Hacker News 高赞评论 - 2025-08-10
1. canyon289在”Ask HN: ChatGPT如何服务7亿用户而我本地连一个GPT-4都跑不起来?”中的新评论
我每天都在谷歌从事这些系统的工作(免责声明:以下仅代表个人观点,不代表公司立场)。一方面我可以告诉你,确实有聪明人在深入思考这个问题的每个方面,但另一方面我也不能透露太多细节。
不过我可以分享同事写的这份资料!里面详细解释了加速器架构设计以及实现高性能的各种考量因素:
https://jax-ml.github.io/scaling-book/你特别关心的推理问题,正是这一章的重点内容:
https://jax-ml.github.io/scaling-book/inference/补充:另一个很棒的资源是unsloth指南。他们团队特别擅长深入分析各种模型并找出优化方案,而且文档写得非常出色。这是Gemma 3n的指南,你还能找到其他模型的优化方法:
https://docs.unsloth.ai/basics/gemma-3n-how-to-run-and-fine-tune...
作者: canyon289 | 发布于: 2025-08-08 19:47
2. 牛肉在”GPT-5”话题下发表新评论
或许我们无法通过随机文本预测模型来模拟更高层次的智能。
虽然我不是AI研究员,但有些朋友从事这个领域。他们并不担心基于大语言模型(LLM)的通用人工智能(AGI),因为随着训练数据量的增加,效果提升正在递减。这可能就是瓶颈所在。
人类智能与LLM有着显著差异:人类学习所需的样本量少得多,泛化能力也强得多。而LLM往往只是在复述训练数据中已有解决方案的问题答案,这些解决方案通常在训练数据中已被充分记录。
不过话说回来,要彻底改变世界,AGI并非必要条件。现有的AI/机器学习(ML)/监督学习(SL)技术中,可能有些应用比通用智能更具影响力。搜索引擎就是个好例子——能够从多领域复现知识正是其优势所在。
作者: beeflet | 发布于: 2025-08-07 18:17
3. 高频用户在”GPT-5”话题下发表新评论
经常有人提出,一旦某家AI公司突破通用人工智能(AGI)的门槛,就会甩开其他竞争者。但有趣的是,至少到目前为止趋势恰恰相反:随着时间的推移和模型性能的提升,各家公司的表现反而越来越接近。目前GPT-5、Claude Opus、Grok 4和Gemini 2.5 Pro在各方面表现都很出色(比如它们基本都能解决中等难度的数学和编程问题)。
作为用户,感觉这场竞赛从未像现在这样势均力敌。虽然外推可能不太严谨,但这让我对”硬起飞/赢家通吃”的主流观点产生了更多怀疑。
很想知道这些公司的研究员怎么看——你们预计未来几年竞争对手的AI产品会继续保持这种胶着状态,还是会拉开差距?
作者: highfrequency | 发布于: 2025-08-07 18:05
4. surround在”GPT-5”话题下的新评论
GPT-5的知识截止日期:2024年9月30日(发布前10个月)
对比来看:
Gemini 2.5 Pro的知识截止日期:2025年1月(发布前3个月)
Claude Opus 4.1的知识截止日期:2025年3月(发布前4个月)
https://platform.openai.com/docs/models/compare
https://deepmind.google/models/gemini/pro/
https://docs.anthropic.com/en/docs/about-claude/models/overv...
