花了两天时间读完HTTP2的RFC,揭开HTTP2的神秘面纱,驱散心中迷雾,它比HTTP1.1,到底改变了什么。
这是一篇什么样的文章
这是一篇化繁为简的文章,只pick HTTP2中最为关键的部分,忽略细节实现部分。毕竟,每个人读一个文档的目的是不一样的。像我只是想从原理上理解,以便之后使用时能够更加顺畅;而如果是为了实现一个支持HTTP2的库,则需要抠细节,当然花费的时间肯定也不一样,那会是一遍一遍又一遍。
同时我也受够了网上花花绿绿的文章,它们,十之八九,乃基于数篇至数百篇咀嚼过的N手知识,稀碎拼凑而成。看完之后,给人似懂非懂,缺斤少两的感觉。当然,并不是在说人家不好,我也没那个资格,深以为,大家写文章、做总结,其受众非我等小明小红小丽,实为作者自己。认知闭合,学习金字塔,是公共的概念,也是大家的需求。写文章,也算是教授给他人的一种方式。
并不是说我这个文章就比别人的好,那也不见得。文章的好坏与否,取决于本身质量、表述方式等诸多因素。我写这篇文章,也更多是给今后的自己看,于其他人,和网上其它千百文章并无二致。大家并不会因为看了它对HTTP2变得更加了解,这不符合正常的学习曲线。
不过,硬要说的话,我还是可以推荐一篇写得好的HTTP2文章的,详尽,且带有实例讲解,文章基于RFC,同时查阅了很多其他资料,可说是长篇佳作。但它也有缺点,即没有重点,或重点过多。比如HTTP2的优势一节,服务端推送、应用层重置连接、优先级设置、流量控制等,未见得是优势,对理解来说并无关键作用。
HTTP2升级了什么
HTTP1.x和HTTP1.1有几个主要的问题
- 对同一地址的多次请求,会创建多个TCP连接。HTTP1.0自不必多说,每个请求就会创建一个连接;HTTP1.1虽有所优化,还引入了pipline技术,但也仅仅是将几个请求合并在一个连接,且pipline技术还会有管线头问题,即响应的顺序必须和请求的顺序一致,如果管线中第一个请求阻塞了,会导致同一管线中其它请求的阻塞,即请求之间互相影响了。
- HTTP请求头多且重复,浪费带宽。
HTTP2的解决方案,也是HTTP2的主要内容,说是所有内容也不为过
- 针对第一个问题,HTTP2提供的解决方案是多路复用,同一地址只会建立一个连接,节省资源;引入Stream和帧,使得不同请求之间完全不干扰,提升传输效率。
- 针对请求头多的问题,HTTP2使用HPACK压缩算法,压缩掉重复的请求头。
- 还有一个额外的优化:服务端推送,它使得服务端可以自动发送预加载资源,而不必客户端主动请求。
先强调几个点
- HTTP2是一个二进制协议,不像HTTP1.x那样是文本协议。
- HTTP2的服务端推送,与WebSocket、SSE等完全不一样,只是为了更快地在浏览器和服务器之间传输数据,我们并不能随意操作。
