本文目的是让读者对namespace和cgroup有具象的认识,并不会深入。当然,由于笔者Linux知识有限,也无法深入。
“容器是一个与宿主机系统共享内核但与操作系统中的其它进程资源隔离的执行环境”,这是理解容器技术的核心。这句话可以翻译的更直白一点:容器是一个环境,该环境内运行的进程和操作系统中的其它进程是一样的,享受同样的硬件资源,唯一的差别是,该环境内的进程看不到其它进程的存在,操作也不会相互影响,即所谓的隔离;多个容器的运行,就是在各自的隔离环境中运行各自的进程。
容器只是一个抽象的逻辑概念,具有上述特性的就可以叫做容器,这些特性的实现,依赖于Linux操作系统提供的namespace和cgroup。namespace提供了资源隔离,保证不同namespace之前的资源操作不相互影响;cgroup提供资源限制,保障一个group内的资源使用不会超过预设。
namespace
资源隔离,一个完整的运行环境,即一个所谓的容器,需要隔离的资源包括哪些呢?大致有如下几类
- 隔离文件系统:文件操作相互不影响
- 隔离网络:容器需要有独立的IP、端口、路由规则等
- 隔离主机名:容器需要在网络中标识自己
- 隔离进程间通信:消息队列、共享内存等
- 隔离用户权限:容器内应该有完整的用户权限
- 隔离PID:容器内的PID与宿主机的PID需要隔离
针对每一类,Linux在namespace上都提供了隔离支持,即有六种不同类型的namespace,每种对应不同的资源。
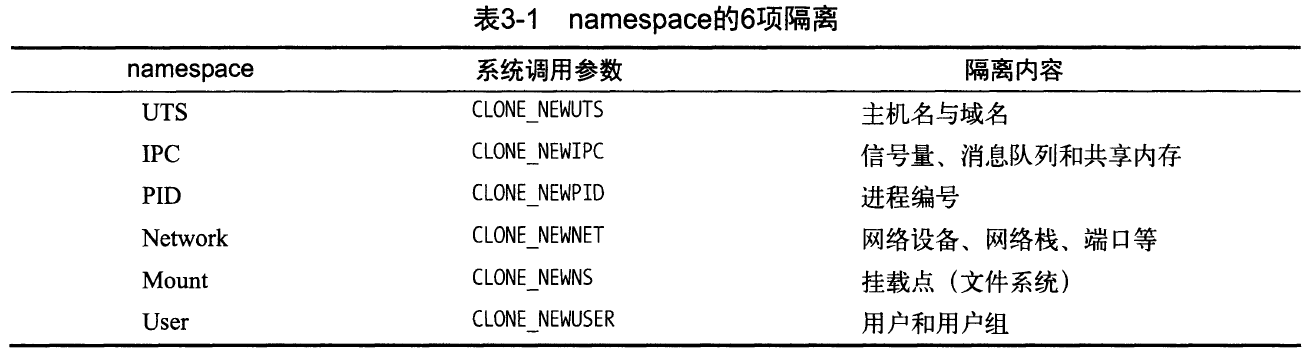
namespace存在的目的,就是为了实现“轻量级虚拟化服务”(即容器),这是内核级别的支持。处于同一个namespace下的进程,相互可感知,可见;处于不同namespace下的进程,完全看不到对方的存在,就像是在一个独立的操作系统中一样。
启动一个容器,只需要在一个全新的namespace中创建该容器的进程即可,对此,Linux通过API的方式提供支持
- clone():创建一个独立的namespace的进程
- setns():将当前进程加入一个已经存在的namespace
- unshare():在原先进程上进行资源隔离,即原先进程还是处于原来的namespace,但是其创建出来的子进程在新的namespace中
为此,我们可以写一个简单的代码来体验和验证资源隔离,有如下c代码
1 | // namespace.c |
在linux下编译并执行(注意:需要root用于才能执行成功)
1 | # 编译并执行 |
可以看到,在新的进程中
- 用户名由root变成了nobody,用户已经隔离
- hostname变成了我们自己设置的NewNamespace,说明主机名进行了隔离
- 进程号为1,说明PID进行了隔离。关于PID=1在Linux中非常重要,称作init进程,有特权,起特殊作用
其它几种资源隔离也有相应的验证方式,但并不妨碍理解,这里就不深究。不过由此,我们已经能够想见,类似docker、containerd、runc这类的容器实现,都是基于类似如上调用,在隔离的namespace中创建进程。
cgroup
namespace负责了资源隔离,但不同namespace中的资源不能无限消耗,否则很容易因为容器内程序的bug或恶意攻击导致资源耗尽,威胁其它容器的进程。于是需要有资源限制,这需要cgroup,cgroup不仅能做资源限制,还能记录资源使用统计(这个功能可以用来做。。。云服务收费),还能做任务挂起、恢复等操作。
