接口调用、数据分发到内容审核,业务流程中充满各类细节与依赖。全景式业务监控旨在为企业构建一个“遍布全身”的实时指标感知网络,支持从整体业务层面到细分维度(如 App 版本、IP 段、设备指纹、直播间等)的立体化监控,全面提升企业对此类事件的应急响应能力。
通用型流式大数据技术介绍
目前之所以企业的”实时指标”和”实时特征”极为匮乏,根本原因在于指标获取所采用的技术方案仍然以:Flink 、Spark 、ClickHouse 、Doris..等技术实现,这些技术方案过于臃肿、笨重难以低成本、高效率的实现大批量实时指标。
而通用型流式大数据统计技术侧重于解决”大批量数据指标的并行计算问题”,擅长应对繁杂的实时指标计算场景,对于企业应急机制建立具有非常重要的实际意义。
可参考开源项目:xl-lighthouse ,开源地址: https://github.com/xl-xueling/xl-lighthouse
目前互联网大厂的数据指标数量可以达到 10 万
30 万个,而其中的实时指标数量更为匮乏,而通用型流式大数据统计技术可将大型企业数据指标数量提升到 1000 万3000 万个,帮助企业建立更完善的数据化运营体系,全方位提升企业对于紧急事件的应对能力!
作者: xueling | 发布时间: 2025-12-27 12:17
36. immich 有备份还是炸了
1 系统备份 pg 到文件,默认只保留最近 15 次备份文件
- 2 数据备份用的 sync ,会同步删除( DB 备份被删除,无法恢复)
作者: mintongcn | 发布时间: 2025-12-26 12:13
37. 安卓里面有没有那种非商业化的 9 格的输入法?
最近发现手机输入法打字候选词每次都要选,非常不智能。 但是每次新装输入法,感觉候选词功能都要好一些。 然后用上一些时间,又回去了。
然后电脑上是装的鼠须管,rime-ice 的词库,感觉还不错。 想着是不是能手机上也有类似的方式。
然后找了一圈发现有个同文输入法,然后发现输入法键盘不支持 9 格的。这个我年纪大了,不适应 26 格啊。 所以问问大佬们,安卓上有没有那种非商业化的支持 9 格那种。 要是能用上 rime 的词库,那就更好了。。。
作者: hefish | 发布时间: 2025-12-27 06:22
38. 有啥提供稳定可靠 TTS 的服务商?
自己有显卡跑 indextts2 ,但仅适用于自己玩玩。
想着有可靠的 indextts2 的服务商直接用他们的 api 来就方便了。
作者: ethusdt | 发布时间: 2025-12-27 04:39
39. 向朋友们推荐一下我的公众号《软件开发录》
自 2019 年步入互联网行业后,感觉自己什么都不会,就一直不断的学习,从 PC 的 C/C++ 客户端开发、Android 开发、Java 后端开发、前端 Vue 开发、跨平台的 Flutter 开发到用 Python 写脚本。学了很多很多东西,感觉什么都会一点,但又什么作品都没有。今年下半年想给自己做点玩具,不求做成什么事,但求不虚度。
公众号《软件开发录》也是此番心路历程的产物,会写一些工作和做玩具时值得一写的东西。
顺带推荐一下我的 Github: https://github.com/the-wind-is-rising-dev
现在只有两个仓库,自认为“Python 的 Flask 服务模版”还不错,统一 API 返回、日志、异常、JSON 编解码这些东西,请朋友们品鉴。
不知道大家喜欢什么,也不知道怎么推荐,下面贴一些公众号的文章标题吧,欢迎大家来公众号评论区玩。
《 Python 107 维音频+歌词特征提取, 可用于构建基于内容的音频推荐系统》
《 Python 批量发邮件脚本:Excel 名单 + Jinja2 模板,带日志与防限流,163 邮箱实测可用》
《 Flask 生产级模板:统一返回、日志、异常、JSON 编解码,开箱即用可扩展》
《 Jenkins + Kubernetes 多模块微服务一键流水线:从 Maven 打包到滚动发布完整脚本》
《 Kubernetes 生产入门:Deployment 与 Service 配置实战》
《 Flutter 多端音频控制台:基于 audio_service 实现 iOS 、Android 锁屏与通知中心播放控制》
《 Flutter 全局音频播放单例实现(附完整源码)——基于 just_audio 的零依赖方案》
《 Docker 一键部署指南:GitLab 、Nacos 、Redis 、MySQL 与 MinIO 全解析》
《 Python 自动化下载夸克网盘分享文件:基于 Playwright 的完整实现(含登录态持久化与提取码处理)》
《 20 分钟搞定:Jenkins + Docker 一键流水线,自动构建镜像并部署到远程服务器》
《 Docker 快速启动 Jenkins:挂载 Docker 权限与 Maven 缓存的完整实战指南》
作者: sojourner | 发布时间: 2025-12-27 08:50
40. 求助 prompt 样例搜集
我在设计一套 prompt 在不同模型里面迁移适配的方案,大概流程是原 prompt -> 中间件 -> 新模型可用的 prompt ,旨在减少迁移模型时的适配工作。
现在需要有原始 prompt 输入并进行验证,用 gemini 和 gpt 生成了几套尝试了一下,发现效果并不稳定。
所以求助大家,如果大家有现在正在稳定使用的 prompt ,可以将在用的模型+prompt 内容分享给我吗?
如果这套方案最终可行,我会再返回一个针对在用模型的新 prompt ,验证一下效果
感谢~
作者: ikooma | 发布时间: 2025-12-27 04:35