作者: surround | 发布于: 2025-08-07 17:53
5. peterdsharpe在”GPT-5”话题下的新评论
这完全错了。如果这个解释成立,平板翼型就不可能产生升力了(但实际上是可以的)。
来源:航空设计博士
作者: peterdsharpe | 发布于: 2025-08-07 17:43
6. pram在”GPT-5”话题下的新评论
我们现在正处于LLM的”发烧友阶段”,人们都在讨论模型如何改善了”声场表现”、”音色质感”,以及减少了”齿音失真”这类细节。
作者: pram | 发布于: 2025-08-07 17:19
7. mtlynch在”GPT-5”话题下的新评论
他们那个SWE基准测试图表是怎么回事?[0]
GPT-5非思考模式标注的准确率是52.8%,但o3显示的柱形却短得多,而它标注的是69.1%。4o的柱形和o3完全一样,标注的却是30.8%…
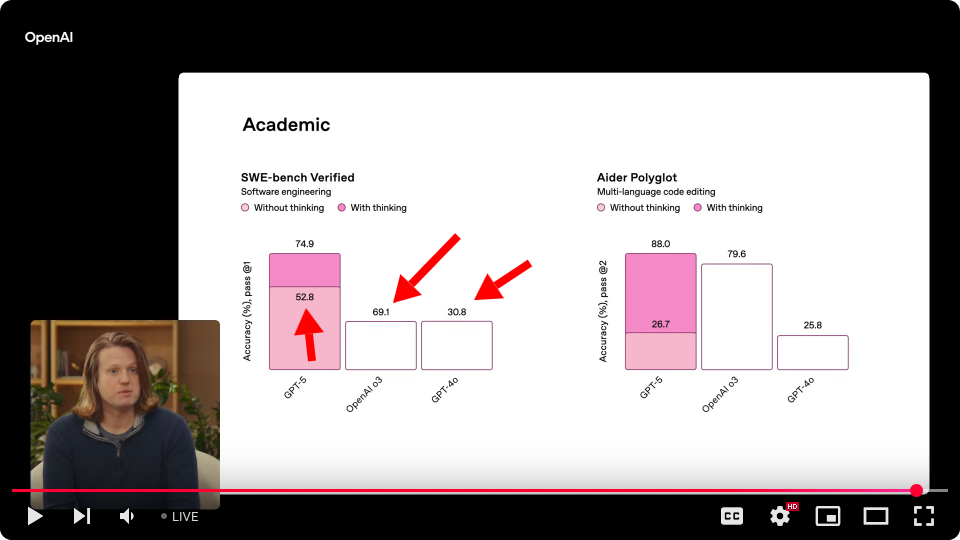{kind=link}
作者: mtlynch | 发布于: 2025-08-07 17:10
8. mmastrac在”Windows XP专业版”话题下的新评论
如何判断Windows或Mac的克隆UI是重新实现的?很简单:在弹出”发送到”菜单后,试着斜向移动鼠标。如果当鼠标划过菜单项进入子菜单时,”发送到”菜单就关闭了,那就是个克隆版。如果即使鼠标掠过其他菜单项菜单仍保持展开,那要么是原版,要么是个高仿克隆版。:)
想了解这段有趣的历史,可以看看@DonHopkins几年前发的帖子:
https://news.ycombinator.com/item?id=17404345
作者: mmastrac | 发布于: 2025-08-07 14:42
9. t_mann在”发送一次性验证码比密码更不安全”中的新评论
通行密钥(Passkeys)的问题比单纯丢失设备导致无法访问(实际上根据设置方式可以避免)要复杂得多。最严重的问题在于认证机制(attestations),它允许服务商封禁那些使用赋予用户更多自由工具的用户。通行密钥,或者更广义地说挑战-响应协议(challenge-response protocols),本可以成为密码的绝佳替代方案,实现双赢局面。但遗憾的是,实际设计方式注定了它们主要将用于进一步巩固科技巨头的垄断地位,剥夺用户自由。
作者: t_mann | 发布于: 2025-08-07 05:58
10. DecoPerson在”发送一次性验证码比密码更糟糕”中的新评论
这种攻击模式是:
用户访问恶意网站并注册账号
恶意网站提示:”我们已发送验证邮件,请输入6位验证码!邮件将由GOOD平台发出,因为他们是我们的登录合作伙伴。”
恶意网站的机器人使用用户邮箱在GOOD平台发起”邮件验证码登录”流程
GOOD平台向用户邮箱发送一次性登录验证码
用户极易信任这封邮件,因为确实来自GOOD平台——如果不是合法登录,GOOD怎么会发邮件呢?