HTTP2通信过程
在语义上,HTTP2继承了绝大部分HTTP1.1的内容,因此在使用时完全感觉不到,浏览器或者我们HTTP库自动做了升级操作,不信看我们的Ingress访问日志,相当一部分请求已经走的HTTP2协议了。
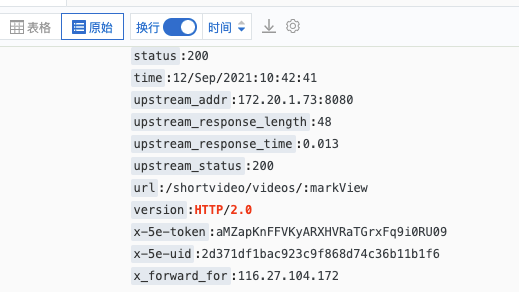
总体来说,一个完整的通信过程包括:协议升级 -> 数据分帧 -> 发送 -> 服务端组装帧 -> 服务端逻辑处理并响应 -> 数据分帧 -> 发送 -> 客户端组装帧 -> 处理响应。
可以看到,相对HTTP1.x,多了两类步骤,其它的和之前的协议一样,怪不得我们感受不到。
- 协议升级
- 数据分帧、合帧等中间操作
协议升级
还记得WebSocket的升级方式吗?是一样的。
这样的请求
1 | GET / HTTP/1.1 |
升级成功就是这样的响应,然后就在同一个TCP连接上快乐地发送数据了
1 | HTTP/1.1 101 Switching Protocols |
请求头说明
- Upgrade:表明升级的目标是HTTP2协议。h2c是HTTP2从非加密通道升级时的标识符;加密通道则为h2
- HTT2-Settings:关于HTTP2传输参数的配置,配置的参数包括请求头索引表大小、并发流的个数等
数据分帧、合帧
HTTP2是二进制帧,而为了兼容当前的HTTP语义,即请求-响应机制,HTTP请求、响应中又包含请求行、头部、body等,这些内容都会被封装成HTTP2的帧进行传输,到远端再重新合并,这里给出一个RFC中对一些请求的分帧示例。

例子中的POST请求,共被分为三帧。
- HEADERS帧:将请求的方法、路径、scheme转换为伪头,封装进一个HEADER帧
- CONTINUATION帧:这是作为上面那个HEADER的续帧,将请求的头部封装了进来
- DATA帧:封装了该请求的请求体中的内容
接收方按照分帧的方式进行合帧,就能得到原始数据
关键点说明
表层看,通信过程就如上面讲的那样,但理解HTTP2的关键,要完全了解帧的概念,它是HTTP2数据传输的最小单位;要了解流的概念,它是实现多路复用的最关键技术;要了解头部压缩,它是实现带宽节省的关键技术。此外,还有两个点我忽略掉了,他们并不会给理解带来任何阻碍:流控和流的优先级
帧
帧在整个协议栈中的位置如下:
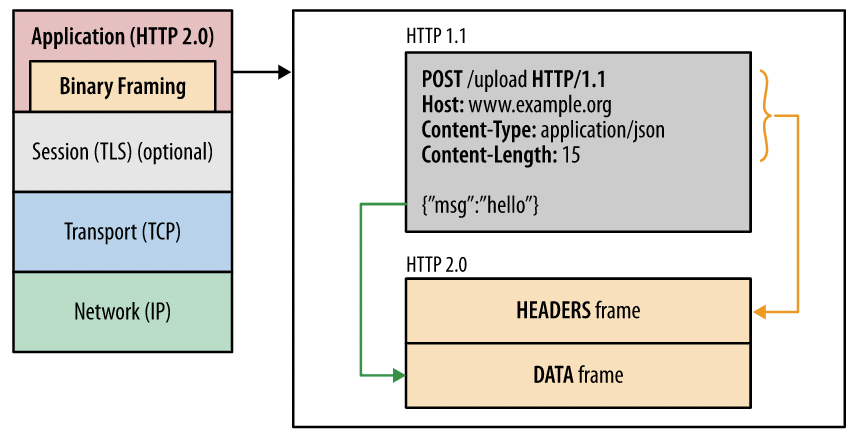
这就是HTTP2的帧结构,其实挺简单

| 字段名 | 字段说明 |
|---|---|
| Length | 帧的载荷长度 |
| Type | 帧类型 |