cgroup中有这么几个概念:
task:任务,标识一个进程
cgroup:控制组,表示按某种资源控制标准划分的任务组,可以包含一个或多个子系统
subsystem:子系统,即资源调度控制器,如CPU子系统、内存子系统。详细来说,docker使用了如下几种
- blkio:为块设备设定输入输出限制,如磁盘
- cpu:对cpu的调度
- cpuacct:自动生成cgroup中任务对CPU资源使用情况的报告
- cpuset:可为cgroup中的任务分配独立的cpu和内存
- devices:开启或关闭cgroup中任务对设备的访问
- freezer:挂起或恢复cgroup中的任务
- memory:设定cgroup中任务对内存使用量的限定,并生成他们对内存资源的使用报告
- perf_event:使cgroup中的任务可以进行统一的性能测试
- net_cls:它使用等级标识符标记网络数据包,以允许Linux流量控制程序识别从具体cgroup中生成的数据包
hierarchy:层级关系,由一系列cgroup按照树状结构组成
我们可以查看当前系统有多少种子系统
1 | root@10-9-175-15:/home/ubuntu/docker-learn# mount -t cgroup |
可以看到,每个子系统在文件系统上对应了一个文件夹,下面我们看看一个运行中的docker容器的cgroup长什么样:
查看到本地运行的docker容器,可以看到一个id为ee4a4efd4a5b的容器
1 | root@10-9-175-15:/home/ubuntu/docker-learn# docker ps |
查看其对应的cpu限制配置,在/sys/fs/cgroup/cpu/docker/ee4a4efd4a5b2a9a6e8154bc4336bf2a7f1528205e9f53adb8443868adad7eeb中
1 | root@10-9-175-15:/sys/fs/cgroup/cpu/docker/ee4a4efd4a5b2a9a6e8154bc4336bf2a7f1528205e9f53adb8443868adad7eeb# ls |
可以看到有很多文件,每个文件对应一项cpu配置或监控值。注意tasks文件,是受到cgroup管理的任务,随便查看一个比如cpu.cfs_quota_us,即cpu配额。默认为-1,表示不限制
1 | root@10-9-175-15:/sys/fs/cgroup/cpu/docker/ee4a4efd4a5b2a9a6e8154bc4336bf2a7f1528205e9f53adb8443868adad7eeb# cat cpu.cfs_quota_us |
当然我们自己也能将自己的进程添加cgroup进行限制,方法是在对应的子系统文件中创建文件夹,系统会自动在文件夹下添加上述配置文件,我们向tasks添加任务,并向指定文件中添加配置即可。
结尾
可以看到,有了namespace和cgroup,在创建进程时和平时创建进程没什么两样,这样得到的容器是非常轻量的。容器和进程创建,可以类比携程和方法调用,都是利用普通的方式达成轻量快速的目标。
话说回来。每当看这些内容,都会感觉到自己Linux知识的匮乏,因此Linux的学习,还是很有必要的。其中最主要的,还是进程管理方式、Linux网络、文件系统等。