用户在恶意网站输入验证码
恶意网站利用该验证码以用户身份登录GOOD平台,从而完全控制用户账户
这就是为什么”邮件发送验证码”是最容易被钓鱼的攻击方式之一。要阻止用户犯这个错误实在太难了。
“点击邮件中的链接”稍好一些,因为会直接跳转至GOOD官网,而要把这个链接转交给恶意网站则更麻烦、更可疑。但如果某些主流邮件服务突然屏蔽你的登录邮件或登录链接,就会导致大量用户无法登录。
通行密钥(Passkeys)才是未来方向。密码管理器对通行密钥的支持已经相当完善。我可以肯定地说,即使用户丢失手机导致所有通行密钥失效,也比当前密码系统面临的风险好千万倍。我宁愿让老奶奶去银行重新验证身份,也不愿看到她的账户被钓鱼者盗空。
作者: DecoPerson | 发布于: 2025-08-07 03:37
11. duskwuff在”9位字节会更有利”讨论中的新评论
从硬件角度来看,非2的幂次方尺寸设计会带来诸多不便。许多优化乘法器的设计方案都依赖于操作数能被二等分的特性,这在9位单元上就无法实现。此外,用固定位数表示位位置也很实用(例如3位表示0-7,5位表示0-31,6位表示0-63),这种表示法在位移操作或字节位选择时很常用;但换成9位就出问题了——你必须使用4位来表示,其中还会产生大量无效值。
作者: duskwuff | 发布于: 2025-08-06 21:27
12. hyperpape在《我们本不该需要锁文件》一文中发表新评论
但如果你想看一个现存的例子:Maven。Java库生态系统已经蓬勃发展了20年,在这期间我们从未需要过锁文件。而且我们光是打印两行文本就要引入数百个库,这说明它确实被大规模使用着。
Maven默认不会检查传递依赖的版本冲突。要实现这个功能,你需要用一个难用的插件,而且它产生的错误信息比NPM还糟糕:[链接]。
当两个库引入不同版本时,Maven是怎么解决依赖的?它的做法简直疯狂。[链接]。
千万别天真地以为Maven的依赖解析不是场噩梦(不过我确实喜欢它按创建者命名空间划分包的设计,npm真该借鉴这点)。
作者: hyperpape | 发布于: 2025-08-06 15:59
13. pentamassiv在《我给AI装上四肢后它拒绝了我》中的新评论
大家好,我是这篇博客文章的作者。感谢你分享这篇文章。如果你们有任何问题,欢迎随时提问。也请告诉我文章的写作质量如何,这是我最初写的几篇文章之一,希望能不断改进。
作者: pentamassiv | 发布于: 2025-08-06 07:50
14. pentamassiv在”Ask HN: 你是否后悔过开源某个项目?”中的新评论
我是一个模拟键盘鼠标输入的库的维护者。这个项目不是我创建的,但我接手了维护工作并几乎重写了所有代码。最近发现Anthropic公司正在Claude桌面版中集成这个库,可能是用于某个未发布的”计算机使用”类功能。我注意到他们正好在负责这个实现的团队有个空缺职位,就申请了。几个月后收到了拒绝信,理由是团队没时间面试更多候选人了。代码采用MIT许可证,所以一切都没问题。像Anthropic这样的公司使用我的代码是件好事,但如果能从中获益就更好了。关于这个话题我写了篇更详细的博客:
作者: pentamassiv | 发布于: 2025-08-05 22:59
15. erulabs在”Ask HN: 开源某物后是否曾后悔?”中的新评论
我14岁左右时开源了一个自动配置X11的xrandr脚本。代码写得很烂,有不少bug。我在KDE邮件列表里提到这个项目,结果一位KDE核心贡献者说这代码太丢人了,让我去死。这件事对我打击很大,之后我再也没给KDE或X11贡献过代码,大概花了一年时间才重新燃起编程的热情。
相比之下,我后来开源的其他项目都顺利多了。