| Flags | 标记位,不同的帧类型会使用到不同的标记位 |
| Stream ID | 流ID |
帧类型大概有这么多(忽略了流控(WINDOW_UPADTE)和优先级(PRIORITY)两个类型)
| 帧类型 | 说明 |
|---|---|
| DATA | 数据帧 |
| HEADERS | 头部帧,用于开启一个流 |
| CONTINUATION | 作为HEADERS帧的续帧 |
| RST_STREAM | 复位帧,用于中止一个流,当流发生错误时发送。 用它只会中止流,对连接上的其它流没有影响 |
| SETTINGS | 设置帧,用于在数据发送交流通信参数 |
| PUSH_PROMISE | 服务端推送帧,服务端发往客户端,表明服务端将要有数据推送下来,客户端等着 |
| PING | 注意这不是心跳,而是测量一个请求-响应完成时间的帧 |
| GOAWAY | 整个连接关闭前发送的帧,该帧携带了远端处理成功的最后一个流ID,以便接收方做优雅关闭 |
这么多帧,数据相关的帧只有前三种,其它都是控制帧。
多路复用(Stream、Frame)
三张图对比最原始的HTTP请求响应、pipeline、HTTP多路复用的区别。
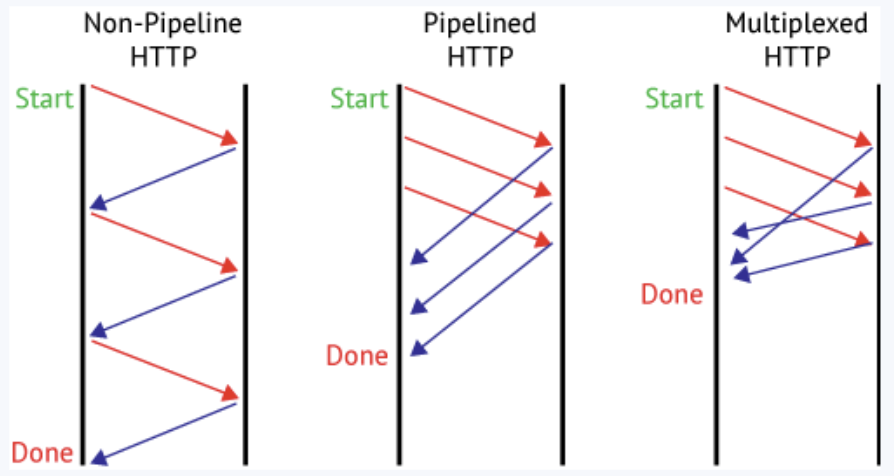
解读
无pipeline时,一个HTTP请求必须等待上一个请求响应完成后才可进行,完全串行
有pipeline时,请求可以不等待响应直接发送了,但是响应的顺序和请求的顺序必须完全一致。如果第一个请求响应很慢,会阻塞其它两个请求。
这个,顶多相当于批量执行。
多路复用时,与pipeline的区别,是响应之间互不干涉,随便怎么发都行。
怎么理解多路复用
多路:其实指的是请求与响应两路;也可以理解为一个请求响应理解为一路,多个请求连接复用一个连接。
复用:即同一个TCP连接,可以同时传输请求与响应的数据,数据之间互不干扰。这在之前可是不行的哦。
如何实现
多路复用,是帧(Frame)和流(Stream)共同作用的结果。
- 帧有两个作用:一是可以携带额外的控制参数,如流ID;二是拆分数据包
- 流则是一个逻辑上的抽象:一个TCP连接上所承载的数据,通过流进行逻辑识别。应用到HTTP语义的协议上,一个请求对应一个流,而TCP连接上胡乱交叉的请求与响应的数据帧才能被正确识别,因为有唯一识别符——流ID嘛
比如下面这个图,如果stream 3这两帧被服务端处理完后,服务端发送响应,只需要将响应帧的流也标识为stream 3,这样,无乱什么时候发过来,客户端都知道这个响应对应的是原来stream 3发出去的那个请求。
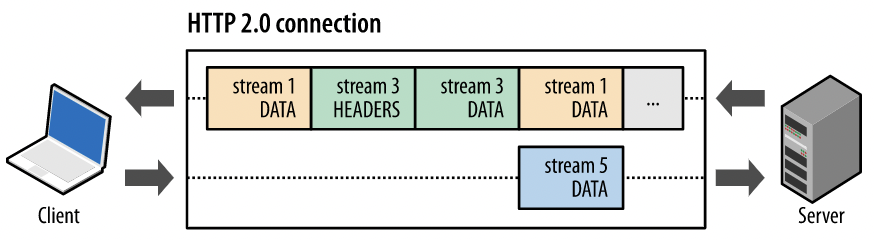
HTTP1.1为什么不做多路复用
这是交付模型的直接结果,HTTP1.x还是直接的请求-响应模型,如果顺序打乱,将无法在茫茫请求中找到将发送的响应到底属于哪个请求,客户端在接收方也无法区分出收到的这个响应到底是哪个请求发送出去的。而HTTP2不一样,每个请求都被对应一个Stream(流),流有ID,逻辑上只要保证流内部的帧顺序不出错即可,至于响应,无论什么时候,我处理完的请求发送回去只要带流ID即可,客户端知道这个流ID对应的请求是谁。
流多说两点
HTTP2中的流,是一个逻辑概念,即拥有连续帧的抽象。关于流,有几个注意事项
- 一个流内部,帧之间的顺序是绝对的,不然收到之后组装不回去,会报错的
- 流可以指定优先级,优先级高的流会被优先处理,这在资源有限时会比较有用
头部编排和压缩
HTTP2的HEADERS帧并不直接对应HTTP1.x语义的头部哦,有没有发现HTTP2并没有为请求行和状态行这些HTTP1.x语义的内容留专门的定义,事实上确实没有,因此在进行HTTP1.x数据传输时,需要先做头部编排。
其中最重要的是将请求行编排为伪头,以冒号开头,具体来说
| 伪头 | 举例 | 说明 |
|---|---|---|
| :method | GET | 方法 |
| :scheme | https | 协议 |
| :host | api.wemore.com | 主机地址 |
| :path | /resource | 资源路径 |
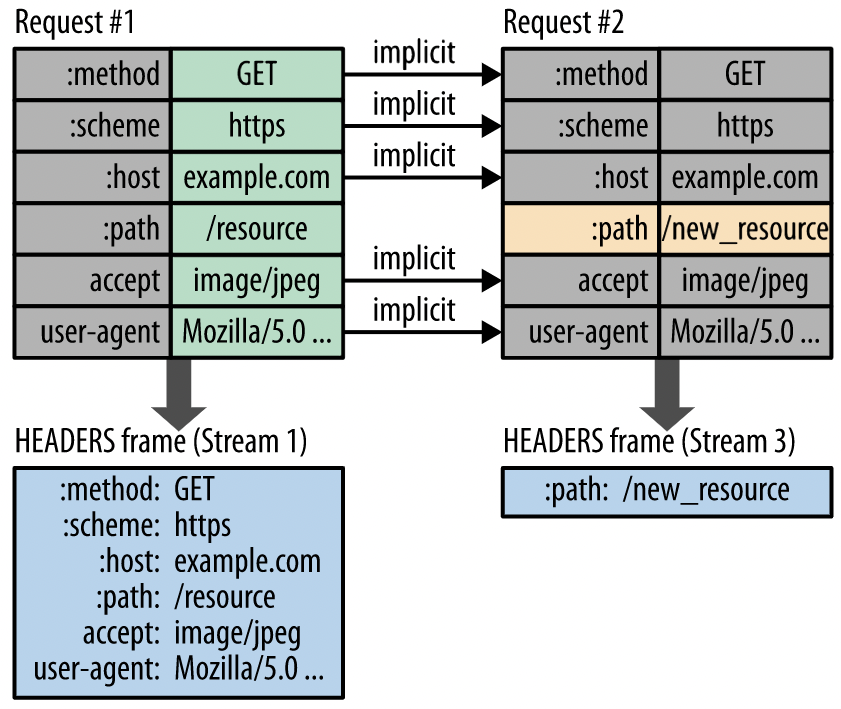
至于压缩,HTTP2采用HPACK压缩算法,即构建一个索引表,将传输过的头部存入表中,下次传输时,如果头部已经在表中,则传索引号即可,否则传输实际请求头。需要注意的是,这个索引表是针对整个连接都有效的,所以能够跨Stream使用。
如下,第一个请求时,传输完整的头部,第二次请求时,仅有一个头部不一样,因此只传输这个头部即可,其它头部传索引(图中没画出来)。
服务端推送
相信我,它并不是你想象的那个样子。
我刚开始想象的样子:有了HTTP2,我们将不再需要WebSocket,因为它是长连接,也是支持服务端主动发送数据。
但我想多了,看这里可以了解到,HTTP2所谓的服务端推送,只是打破了一个请求对应一个响应的语义,只有有限场景能够用到,即服务端知道客户端将要请求什么数据,比如服务端返回一个网页,网页内嵌了很多图片、css、js等静态资源,按照以往的规则,都是要等待客户端发起推送的,但现在不一样,服务端可以告诉客户端:你先等着,我还有数据要发给你。
实现方式
服务端发送PUSH_PROMISE帧,客户端收到之后,不关闭流,而是待机等待。
应用范围