作者: erulabs | 发布于: 2025-08-05 22:37
16. wizee在”OpenAI的开源模型”话题下发表新评论
隐私保护(无论是个人还是企业数据)是最主要原因。其他优势还包括:不受限的使用、支持离线运行、开源特性、不用担心优秀模型被下架/停用或改动,以及能自由使用未经审查的模型或微调版本(虽然这个OpenAI模型审查非常严格——“安全版”)。
我对本地视觉模型经验不多,但在文本处理方面,最新的本地模型表现相当出色。我经常使用Qwen 3 Coder 30B-A3B在本地分析代码,效果很好。虽然比不上最新的云端大模型,但根据我的使用体验,它基本能达到去年底最先进的云端模型水平。我还在家用服务器上运行Qwen 3 235B-A22B 2507 Instruct,表现优异,使用感受大致与Claude 4 Sonnet相当(当然在仅配备DDR4内存且无GPU的服务器上运行速度较慢)。
作者: wizee | 发布于: 2025-08-05 22:22
17. cco在”OpenAI的开源模型”中的新评论
我觉得大家都没抓住重点。
gpt-oss:20b可是全球前十的模型(在MMLU基准测试中仅次于Gemini-2.5-Pro),而我刚刚就在去年买的M3芯片Macbook Air上本地运行了它。
我一直在笔记本和手机(Pixel 9 Pro)上测试各种本地模型,原以为还要一两年才能达到这种水平。
但现实是,今天我们就做到了。一个近乎顶尖的模型,仅需耗费微不足道的电费就能在我的笔记本上运行。不需要每月200美元的订阅费,也不会消耗海量资源。
这简直太让人震撼了。
作者: cco | 发布于: 2025-08-05 21:13
18. kridsdale3在”Claude Opus 4.1”中的新评论
根据公历和地球轨道运行轨迹,八月才刚刚开始。
作者: kridsdale3 | 发布于: 2025-08-05 18:26
19. foundry27在”OpenAI的开源模型”话题下的新评论
模型卡片(给对技术细节感兴趣的人):[链接]
我在心里把他们描述的模型架构和主流开源权重模型(Deepseek、Qwen、GLM、Kimi)做了对比。老实说,从技术层面看只能说”还行”:
两个模型都采用标准的分组查询注意力机制(64个查询头,8个KV头)。卡片提到他们沿用了GPT3的老优化方案:在带状窗口(稀疏,128个token)和全密集注意力模式间交替。使用经YaRN扩展的RoPE(实现131K上下文窗口)。所以他们没有采用Deepseek的”秘制”多头潜在注意力,也没有其他针对GQA的改进方案。
两个模型都是标准的MoE架构。120B参数模型(总参数量116.8B,激活参数量5.1B)使用128个专家和Top-4路由。他们采用了某种带门控的SwiGLU激活函数,卡片称其”非传统”是因为涉及截断和某些残差连接。同样没有采用Deepseek的”共享专家”(通用模式)+”路由专家”(专用模式)架构改进,也没有Qwen的负载均衡策略等。
我认为最有趣的是他们的量化方案。他们实现了超过90%模型参数MXFP4格式(4.25比特/参数)量化,让120B模型能塞进单个80GB GPU,这很酷。不过我们还有Unsloth著名的1.58比特量化方案 :)
总之,虽然他们在智能体行为和推理方面的训练确实很出色,但看起来他们把真正的技术进步都”藏着掖着”呢。
作者: foundry27 | 发布于: 2025-08-05 17:57
20. pitpatagain在”Ozempic试验显示抗衰老效果”中的新评论
这项研究专门针对HIV相关脂肪代谢异常患者,这类症状与加速衰老有关。尚不清楚该研究结果对普通人群的意义。
作者: pitpatagain | 发布于: 2025-08-05 17:39