目前还很窄,nginx支持简单的静态资源推送,如下
1 | # 这表明访问index.html时,服务端会主动推送下面这些静态文件 |
其它场景应用也不是很多,主要还是对资源加载的优化,并不像WebSocket那样,完全将客户端-服务端之间数据传输的控制权完全交给用户。
抓个包看一下
主要抓包有三种方式,网上搜一搜就知道了
- chrome:并不能通过控制台看到HTTP2的通信过程,而是要通过特殊的工具:chrome://net-internals/#http2
- nghttp2:一个开源命令行工具,能够抓取一个网站的HTTP2完整的通信过程
- wireshark:TCP抓包工具,但是要抓HTTP2包需要先配置秘钥,配置方式和Charles等不一样:Charles是伪造TLS证书,wireshark是窃取TLS握手成功后交换的对称秘钥
我用nghttp2抓了一个nghttp2.org网站的包,可以看到大致流程
- 建立连接,协议升级,https内标识:h2
- 发送SETTINGS帧,设置的内容有
- 客户端流最大并发度:100
- 客户端的流控窗口初始值:65535
- 发送PRIORITY帧,分别设置了流3、5、7、9、11、13的优先级(weight),依赖关系(dep_stream_id),流优先级及依赖关系请自行参考RFC
- 发送HEADERS帧,对GET https://nghttp2.org进行访问
- 收到服务端发来的SETTINGS帧,设置的内容有
- 服务端流最大并发度:100
- 服务端流控窗口初始值:1048576
- 请求头索引表大小:8192
- 收到服务端对之前SETTINGS帧的ACK响应(这是ACK可靠传输的机制,参见RFC)
- 收到PUSH_PROMISE帧,服务端即将推送screen.css帧给我们
- 发送对之前服务端SETTINGS帧的ACK响应
- 收到DATA帧,即传输内容
- 处理处理完收到的内容后,本地处理能力有所变化,发送WINDOW_UPDATE帧给客户端,通知对方调整流控窗口
- 收到带有END_STREAM标记的DATA帧,表明数据传输完成
- 发送GOAWAY帧,告诉客户端连接即将关闭,同时告知上一个成功的流ID为2,且没有任何错误,方便服务端进行优雅地关闭。
1 | zouguodong@zouguodongdeMacBook-Pro ~ % nghttp -nv https://nghttp2.org/ |
请注意
HTTP2是一个二进制协议,Stream、分帧等行为,并不具有更多语义上的意义(尽管帧类型规定是那些,但帧类型是可扩展的,协议也留出了扩展空间),也就是说,它能被用在其它应用场景下,比如GRPC